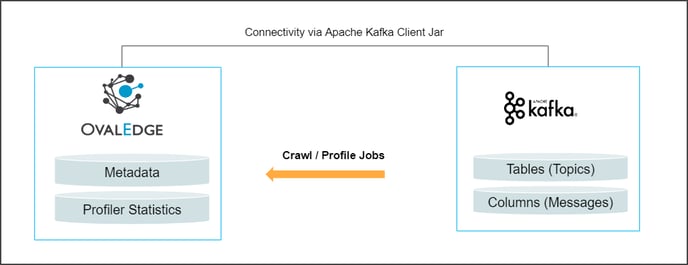
Kafka is an open-source component that works as a centralized data hub for simple data integration between databases, key-value stores, search indexes, and file systems.
OvalEdge uses an Apache Kafka Client Jar to connect to the data source, which allows you to crawl and profile the Topics and Messages.
Connector Capabilities
The connector capabilities are shown below:
Crawling
|
Features |
Supported Objects |
Remarks |
|---|---|---|
|
Crawling |
Tables |
- |
Profiling
|
Features |
Details |
Remarks |
|
Table Profiling |
Min, Max, Null count, distinct, and top 50 values |
- |
|
Column Profiling |
Min, Max, Null count, distinct, top 50 values |
- |
|
Sample Profiling |
Supported |
Profiling is supported for Avro and JSON schema types, and not supported for protobuf. |
Notes:
Topics in Kafka are represented as tables.
Messages in Kafka are represented as columns and crawled during sample profiling.
Prerequisite(s)
The following are the prerequisites to establish a connection to Apache kafka.
- Kafka Client Jar
- Service Account Permissions
- Configure environment variables (Optional)
Kafka Client Jar
OvalEdge uses Kafka Client Jar to connect to Apache kafka.
|
Jars |
Version |
Details |
|
Apache Kafka Jars |
5.5.1-css |
org.apache.kafka.clients |
|
Apache Kafka Jars |
3.2.0 |
org. apache.kafka |
|
Apache Kafka Jars |
5.5.1 |
io. confluent. Kafka-schema-registry-client |
Service Account with Minimum Read Permissions
The following are the minimum privileges required for a service account to crawl and profile the data.
|
Operation |
Minimum Access Permissions |
|
Connection Validation |
When a Schema registry URL is given, the Schame Registry user and password validation should be valid. If the Boostrap server and JAAS.Config file is valid, and the path of this JAAS.The config should be valid. |
|
Crawling |
Read access to the given cluster. |
|
Profiling |
Read access to the topic messages(Tables). |
Configure environment variables (Optional)
This section describes the settings or instructions that you should be aware of prior to establishing a connection. If your environments have been configured, skip this step.
Configure Environment Names
The Environment Names allow you to select the environment configured for the specific connector from the dropdown list in the Add Connector pop-up window.
You might want to consider crawling the same schema in both stage and production environments for consistency. The typical environments for crawling are PROD, STG, or Temporary, and may also include QA or other environments. Additionally, crawling a temporary environment can be useful for schema comparisons, which can later be deleted, especially during application upgrade assistance.
