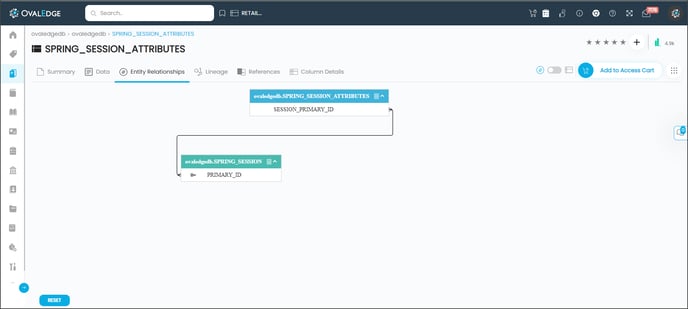
To get relationships, we need to crawl the schema through crawler settings by check-in the Relationship box, then we can see the PK (primary key) & FK (foreign key) relations in ER (Entity Relationship) diagrams and tabular view.
After Crawling & Profiling the Particular Schema, select the table in which you want to see the relationships, then click on the Entity-Relationships tab.
How are ER diagrams generated (table level)?
An Entity-relationship displays the complete logical relationship between a Table and other Tables in a database. Entity-Relationships are calculated based on Primary Key - Foreign Key relationships i.e. the tables with matching column data.
In OvalEdge, the Entity-Relationship diagram is displayed at Table level with clear detailing shown between a Table and other Tables Columns involved in the relationship using flowcharts i.e. Rectangles and connecting lines as links between them.
The ER Diagrams of the table can be viewed in both the Graphical View and also Tabular View. If there are more than five relationships, then a tabular view is used to represent them. Relationships with fewer than five connections are shown in graphical view.
Importance of Entity Relationships
Some of the key advantages of using Entity Relationship are listed below:
- It displays the primary and foreign key relationships, if any exist.
- It helps to identify connections between tables and table columns that are logically related to each other.
- It helps to refine table structures, maintain data integrity, accuracy and minimize redundant data.
- It helps to analyze the database to find and resolve the problems in logic or deployment.
- Easy to implement security methods.
Building Relationships
Here is the list of different ways that help build Relationships in the application:
|
Relationships |
Algorithm Type |
|
Relationships defined at Source |
|
|
Crawler Settings > select Relationship checkbox |
PK-FK relationships captured from the remote server during the crawling stage. |
|
Advanced Jobs |
|
|
Discover Primary and Foreign key Recommendations |
Primary Key & Foreign Key |
|
Discover relationships automatically |
Column Values - Match Count, Base Count, Unique Match Count. |
|
Get Relationships with Column Names |
Column Name |
|
Others |
|
|
Manually |
Adjusting relationships manually. Entity Relationships > Tabular View > Adjust Relationships & Calculate Relationships |
|
Query Parsing |
The Queries built using JOIN conditions are picked as relations. |
|
Pattern Relationships |
Using Pattern identifying algorithms and adding pattern relationships. |
Understanding Primary Key & Foreign Key
A Primary Key is a column in a Table that contains unique values for each row. You can think of the primary key as your Social Security number, which is unique and identifies you even if other people share your Name or Address.
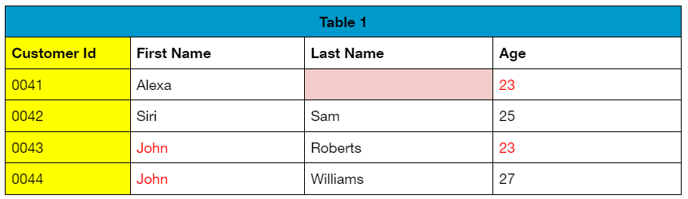
A Table’s primary key must be unique and cannot be empty or null. To calculate Primary Key, Row count = Distinct count.
For Example, in the table below, the Customer Id has unique or distinct values without any duplicates or null values, while the First Name, Last Name, and Age columns have duplicate and null values. In fact, in this table Customer Id is the only column that could be used as the Primary Key.
