
Tableau is an interactive data visualization reporting tool. Tableau Gateway is software that accesses data in an on-premises/cloud, allowing multiple users to connect with multiple data sources.
OvalEdge requires a service account and uses APIs to connect to the data source. It allows users to crawl data objects (Reports, Report Columns, etc.) and build Lineage.
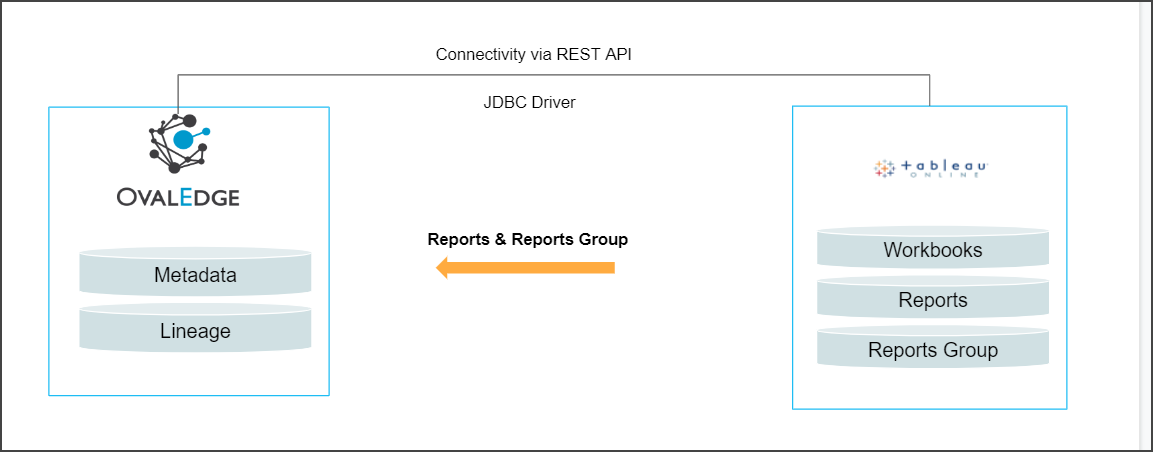
Connector Capabilities
The following is the list of objects supported by the Tableau On-Premise connector.
| Functionality | Supported Data Objects |
| Crawling | Report Group, Reports |
| Lineage Building | Report Group, Reports/ Workbooks, Data Sources |
Note: Profiling is not supported.
Prerequisites
The following are the prerequisites required for establishing a connection between the connector and the OvalEdge application.
- API Details
- Set up a Service account with proper permissions to the Rest APIs of Tableau
- Configure environment variables (Optional)
API Details
The API used by the connector is given below:
|
Tableau Server version |
REST API version |
| 8.3, 9.0 | 2.0 |
| 9.0.1 and later versions of 9.0 | 2.0 |
| 9.1, 9.2 | 2.0 |
| 9.2 | 2.1 |
| 9.3 | 2.2 |
| 10.1 | 2.4 |
| 10.2 | 2.5 |
| 10.3 | 2.6 |
| 10.4 | 2.7 |
| 10.5 | 2.8 |
| 2018.1 | 3.0 |
| 2018.2 | 3.1 |
| 2018.3 | 3.2 |
| 2019.1 | 3.3 |
| 2019.2 | 3.4 |
| 2019.3 | 3.5 |
| 2019.4 | 3.6 |
| 2020.1 | 3.7 |
| 2020.2 | 3.8 |
| 2020.3 | 3.9 |
| 2020.4 | 3.10 |
| 2021.1 | 3.11 |
| 2021.2 | 3.12 |
| 2021.3 | 3.13 |
| 2021.4 | 3.14 |
| 2022.1 | 3.15 |
| 2022.2 | 3.16 |
| 2022.3 | 3.17 |
| 2022.4 | 3.18 |
Service Account with Minimum Permissions
The minimum requirement to access the Tableau On-Premise is to be the site administrator or site role of Explorer.
| Operation | Minimum Access Permission |
| Connector Validation | Tableau Administrator or Site Role |
| Crawler | Tableau Administrator or Site Role |
| Lineage | Tableau Administrator or Site Role |
| Delta Crawl | Workbook, Data Source Revision Information |
Establish Environment Variables (Optional)
This section describes the settings or instructions that you should be aware of prior to establishing a connection. If your environments have been configured, skip this step.