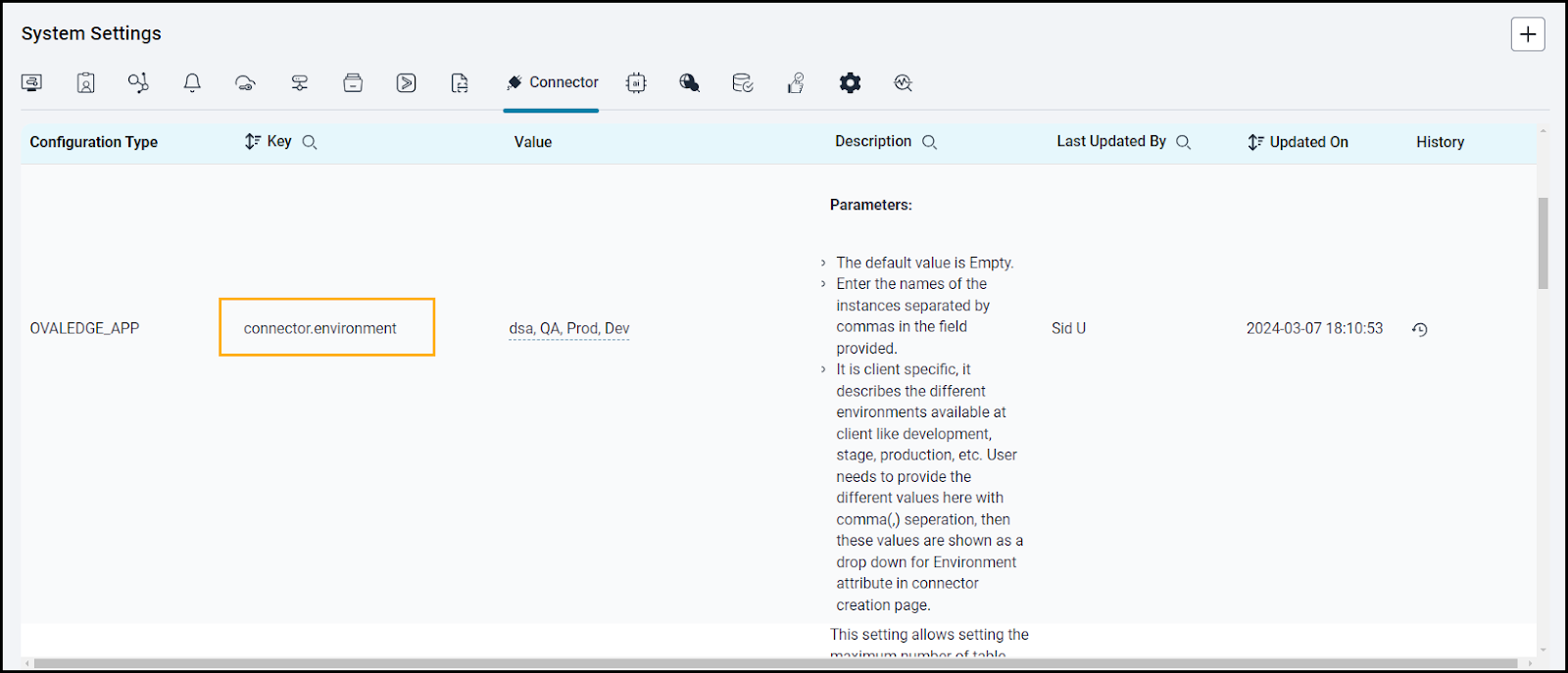
Steps to Configure the Environment
- Navigate to Administration > System Settings.
- Select the Connector tab.
- Find the Key name “connector.environment”.
- Enter the desired environment values (PROD, STG) in the value column.
- Click ✔ to save.
Establish a connection.
To connect to Apache kafka using the OvalEdge application, complete the following steps:
- Log in to the OvalEdge application
- Navigate to Administration > Connectors module.
- Click on the + icon, and the Add Connector with Search Connector pop-up window is displayed.
- Select the connection type as Apache kafka. The Add Connector with Apache kafka details pop-up window is displayed.
|
Fields |
Details |
|
Connector Type |
This field allows you to select the connector from the drop-down list provided. By default, 'Kafka' is displayed as the selected connector type. |
|
Credential Manager* |
Select the option from the drop-down menu where you want to save your credentials: OE Credential Manager: The Kafka connection is configured with the basic Username and Password of the service account in real time when OvalEdge establishes a connection to the Kafka database. Users need to add the credentials manually if the OE Credential Manager option is selected. HashiCorp: The credentials are stored in the HashiCorp database server and fetched from HashiCorp to OvalEdge. AWS Secrets Manager: The credentials are stored in the AWS Secrets Manager database server and fetched from the AWS Secrets Manager to OvalEdge. For more information on Azure Key Vault, refer to Azure Key Vault. For more information on Credential Manager, refer to Credential Manager. |
|
License Ad-Ons |
All the connectors will have a Base Connector License by default that allows you to crawl and profile to obtain the metadata and statistical information from a datasource. OvalEdge supports various License Add-Ons based on the connector’s functionality requirements.
