Overview
Data lineage refers to the end-to-end traceability, from the data’s origin or source through all the different transformations, processing steps, and usages, up to its final destination or target. It is the documentation and visualization of the data flow, showing how data moves and evolves within an organization's data ecosystem.
Data lineage is crucial for several reasons:
- Data Quality: It helps ensure data accuracy and reliability by identifying where the data comes from and how it has been modified along the way. Understanding the lineage can assist in identifying any potential data quality issues and rectifying them.
- Compliance and Governance: Data lineage is essential for meeting regulatory compliance requirements. It helps organizations demonstrate data provenance and comply with data protection and privacy regulations by showing how data is handled and where it is used.
- Impact Analysis: When changes are made to data sources or transformations, data lineage allows organizations to assess the potential impact of these changes on downstream processes and applications.
- Troubleshooting: When data-related issues or errors arise, data lineage can help trace back the origin of the problem and facilitate quicker resolution.
- Data Understanding: Having a clear data lineage can help data analysts, scientists, and business users better understand the data they are working with and the relationships between different data elements.
Data lineage is often represented visually through data lineage diagrams or data flow diagrams, showing the data's path from its source to its destination, with intermediate steps and transformations indicated along the way. These diagrams can be part of a larger data governance framework and are especially valuable for data-intensive organizations or those dealing with sensitive or regulated data.
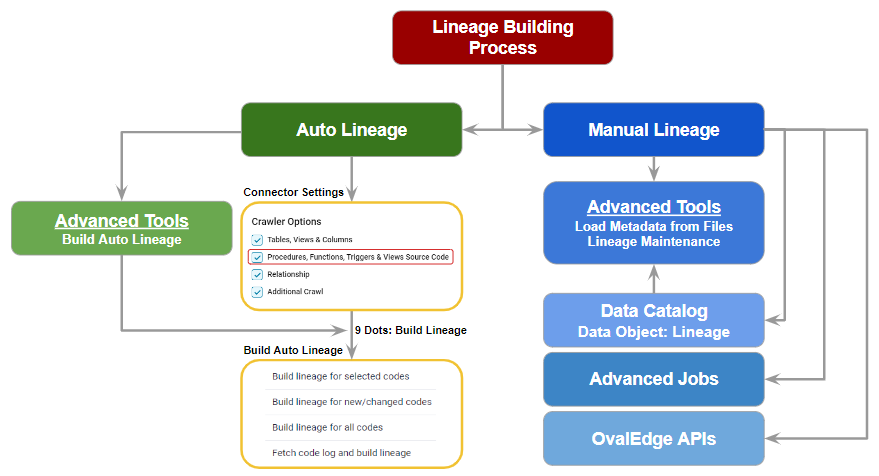
OvalEdge Data Lineage is built using the Views, Stored Procedures, Functions, Triggers, Package Body, Source Code of ETL and Reporting databases, Files (json, xml, yaml,.csv, and .config files). There are two methods for building lineage within OvalEdge: Auto and Manual.
- Manual Lineage: This is the process of building lineage manually by Lineage Maintenance, Load Metadata from Files, Advanced Jobs, or Lineage API
- Auto Lineage: This process builds the lineage by parsing the queries or source codes automatically.
Connector Configurations
Add on for Lineage
Auto Lineage
In OvalEdge, the journey to use auto lineage creation starts on the connectors page. Here, users will find an important checkbox that's connected to the auto lineage license. When a user checks this box, they unlock OvalEdge's powerful automated lineage. This tool makes it easy to track where data comes from and where it goes, streamlining the process and making it more efficient.
Manual Lineage
OvalEdge recognizes that not all users require or opt for automated lineage creation. In cases where the auto lineage checkbox remains unchecked, users maintain control over their lineage-building process. While automatic lineage creation may be disabled, users still possess the capacity to construct their lineage manually. This flexibility allows users to tailor their approach to lineage creation to meet their specific needs, ensuring that OvalEdge accommodates a wide range of user preferences and requirements.