Foreign Key
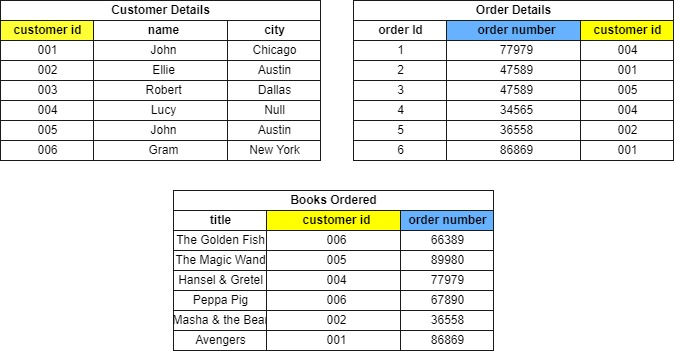
A Foreign Key is a column (or set of columns) in a table that has the same set of values as in the Primary key. It links and points to a column with the same data. Notice that the customer id column values in the Order Details table point to the customer id values in the Customer Details table.
- The customer id column in the Customer Details Table is the Primary Key.
- The customer Id column in the Order Details table is the Foreign Key.
- The customer id column in the Books Ordered tables is another Foreign key identified.
- The order number column in the Order Details table has references with the order number column in the Books Ordered table.
The Primary Key and Foreign key thus helps understand the relationships between Tables where the primary key is used as a reference or unique identifier to match Tables containing the same data. An entity (Table) can typically have just one primary key and several relationships with different foreign keys linked with different tables/columns in the database.
Column Relationship (column)
Table relationships are based on the columns in each table that contain the same data. Relationships between tables tell you how much of the data from a foreign key column can be seen in the related primary key column and vice versa.
In OvalEdge, you can create, edit, and delete a column relationship manually.
Edit Relationship
To create/ delete a relationship in the relationship window,
- Select a column from a primary table and click the Relationship tab to display the relationship window.
- Select the database, schema, table, and column name of the secondary table to create a new relationship to the base table and click "Done" to add the new relationship.
To delete a relationship, click the options button and choose the "Delete Relationship" option.
Once a manual relationship is established, the next step is to Calculate the strength of the relationships between these columns.
Pattern Relationship
Pattern deduction is one of the key aspects of a data catalog tool. It can facilitate discovering the relationship between data points and understand the data better. It can also help identify data assets that have a strong relationship that can further be used in various predictive analytic algorithms.
In OvalEdge, to identify such data objects, we have included a pattern match algorithm that will compute a pattern score. There might be several patterns that exist in column data.
Example: A column named credit card number might have a pattern as DDDD-DDDD-DDDD as well as DDDD-DDD-DDDD.
Whenever a similar pattern match is reported, the object is listed and the pattern Match score is computed and displayed. The pattern match score is a percentage score between 0-100 that calculates the similarity between two table-column values. The scores are calculated as a weighted average of top 50 values.
Pattern match score of each compared column wrt base column =
(Count of rows that has matching patterns to the base column* 50 ) / row count of secondary table
Example: Assume a secondary table has 909 row count. If there are 122 rows containing pattern DDDDD, Pattern match score=122*50/909
If the Pattern match score is higher, it means more data patterns are matching between the compared data objects and better will be the chance of correlation.
When do you see pattern matches?
In OvalEdge, you can generate patterns only between the profiled/analyzed data objects. To generate the patterned relationship, the objects listed should be minimum sample profiled.
In OvalEdge we represent the
- Numeric patterns with “D”
- Uppercase letters with “U”
- Lowercase letters with “L”
Adding patterns to column relationship
Once you identify the data objects with a high pattern match score, you can add it to the column relationship, to find how strong or similar the objects are related.
To add a data object to the Relationship,
In Data Catalog >>Table Column, select a table column and click the pattern relationship tab. All the objects with matching patterns are displayed.
To add a column to the relationship tab, select an object, and click the + icon. The selected object is added to the relationship tab.
Refer to Calculating the relationship between columns to know how to calculate the compared column strength.
Deleting the Added Patterns
To delete the added patterns from the Relationship tab, navigate to the column and the relationship tab and select a column from the list. To delete a relationship, click options and select "Delete Relationship".
The patterns can also be deleted from the Entity relationship tab (tabular view).