Configure Environment Names
The Environment Names allow you to select the environment configured for the specific connector from the dropdown list in the Add Connector pop-up window.You might want to consider crawling the same schema in both stage and production environments for consistency. The typical environments for crawling are PROD, STG, or Temporary, and may also include QA or other environments. Additionally, crawling a temporary environment can be useful for schema comparisons, which can later be deleted, especially during application upgrade assistance.
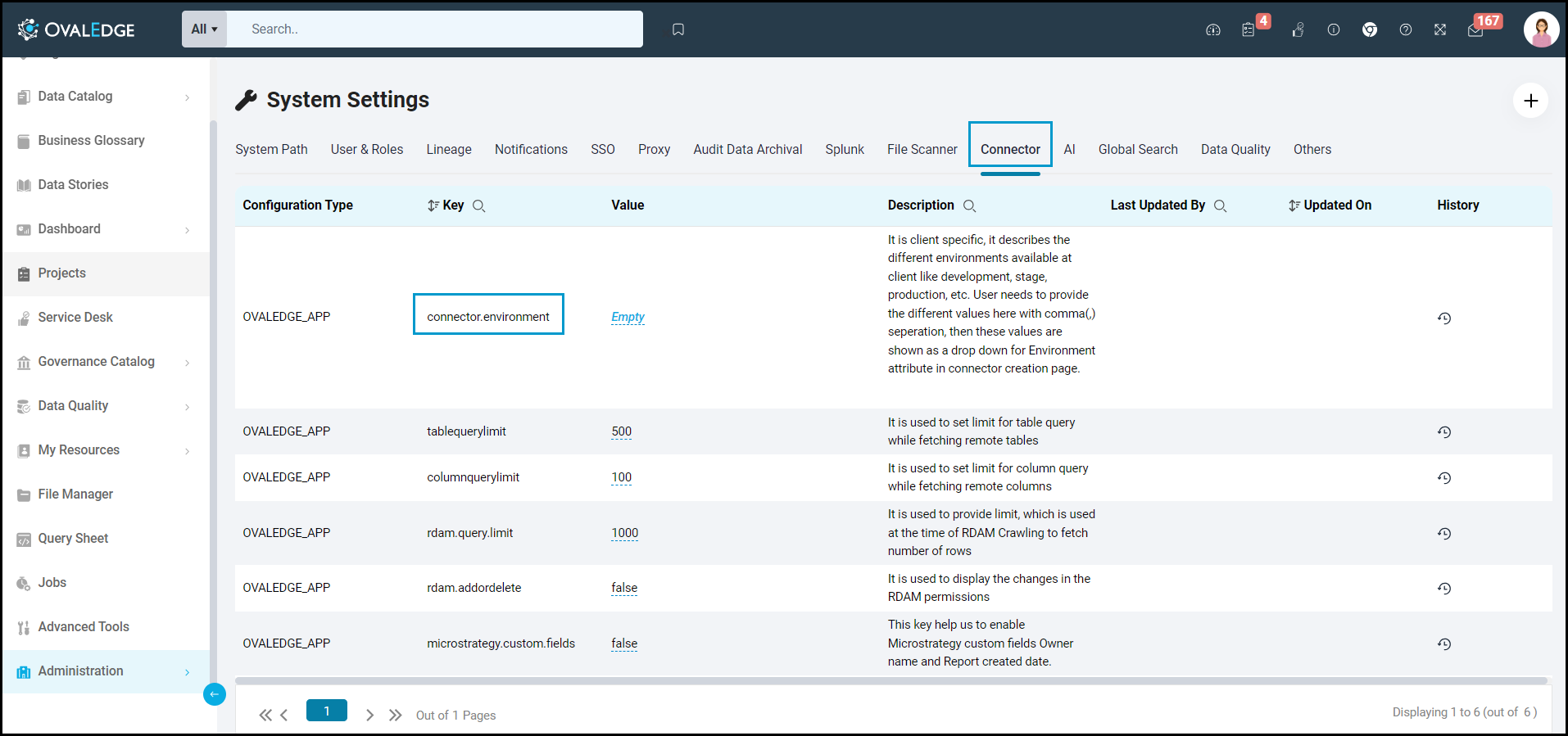
Steps to Configure the Environment
- Navigate to Administration > System Settings.