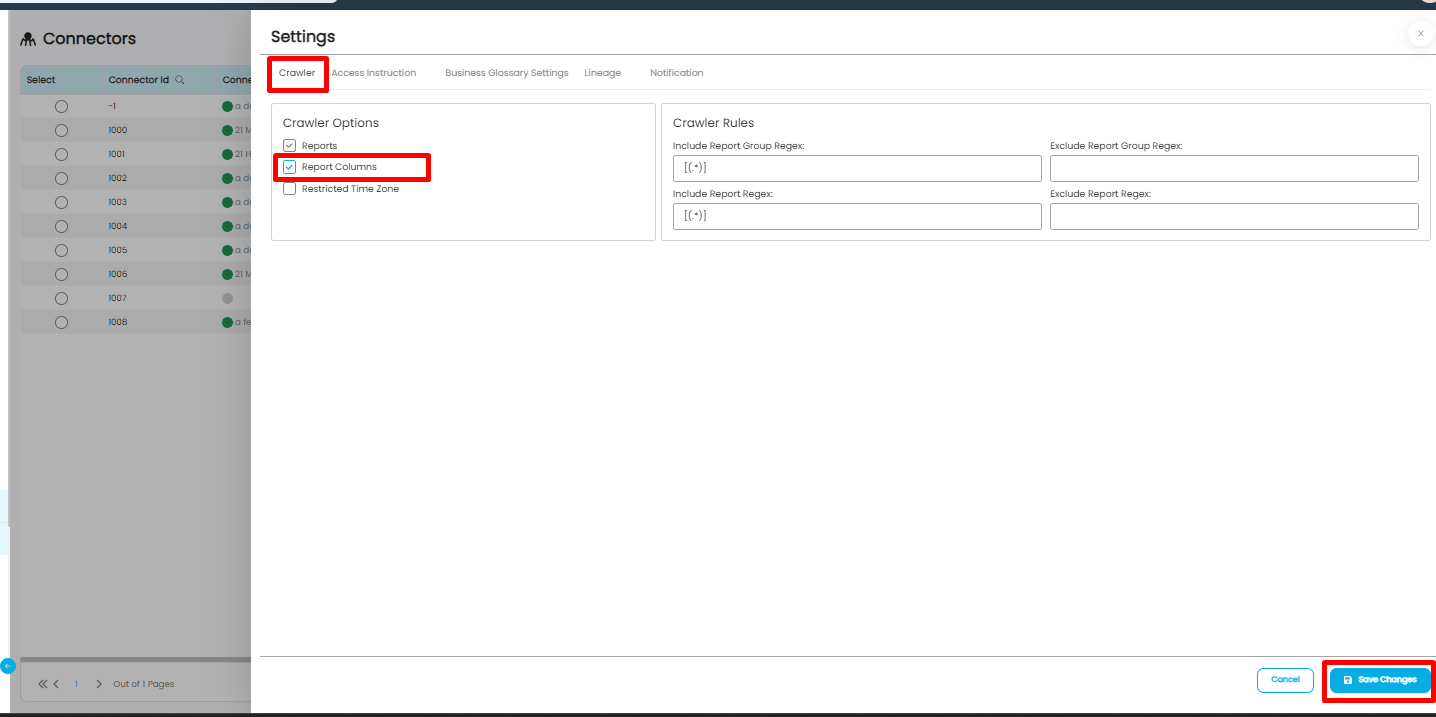
Crawler Setting
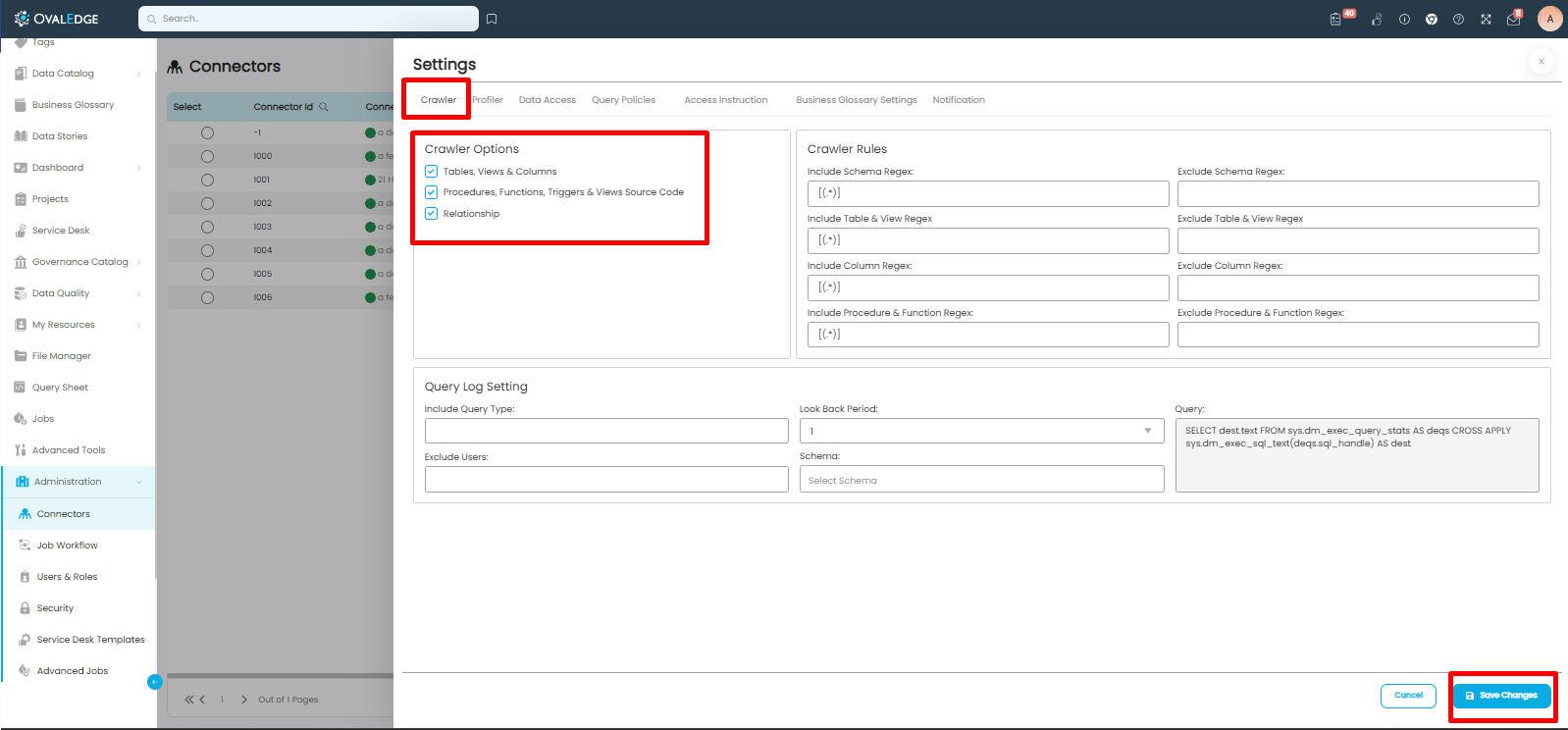
When utilizing OvalEdge to crawl a connector, users must navigate through specific configurations within the crawler settings to enable the automatic lineage building feature. These configurations are tailored to the type of connector being used, ensuring that the process aligns with the connector's unique characteristics. For instance, the configuration requirements for an RDBMS (Relational Database Management System) connector will differ from those of a report connector. These settings can be configured by user having the Integration Admin role assigned to them.
OvalEdge understands that different types of connectors have their unique needs. That's why the platform gives the power to customize and adjust the settings for the crawler. This way, one can easily turn on auto lineage building for the connector, no matter what type it is. This flexibility and personalized approach make it easier to get the right data lineage for various data sources.