|
|
Connector Environment |
The Connector Environment drop-down list allows you to select the environment configured for the connector from the drop-down list. For example, you can select PROD or STG (based on the items configured in the OvalEdge configuration for the connector environment). The purpose of the environment field is to help you identify which connector is connecting what type of system environment (Production, STG, or QA). Note: The Configuring Environment Variables section explains setting up environment variables. |
|
Connection Name* |
Enter the name of the connection, the connection name specified in the Connection Name textbox will be a reference to the Apache Kafka connection in the OvalEdge application. Example: Apache kafka Connection1 |
|
Broker URL* |
To get Broker URL from the Kafka Server, go to the Section: Additional Information Database instance URL (on-premises/cloud-based) |
|
Cluster Name* |
Enter cluster name. Example: demo-kafka-cluster-12938 For more information, refer to the Section: Additional Information |
|
Cluster Authentication Typle |
It supports the following types of Authentication:
If you select Confluent Without Auth, enter Registry URL. The other authentication details are explained here. |
| Registry URL |
Enter the Schema Registry service URL with port. Example: http://schema-registry.example.com:8081 |
|
Default Governance Roles* |
You can select a specific user or a team from the governance roles (Steward, Custodian, Owner) that get assigned for managing the data asset. Note: The dropdown list displays all the configurable roles (single user or a team) as per the configurations made in the OvalEdge Security | Governance Roles section. |
|
Admin Roles |
Select the required admin roles for this connector.
|
|
Select Bridge |
With the OvalEdge Bridge component, any cloud-hosted server can connect with any on-premise or public cloud data sources without modifying firewall rules. A bridge provides real-time control that makes it easy to manage data movement between any source and destination. For more information, refer to Bridge Overview. For more information, refer to Bridge Overview |
Additional Information on Authentication Types:
Below are the additional fields required to establish the connection for ‘JAAS Config Path’ and ‘App Key/Secret Key Credentials’.
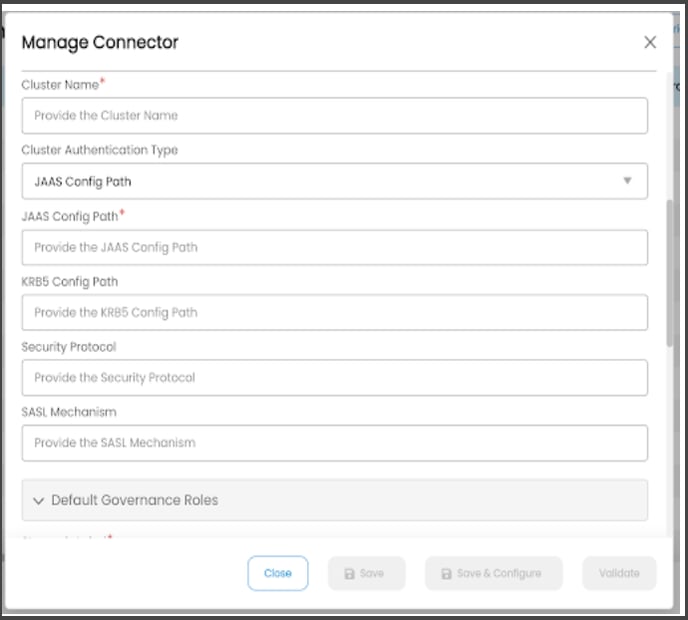
Cluster Authentication Type as “JAAS Config Path”:
The Java Authentication and Authorization Service (JAAS) login configuration file contains one or more entries that specify the authentication mechanism to be used by applications.
Enter the following details to establish a Kafka connection using the JAAS Config path authentication.