- Select the Connector tab.
- Find the Key name “connector.environment”.

- Enter the desired environment values (PROD, STG) in the value column.
- Click ✔ to save.
Establish a Connection
To establish a Tableau Connection,
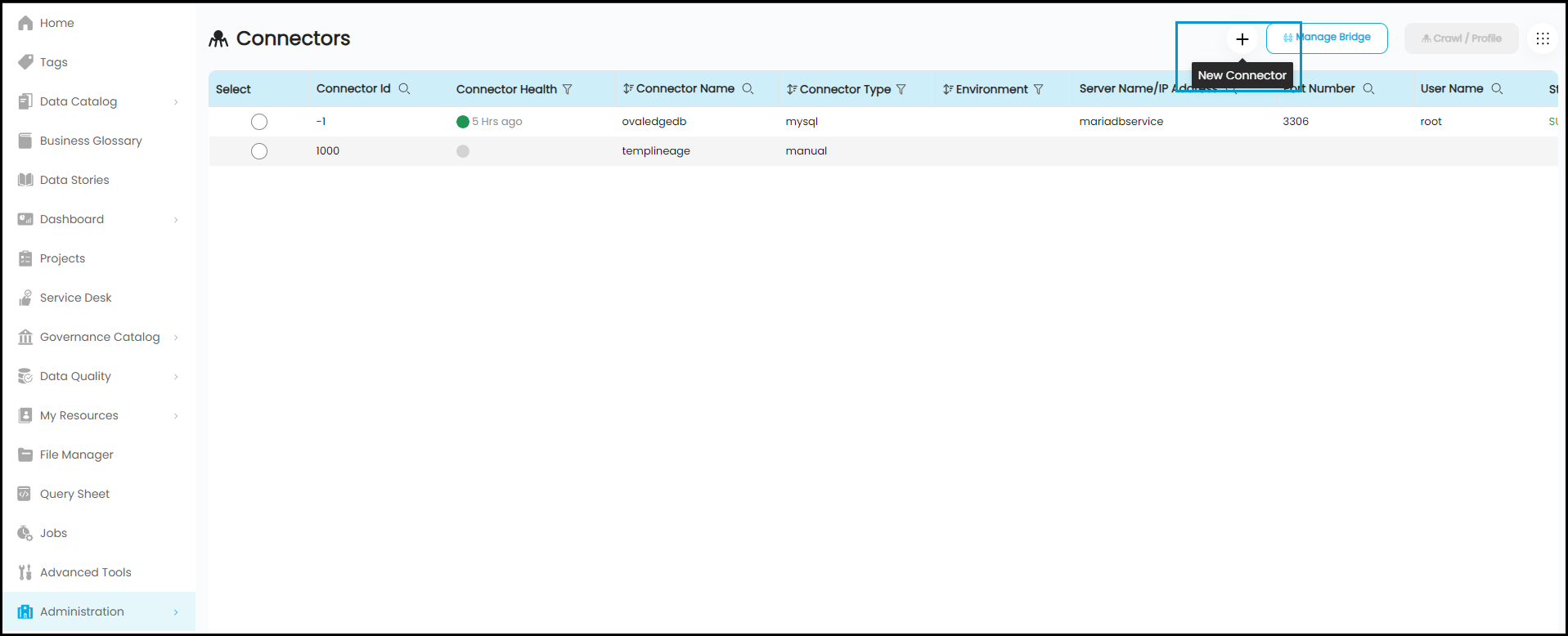
- Log in to the OvalEdge application
- In the left menu, click on the Administration module name, and click on the Connectors sub-module name. The Connectors Information page is displayed.