(a) RDBMS Connectors
For RDBMS connectors in OvalEdge, the process of setting up auto lineage creation is a bit more specific. Here's an expanded explanation of the steps involved:
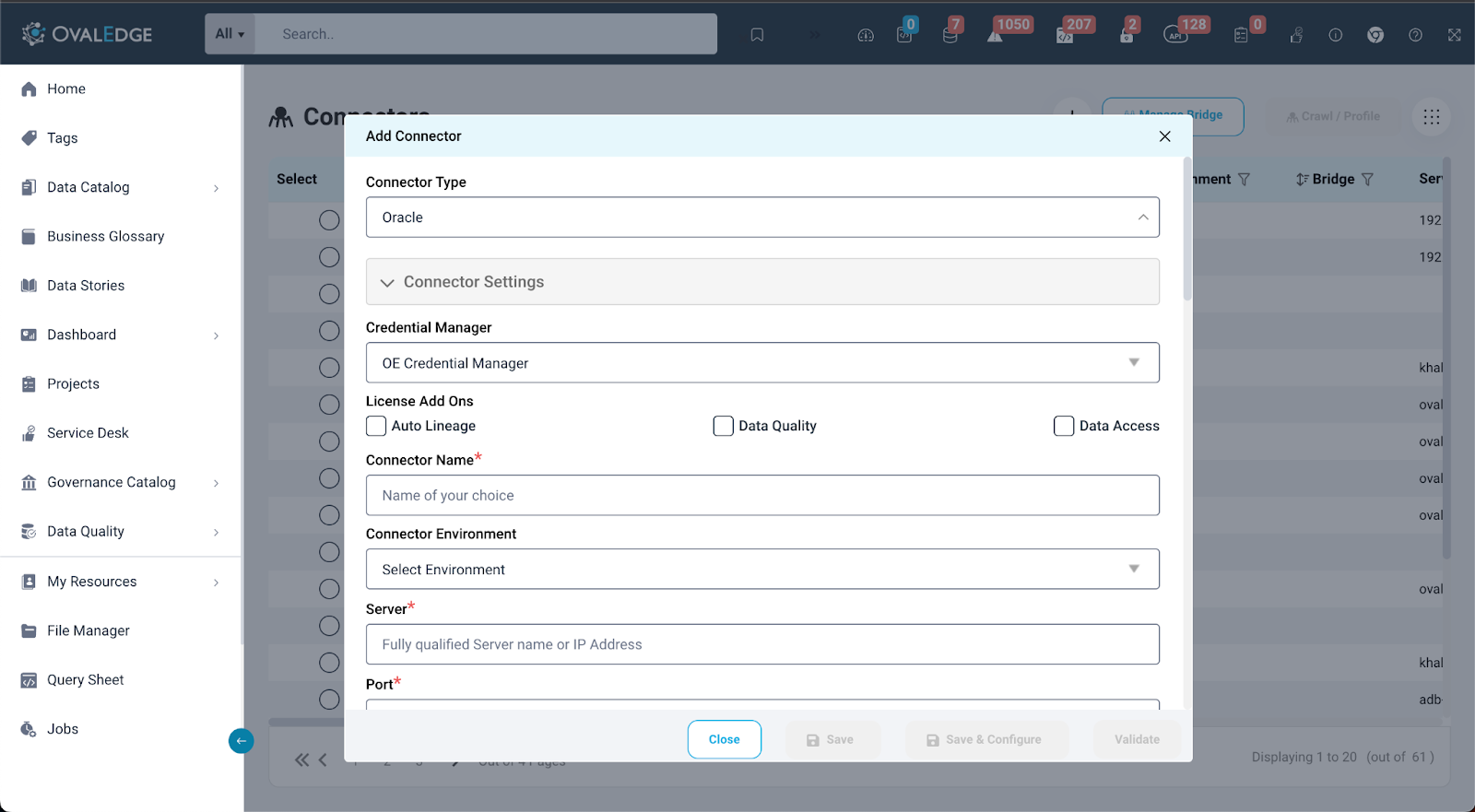
- Connector Setup: When adding an RDBMS connection in OvalEdge, there are important steps to follow. First, go to the connectors page. During the connection setup, be sure to tick the checkbox for the auto lineage license type. This is the key to making OvalEdge automatically build the data lineage. Also, provide all the necessary connection details, save, and validate the connection to make sure it is set up correctly.
- Fine-Tuning in Connection Settings: After the connection is saved, proceed to the connection settings by clicking on the 9-dot menu located on the connector page. Within these settings, there's another important checkbox to address. Specifically, the user should enable the checkbox for "Procedures, Functions, Triggers, and Views Source Codes." These elements are vital components of the source system and play a crucial role in building comprehensive lineage within OvalEdge. Once this checkbox is enabled, do not forget to save the changes.