|
Field Name |
Details |
|
|
Cluster Authentication Type* |
Select Cluster Authentication Type as “JAAS Config Path” from the drop-down list. |
|
|
JAAS Config Path* |
This file includes a login module to authenticate the cluster(username and password) |
|
|
Security Protocol |
SASL_SSL |
|
|
SASL Mechanism |
PLAIN |
|
|
Registry URL |
Enter the Schema Registry service URL with port. Example: http://schema-registry.example.com:8081 |
|
|
Schema Registry User |
User account or API key that has access permissions to interact with the Schema Registry service. |
|
|
Schema Registry Password |
Secret key of the above user account or API key. |
|
|
KRB5 Config Path |
It indicates the location of the Kerberos configuration file within the path of the OvalEdge running instance. |
|
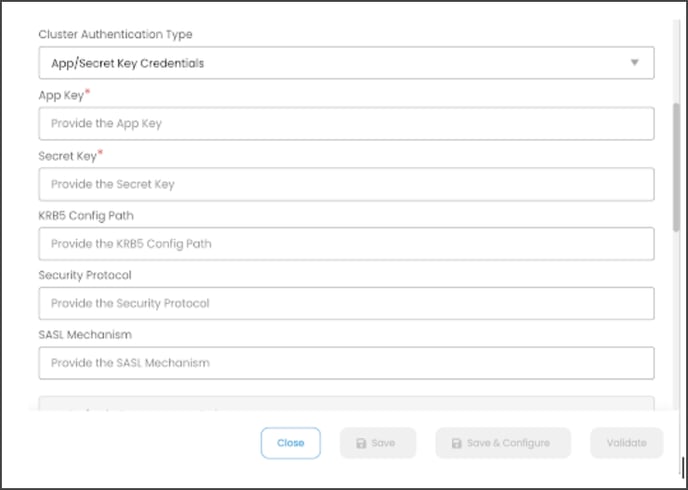
Cluster Authentication Type as “App Key/Secret Key Credentials”
API Keys are used to control the access of a data source. Each API Key consists of a key and a secret.
Enter the following details to establish a Kafka connection using the App/Secret Key Credentials authentication.
|
Field Name |
Details |
|
Cluster Authentication Type* |
Select Cluster Authentication Type as “App Key/Secret Key Credentials” from the drop-down list. |
|
App Key |
Enter the cluster API Key. For detailed steps, click here. |
|
Secret Key |
Enter the cluster API Secret For detailed steps, click here. |
|
Security Protocol |
SASL_SSL |
|
SASL Mechanism |
PLAIN |
|
Registry URL |
Enter the Schema Registry service URL with port. Example: http://schema-registry.example.com:8081 |
|
Schema Registry User |
User account or API key that has access permissions to interact with the Schema Registry service. |
|
Schema Registry Password |
Secret key of the above user account or API key. |
|
KRB5 Config Path |
It indicates the location of the Kerberos configuration file within the path of the OvalEdge running instance. |
5. Click on the Validate button to validate the connection details.
6. Click on the Save button to save the connection. Alternatively, you can also directly click on the button that displays the Connection Settings pop-up window to configure the settings for the selected Connector. The Save & Configure button is displayed only for the Connectors for which the settings configuration is required.
Note: * (asterisk) indicates the mandatory field required to create a connection. Once the connection is validated and saved, it will be displayed on the Connectors home page.
Note: You can either save the connection details first, or you can validate the connection first and then save it.
Connection Validation Errors
|
S.No |
Error Message(s) |
Description |
|
1 |
Failed to construct Kafka consumer |
If any one of the parameters from connector arguments is missing or given invalid, it will throw this error |
|
2 |
Unable to obtain the krb5 or keytab |
If we didn’t configure the keytab in VM arguments or the details which exist in the key tab are wrong it will throw the message |
|
3 |
Timeout error |
Connection timeout while connecting to schema registry |
|
4 |
401 error |
Unauthorized error due to the invalid details of schema registry |
Note: If you have any issues creating a connection, please contact your assigned OvalEdge Customer Success Management (CSM) team.
Connector Settings
Once the connection is established successfully, various settings are provided to fetch and analyze the information from the data source.
The connection settings include Crawler, Profiler, Access Instruction, Business Glossary Settings, and Others.