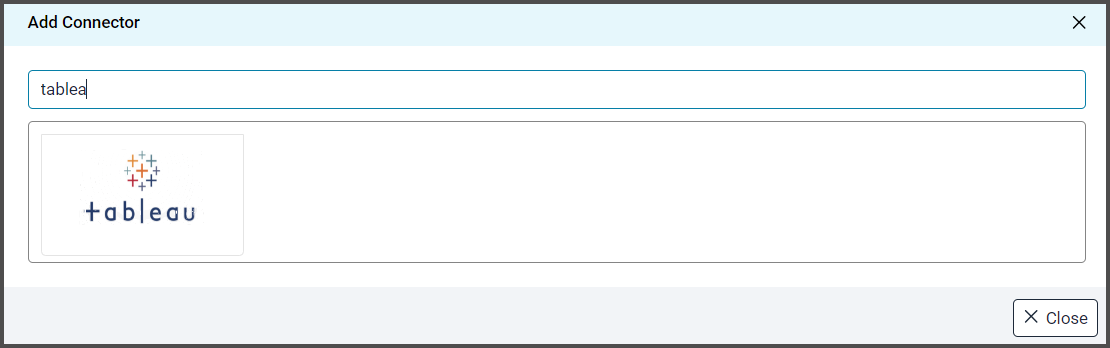
- Click on + New Connector. The Add Connector pop-up window is displayed.

- Add Connector pop-up window is displayed where you can search for the Tableau connector.

- The Add Connector with Connector Type specific details pop-up window is displayed. Enter the relevant information to configure the Tableau connection.
Note: The asterisk (*) denotes mandatory fields for establishing a connection.
Parameters
Details Connector Type
The selected connection type ‘Tableau On-Premise’ is displayed by default. If required, the dropdown menu allows you to change the connector type. Credential Manager*
Select the option from the drop-down menu to indicate where you want to save your credentials:
OE Credential Manager: Tableau connection is configured with the basic Username and Password of the service account in real-time when OvalEdge establishes a connection to the Tableau database. Users must manually add the credentials if the OE Credential Manager option is selected.
HashiCorp: The credentials are stored in the HashiCorp database server and fetched from HashiCorp to OvalEdge.
AWS Secrets Manager: The credentials are stored in the AWS Secrets Manager database server; OvalEdge fetches the credentials from the AWS Secrets Manager.
For more information on Azure Key Vault, refer to Azure Key Vault
For more information on Credential Manager, refer to Credential ManagerLicense Add-Ons
All the connectors will have a Base Connector License by default that allows you to crawl and profile to obtain the metadata and statistical information from a datasource.
OvalEdge supports various License Add-Ons based on the connector’s functionality requirements.
- Select the Auto Lineage Add-On license that enables the automatic construction of the Lineage of data objects for a connector with the Lineage feature.
- Select the Data Quality Add-On license to identify, report, and resolve the data quality issues for a connector whose data supports data quality, using DQ Rules/functions, Anomaly detection, Reports, and more.
- Select the Data Access Add-On license that will enforce connector access via OvalEdge with Remote Data Access Management (RDAM) feature enabled.
Connector Name*
Enter a connection name for the Tableau On-Premise database. You can specify a reference name to easily identify the Tableau On-Premise database connection in OvalEdge.
Example: tableauonprem_db
Connector Environment
The environment dropdown menu allows you to select the environment configured for the connector from the dropdown list. For example, PROD, or STG (based on the configured items in the OvalEdge configuration for the connector.environment).
The purpose of the environment field is to help you identify which connector is connecting what type of system environment (Production, STG, or QA).Note: The steps to set up environment variables in explained in the prerequisite section.
Host Name*
This is the Hostname or IP address of the Tableau Server.