- Crawling Procedures, Functions, Triggers, and Views Source Codes: By enabling the checkbox for "Procedures, Functions, Triggers, and Views Source Codes" in the connection settings, the process of crawling starts for the specific source code components in the RDBMS. These codes are critical for creating a detailed data lineage that accurately represents the source system. The Codes are the building blocks for making lineage in OvalEdge, giving a complete view of how the data flows.
(b) Reporting Connectors:
When it comes to reporting connectors in OvalEdge, enabling the auto lineage building feature involves specific steps. Here's a more detailed explanation:
- Connector Configuration: When configuring a report connector in OvalEdge, it starts on the connectors page. During the connection setup, it is essential to make sure the auto lineage feature is turned on. Do this by checking the box related to the auto lineage license type. This is the key to unlocking OvalEdge's automatic lineage building feature. Do not forget to provide all the needed connection details, save and validate the connection to ensure it is set up correctly.
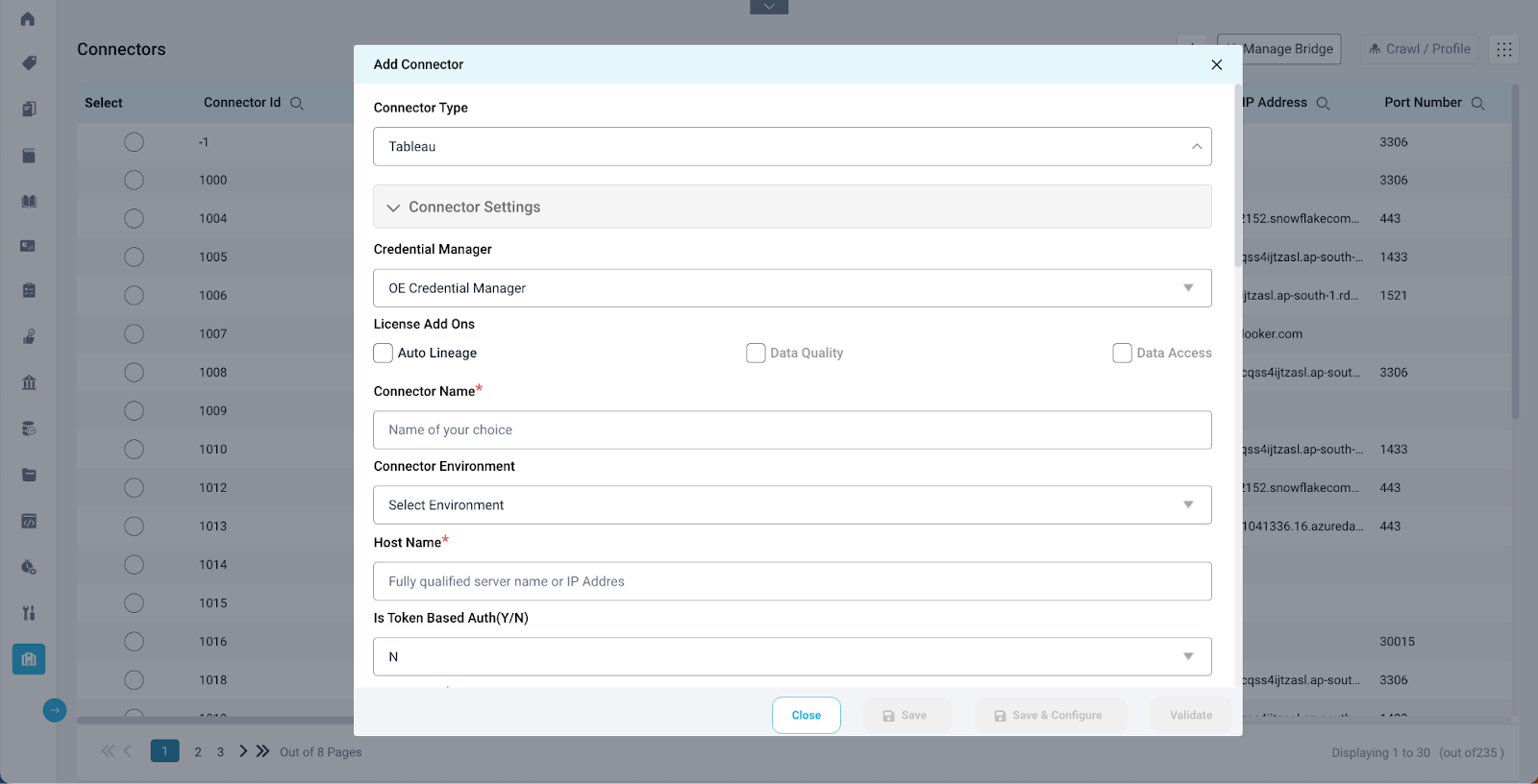
- Fine-Tuning in Connection Settings: After successfully setting up the connection, go to the connection settings by clicking the 9-dot menu on the connector page. In these settings, there is a specific checkbox to focus on. It is labeled "Report Columns," this should be activated, especially when dealing with report connectors.