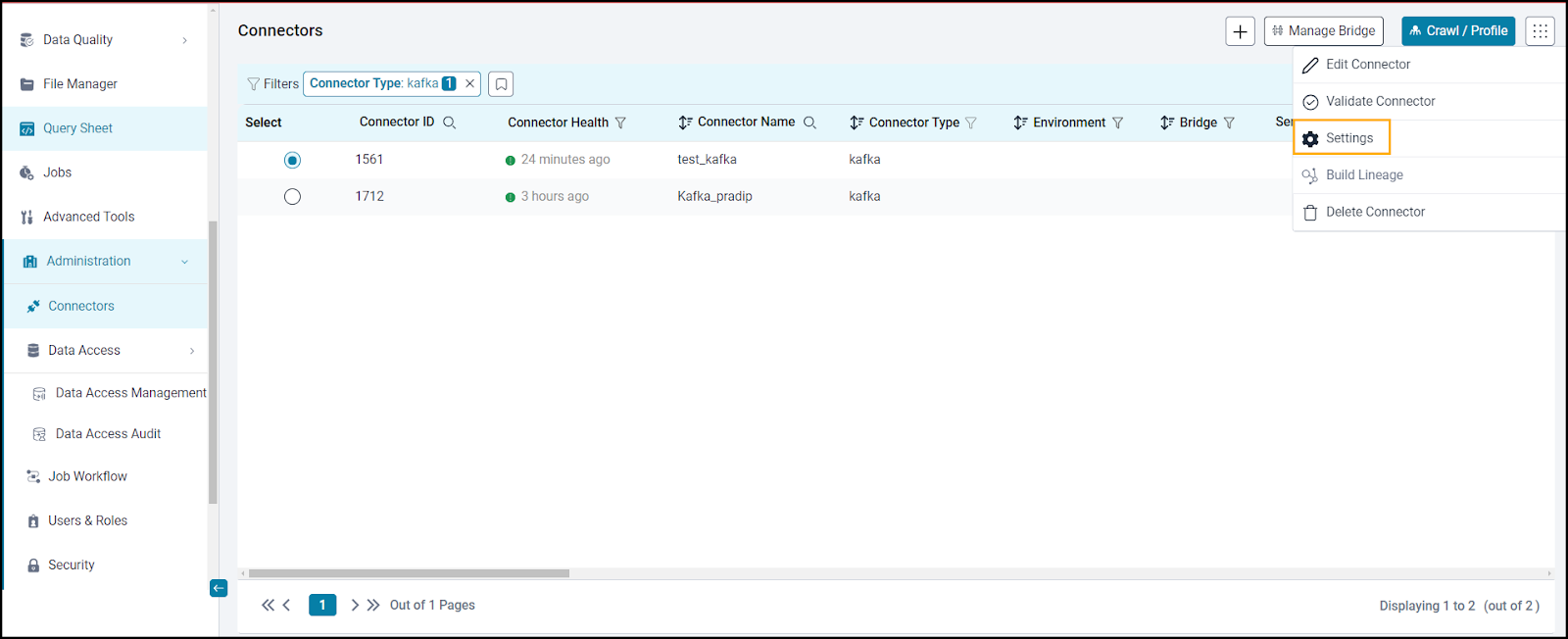
To view the Connector Settings page,
- Go to the Connectors page.
- From the 9- dots, select the Settings option.
- This will display the Connector Settings page, where you can view all the connector settings.
- When you have finished making your desired changes, click on Save Changes. All setting changes will be applied to the metadata.
The following is a list of connection settings and their corresponding descriptions.
|
Connection Settings |
Description |
|---|---|
|
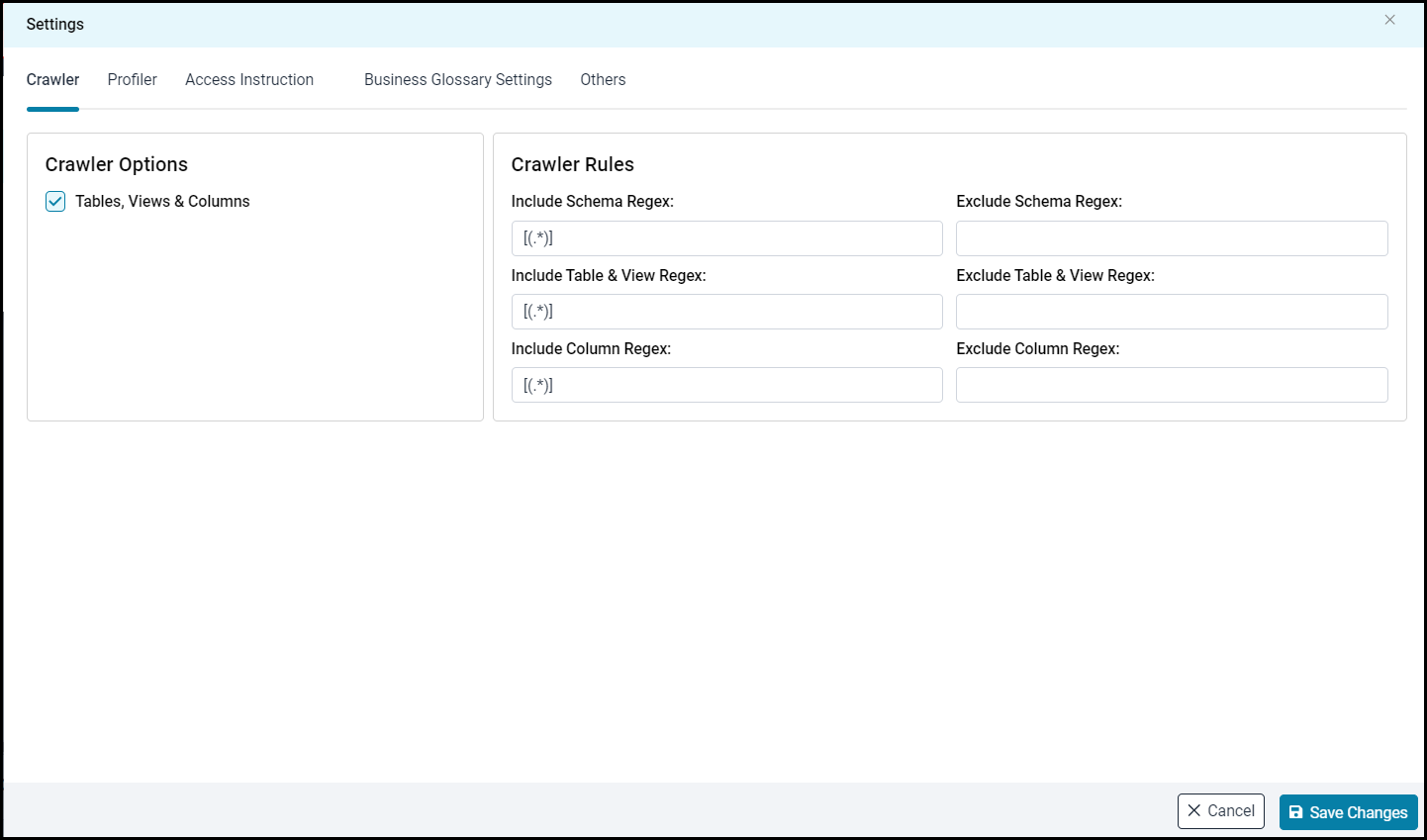
Crawler |
Crawler settings are configured to connect to a data source and collect and catalog all the data elements in metadata. |
|
Profiler |
Profiler settings govern the gathering of statistics and informative summaries about the connected data source(s). These statistics can help assess the quality of data sources before using them for analysis. Profiling is always optional; crawling can be run without profiling. |
|
Access Instruction |
Access Instruction allows the data owner to instruct others on using the objects in the application. |
|
Business Glossary Settings |
The Business Glossary Settings provide flexibility and control over how users view and manage term association within a business glossary at the connector level. |
|
Others |
The Send Metadata Changes Notifications option is used to set the change notification about the metadata changes of the data objects.
|
For more information, refer to the Connector Settings.