Is Token Based Auth(Y/N)*
Tableau consists of two types of Authentication:
- Tableau On-Premise: User will select ‘N’ from the dropdown and provide the Service Account username and password.
- Tableau Online: The user will select ‘Y’ from the dropdown and provide the token details. This is Token-based authentication.
Note: Token-based authentication is not required for Tableau On-Premise. For the Tableau Server, users can select “N”.
Token Based Auth as "N" - On-Prem
Username* A username is required to connect to the Tableau server. Enter the Service Account Name established to access the Tableau environment.
Note: Sometimes, this field is automatically filled by the web browser with the current OvalEdge user login. Please enter the Tableau Service Account name.
Password*
Enter the password to access the Tableau Service account.
Content URL
To enter the name of the Tableau On-Premise site.
Reference document: https://help.tableau.com/current/api/rest_api/en-us/REST/rest_api_concepts_auth.htm
Tableau API Version*
The Tableau versions supported by OvalEdge are 2.8, 3.0, and 3.1.
Note: For every Tableau version there should be a specific API version that will support it.
Alias Host Name
Enter Alias Host Name
Connection string* Set the Connection string toggle button to automatic to get the details automatically from the credentials provided.
https://{server}/api/2.6
Token Based Auth as "Y" - Cloud
Token Name* Enter Token Name.
Token*
Enter Token.
For more details click here
Content URL
Enter the name of the Tableau site.
Reference document: https://help.tableau.com/current/api/rest_api/en-us/REST/rest_api_concepts_auth.htm
Tableau API Version*
The Tableau versions supported by OvalEdge are 2.8, 3.0, and 3.1.
Note: For every Tableau version there should be a specific API version that will support it.
Alias Host Name
Enter Alias Host Name
Connection string* Set the Connection string toggle button to automatic to get the details automatically from the credentials provided.
https://{server}/api/2.6
Default Governance Roles* You can select a specific user or a team from the governance roles (Steward, Custodian, Owner) that get assigned for managing the data asset.
The dropdown list displays all the configurable roles (single user or a team) as per the configurations made in the OvalEdge Security | Governance Roles section.
Admin Roles*
Select the required admin roles for this connector.
- To add Integration Admin Roles, search for or select one or more roles from the Integration Admin options, and then click on the Apply button.
The responsibility of the Integration Admin includes configuring crawling and profiling settings for the connector, as well as deleting connectors, schemas, or data objects. - To add Security and Governance Admin roles, search for or select one or more roles from the list, and then click on the Apply button.
The security and Governance Admin is responsible for:- Configure role permissions for the connector and its associated data objects.
- Add admins to set permissions for roles on the connector and its associated data objects.
- Update governance roles.
- Create custom fields.
- Develop Service Request templates for the connector.
- Create Approval workflows for the templates.
No of Archive Objects*
It is the number of last modifications made in the metadata data of a dataset at Remote/source. By default, the number of archive objects is set to disable mode.
Click on the Archive toggle button and enter the number of objects you wish to archive.For example, the connection is crawled if updates the count is 4. It will provide the last 4 changes that occurred in the remote/source of the connector. You can observe these changes in the ‘version’ column of the ‘Metadata Changes’ module.
Select Bridge* With the OvalEdge Bridge component, any cloud-hosted server can connect with any on-premise or public cloud data sources without modifying firewall rules. A bridge provides real-time control that makes it easy to manage data movement between any source and destination.
For more information, refer to Bridge Overview.
- After filling in all the connection details, select the appropriate button based on your preferences.
- Validate: Click on the Validate button to verify the connection details. This ensures that the provided information is accurate and enables successful connection establishment.
- Save: Click on the Save button to store the connection details. Once saved, the connection will be added to the Connectors home page for easy access.
- Save & Configure: For certain Connectors that require additional configuration settings, click on the Save & Configure button. This will open the Connection Settings pop-up window, allowing you to configure the necessary settings before saving the connection.
- Once the connection is validated and saved, it will be displayed on the Connectors home page.