- Crawling Report Columns: Turning on the "Report Columns" checkbox in the connection settings, kicks off the process of crawling these specific report columns in the source system. These columns are essential data parts that play a key role in building a complete lineage in OvalEdge. They serve as the foundational pieces for creating lineage which provide a detailed picture of how the data moves.
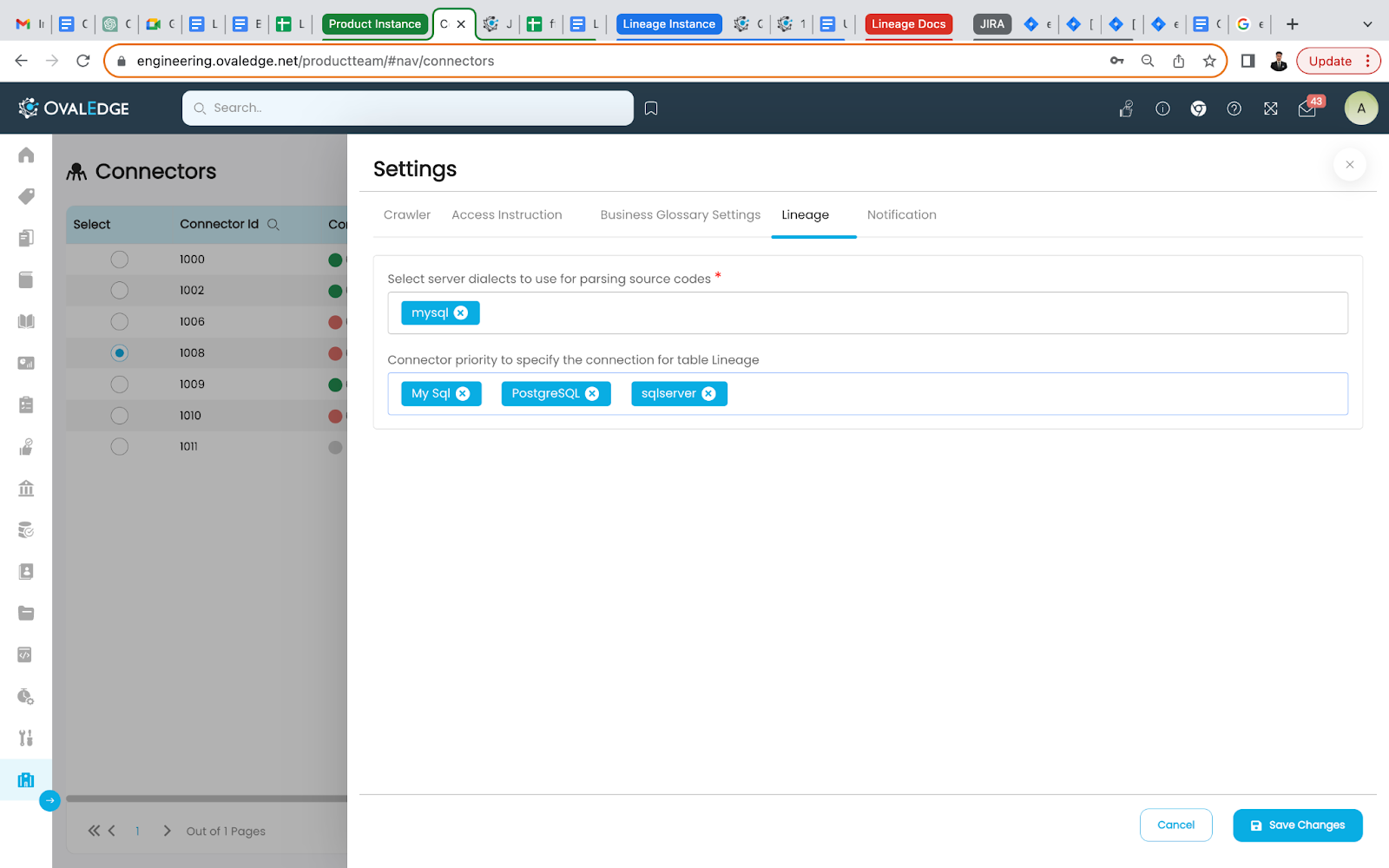
Additionally, the lineage tab in crawler settings, the user needs to fill in the details in the required fields, i.e., select server dialects to use for parsing source codes and connector priority to specify the connection for table Lineage, and click on Ok. The fields are explained below:
The purpose of the lineage tab is for the Reports connector with the Auto Lineage License type, which is the option of changing the server/source connection to build the lineage. This feature allows the user to select multiple servers simultaneously to build the lineage from the required tables.