Crawling of Schema(s)
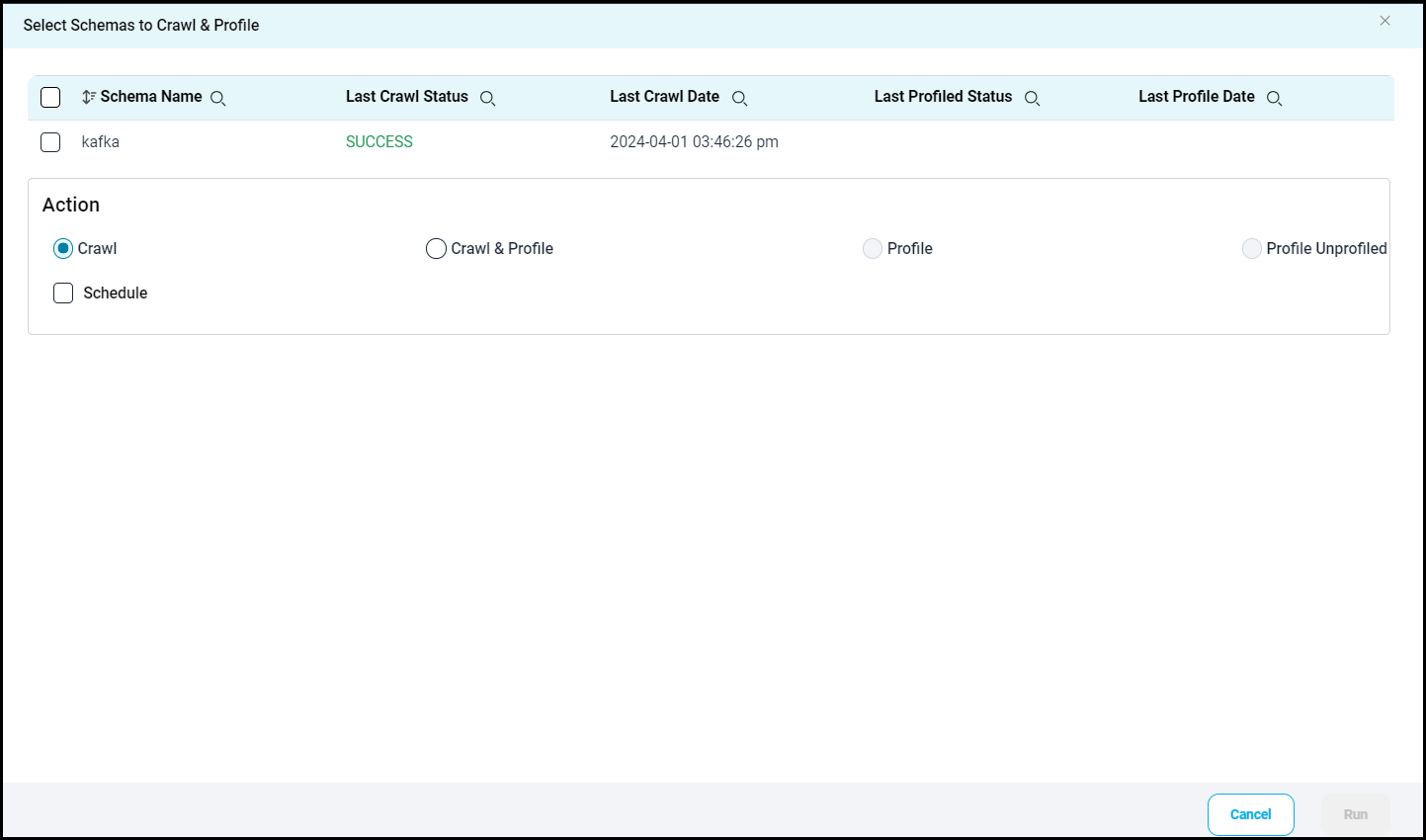
You can use the Crawl/Profile option, which allows you to select the specific schemas for the following operations: crawl, profile, crawl & profile, or profile unprofiled. For any scheduled crawlers and profilers, the defined run date and time are displayed to set.- Navigate to the Connectors page, and click on the Crawl/Profile option.
Select Schemas to Crawl and Profile pop-up window is displayed. - Select the required Schema(s).
- The list of actions below is displayed in the Action section.
- Crawl: This allows the selected schema(s) metadata to be crawled.
- Crawl & Profile: This allows the metadata of the selected schema(s) and profiles of the sample data to be crawled.
- Profile: This allows the collection of table column statistics.
- Profile Unprofiled: This allows data that has not been profiled to be profiled.
- Schedule: Connectors can also be scheduled in advance to run crawling and/or profiling at prescribed times and selected intervals.
Note: For more information on Scheduling, refer to Scheduling Connector.
- Click on the Run button that gathers all metadata from the connected source into OvalEdge Data Catalog.
Note: For more information on Scheduling, refer to Scheduling Connector
Additional Information
This section provides details about generating a few connection parameters and the available authentication details.
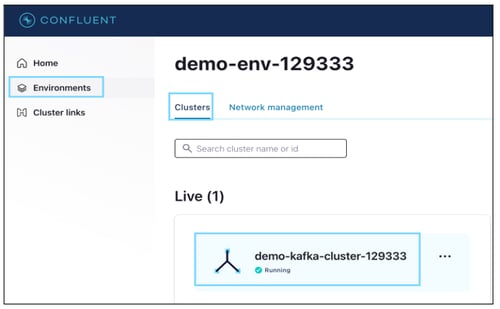
Cluster Name
A Kafka cluster is a system that consists of several Brokers, Topics, and Partitions for both. Connecting to any broker means connecting to the entire cluster.