Connection Validation Errors
| S.No. | Error Messages(s) |
Descriptions |
| 1 | Signing Error- Error signing in to Tableau Server | In case of an Invalid Username/ Password. |
| 2 | Can't log in, Tableau version: is not support | In case of an incorrect Api version. |
| 3 | Error while getting sites | In case the user doesn't have proper permissions to get the sites. |
| 4 | Error while retrieving Workbooks of Tableau | In case the user doesn't have proper permissions to get workbooks. |
Note: If you have any issues creating a connection, please contact your assigned OvalEdge Customer Success Management (CSM) team.
Connector Settings
Once the connection is established successfully, various settings are provided to retrieve and display the information from the data source.
To view the Connector Settings page,
- Go to the Connectors page.
- From the nine dots, select the Settings option.

- The Connector Settings page is displayed where you can view all the connector setting options.
Click Save Changes. All the settings will be applied on the metadata.
The following is a list of connection settings along with their corresponding descriptions:
| Connection Setting | Description |
| Crawler |
Crawler settings are configured to connect to a data source and collect and catalog all the data elements in the form of metadata. |
| Lineage |
The lineage settings allow you to configure multiple dialects (by Selecting Source Server Type for lineage) and connection priority lists to pick the tables to build lineage. |
| Business Glossary Settings |
The Business Glossary setting provides flexibility and control over how they view and manage term association within the context of a business glossary at the connector level. |
| Access Instruction | Access Instruction allows the data owner to instruct other users on using the objects in the application. |
| Others |
The Send Metadata Changes Notifications option is used to set the change notification about the metadata changes of the data objects.
Context URL: The OvalEdge Browser Extension supports the Context URL functionality. The Context Id helps you to catalog reports from the source reports database. When the Context Id is entered for a specific Report Connector Type > Crawler settings, the OvalEdge application plugin bridges the OvalEdge application and Source Report Database to view the Certification status or Endorsement Rating applied to the Report using the OvalEdge application. |
Note: For more information, refer to the Connector Settings.
The Crawling of Schema(s)
The user can use the Crawl/Profile option, which allows the user to select the specific schemas for the following operations: crawl, profile, crawl & profile, or profile unprofiled. For any scheduled crawlers and profilers, the defined run date and time are displayed to set.
- Navigate to the Connectors page, and click Crawl/Profile option.
- Select the required Schema(s).
- Click on the Run button that gathers all metadata from the connected source into OvalEdge Data Catalog.
Note: For more information on Scheduling, refer to Scheduling Connector
Additional Information
Generating Token-Based Authentication
Tableau SSO Authentication: The Tableau server is enabled with SSO or SAML integration, Rest API will not support it. Instead of that, we need to generate PAT (Personal Access Token) for that user.
The following are the steps to generate PAT (Personal Access Token):
- Login to Tableau Online Server and navigate to the My Account Settings.


- In the My Account Settings page, click on the Settings tab and enter the Token Name in the Personal Access Tokens field.
- Once after providing the Token Name the Create new token button gets enabled and clicks on the Create new token button, a pop-up window with the secret token is displayed.

- Click on the Copy to clipboard button and navigate to the OvalEdge application Tableau Add Connection page and provide the password and select Is Token Based Auth(Y/N) option as ‘Y’.
Troubleshooting Tableau Authentication
In case, if the authentication fails, we can troubleshoot Authentication using curl from the VM.

<tsRequest>
<credentials personalAccessTokenName="kavyagv" personalAccessTokenSecret="X3d/mUyURfomNvNcQ==:EKqhHRq9qfYe4Otn3DlNkMtJI" >
<site contentUrl="ovaledgetestonline" />
</credentials>
</tsRequest>
Save the above Request to an XML file, say signin.xml.
Now, run the below curl command. With this, we can change the request and try different scenarios instead of going for a new build with changes or additional logs.
curl https://prod-apnortheast-a.online.tableau.com/api/3.9/auth/signin -X POST -d @signin.xml

Similar Requests can be executed for other Tableau operations as well.
Copyright © 2024, OvalEdge LLC, Peachtree Corners GA USA