Advanced Jobs used to build relationships
1. Get relationships with Column names
This advanced job builds relationships for tables/ columns with identical column names using the Connector ID, Schema ID, Column name, and schema name and on the table catalog, you can view the relationship between the table columns.
Input
- Crawler Id/ Database Name, Schema Id/Name, and Recalculate Relationships(True/False).
- This advanced job groups all the columns with names matched and having id as a substring in its name in the given schema and builds relations among those columns and the related tables.
- If Recalculate Relationships is:
- TRUE: then this job calculates scores for all the identified relationships again without checking whether scores are already calculated or not.
- FALSE: then this job calculates scores for the identified relationships which do not have scores before.
This job starts calculating scores after building all relationships.
2. Discover relationships automatically
This job gets all columns from the given schema tables and takes the top values of each column and compares them with other column top values and if any top value is matched, it builds relationships between those two tables.
Input
- Connector ID / Name.
- Schema IDs / Names can be given with comma(,) separated. It is optional.
- Build relationships across the schemas(true /false).
By default, it is considered false. (If we give it true it will take across the schema. If you keep empty it is default taken as false).
3. Discover primary and foreign key recommendations auto
It is used to discover all the Primary and Foreign Keys using the formula 'Row Count of a table = Distinct count of a table column.'
To discover the Primary and Foreign Keys, the advanced job first verifies the Row count of the Table, and then the unique values are identified and computed.
On the data column table column summary, you can view the primary key and foreign key information.
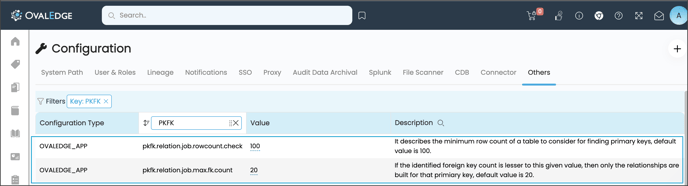
Prior to executing the advanced job, it is essential to verify and adjust the values of the Configuration Keys "pkfk.relation.job.rowcount.check" and "pkfk.relation.job.max.fk.count" to ensure they are set correctly. By default, these values are displayed as 100 and 20, as shown in the below screenshot.
Input
- Connector ID/ Name.
- Schema IDs/ Names can be given with comma(,) separated. It is optional.
- Build relationships across the schemas(true /false).
- Delete existing relationships (true/false)
By default, it is considered false.
If the attribute is set to true and if any schemas are specified, the job deletes the relationships from such schemas. If no schemas are specified, it deletes the relationships of all the schemas of the given connector. It deletes the relationships built via this job only, it doesn't touch the other way of relationships. If you keep empty it is taken as false.
Note:
- If schema IDs are provided as input, this relationship job fetches all primary key columns under the given schema tables where the respective table row count is greater than 100 and the column distinct count is equal to the table row count.
- If schema IDs are not provided as input, then the job of this relationship fetches all primary key columns under the available connections on the connected database where the respective tables row count is greater than 100 and the column distinct count is equal to the table row count.
Now taking these primary columns as a base, for each primary key column we compare the top 50 values of other columns, if any one top value is matched then we build relationships between those two columns.
Conditions
- Schemas must be profiled before running this job.
- Only the columns of tables having
- row_count > 100 and
- table row count = column distinct count is considered as primary key columns.
The difference identified between the 'Discover Relationships Automatically' and 'Discover Primary and Foreign key relationships auto' jobs is that the schemas must be profiled before running 'Project Level Relationships Building'. Both these jobs work on Top value comparison of columns.
4. Project level Relationships Building
The purpose of this advanced job is to build project level relationships.
Input
1. Connector ID/ Database name.
2. Schema IDs/ Names can be given with comma(,) separated. It is optional.
To build project level relationships, we verify whether all the tables added to the project are already fully profiled or not, if not, we initialize profiling jobs for the tables which were not fully profiled. Then once the profiling is done, based on the top 50 values of these table columns we build relationships between columns.
We then calculate relationship scores directly by running a query if both the tables are from the same connection (It is an exact calculation), if not from the same connection we do calculate the top 50 values (It is an approximate calculation).
Need to give project name and schema IDs Before running advanced job need that schemas should be profiled.
Copyright © 2023, OvalEdge LLC, Peachtree Corners GA US