Step(s):
- Log in to Apache Kafka.
- Click on the 'Environment', and
- Select the Cluster name (demo-Kafka-cluster-12933).
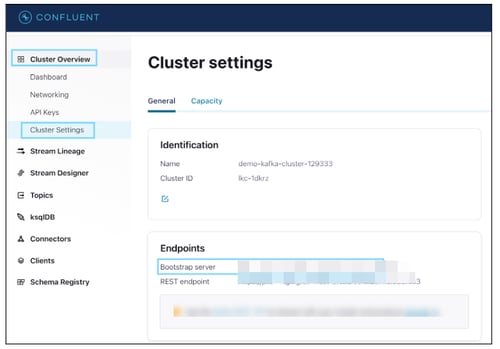
Broker URL (Boostrap Server)
In Apache Kafka, the server is referred to as a broker, and it is responsible for managing the storage and exchange of messages between producers and consumers. Each broker in the cluster stores a subset of the topic partitions.
Step(s):
- You can navigate to Cluster Overview and click on Cluster Settings.
- In the Endpoints section, select Bootstrap server URL information.
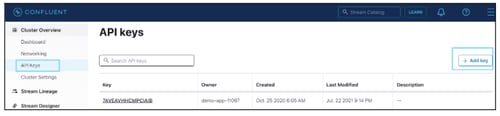
APP Key and Secret Key
You can navigate to the respective Cluster name, then click on API Keys.
You can select an existing API Key or generate a new service account API Key.
Steps to generate a new API key
- Navigate to Cluster Overview > API Keys.
- Click on + Add Key to generate a new API Key.
- Select Granular access as the scope for API Key to managing it as Service Account.
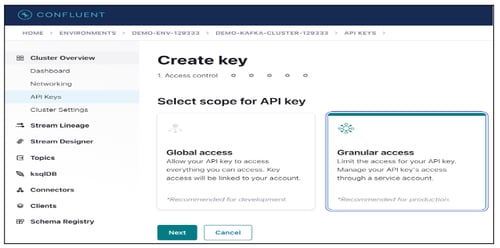
- Click on the Next button.
- Enter the New service account name and Description.
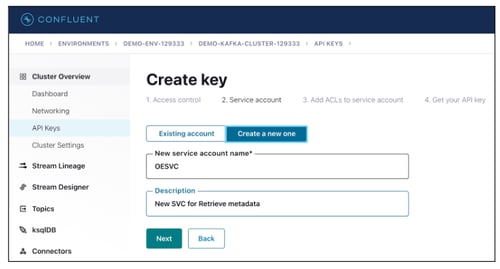
- Click on the Next button.
- Select appropriate permission at Cluster level and Topic level permission.
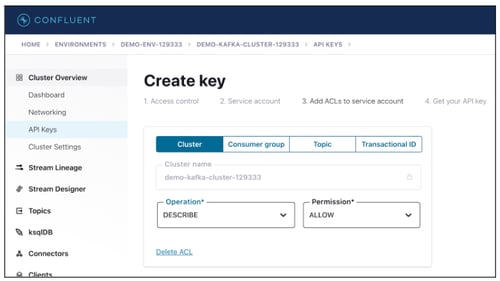
- Click on the Next button
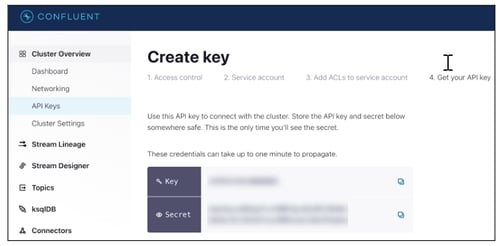
- Copy the Key and Secret information.
Configuring Cluster Authentication Type
JAAS Config path: The Java Authentication and Authorization Service (JAAS) login configuration file contains one or more entries that specify authentication technologies to be used by applications.
App/Secret Key Credential:
API Keys are used to controlling the access of a datasource. Each API Key consists of a key and a secret.
Copyright © 2024, OvalEdge LLC, Peachtree Corners, GA, USA.