- Select server dialects to use for parsing source codes (Mandatory) :
While parsing the source codes from the connector, the dialects selected will be used in the specified order. If the first server dialect fails to parse the code, the parsing will be tried using the next server dialects and so forth until the code is parsed successfully. If all the dialects fail to parse the code, then lineage will not be built, and the status will be shown as parse failed. At least one server dialect should be specified for building lineage for the connector codes. - Connector priority to specify the connection for table Lineage:
When a table with the same name is present in more than one connector cataloged table, the user needs to provide connector priority to specify the the priority of picking up table for lineage building .
Example: Connectors: MySQL, PostgreSQL, and SQL Server, which match the customer tables found in the code to catalog objects; it is found that the customer table is present in both SQL Server and postgreSQL connectors. Since PostgreSQL is configured before SQL Server, the customer object lineage will be from the PostgreSQL customer table.
(c) ETL Connector
When it comes to reporting connectors in OvalEdge, enabling the auto lineage building feature involves specific steps. Here's a more detailed explanation:
- Select server dialects to use for parsing source codes (Mandatory) :
While parsing the source codes from the connector, the dialects selected will be used in the specified order.
If the first server dialect fails to parse the code, the parsing will be tried using the next server dialects and so forth until the code is parsed successfully. If all the dialects fail to parse the code, then lineage will not be built, and the status will be shown as parse failed. At least one server dialect should be specified for building lineage for the connector codes. - Connector priority to specify the connection for table Lineage:
When a table with the same name is present in more than one connector cataloged table, the user needs to provide connector priority to specify the the priority of picking up table for lineage building .
Example: Connectors: MySQL, PostgreSQL, and sqlserver, which match the customer tables found in the code to catalog objects; it is found that the customer table is present in both sqlserver and postgreSQL connectors. Since PostgreSQL is configured before SQL Server, the customer object lineage will be from the PostgreSQL customer table.
Building Lineage
Auto Lineage:
Accessing Auto Lineage on Connector
In OvalEdge, after a connector has been crawled, the user can set up auto lineage. Users can do this or not depending on the license provided. Here are the two possibilities to think about:
- With the Auto Lineage License Add-On: When users have the Auto Lineage add-on license, they can easily create automatic lineage. They need to click the 9-dot option on the connectors page, and it will take them to a page called "Build Auto Lineage" to begin building lineage automatically.
- Without the Auto Lineage License Add-On: If users do not have the Auto Lineage add-on license, clicking the 9-dot option on the connectors page will not allow them to build automatic lineage. However, these users have the option to manually create lineage using the lineage maintenance feature.
Building Auto Lineage
OvalEdge makes it easy for users to create lineage for their projects using the source codes crawled. They can do this with one-click called "Build Auto Lineage" in the Advanced tools. In this tool, users can see all the source codes they have crawled for each connector.
Users can pick a connector, and create lineage for all the source codes crawled in that connector.
- Infographics on Build Auto Lineage
The Infographics for the "Build Auto Lineage" feature in OvalEdge offer valuable insights and essential information to users as they begin establishing lineage for the connector. These infographics are designed to provide a clear and comprehensive view of the lineage-building process.
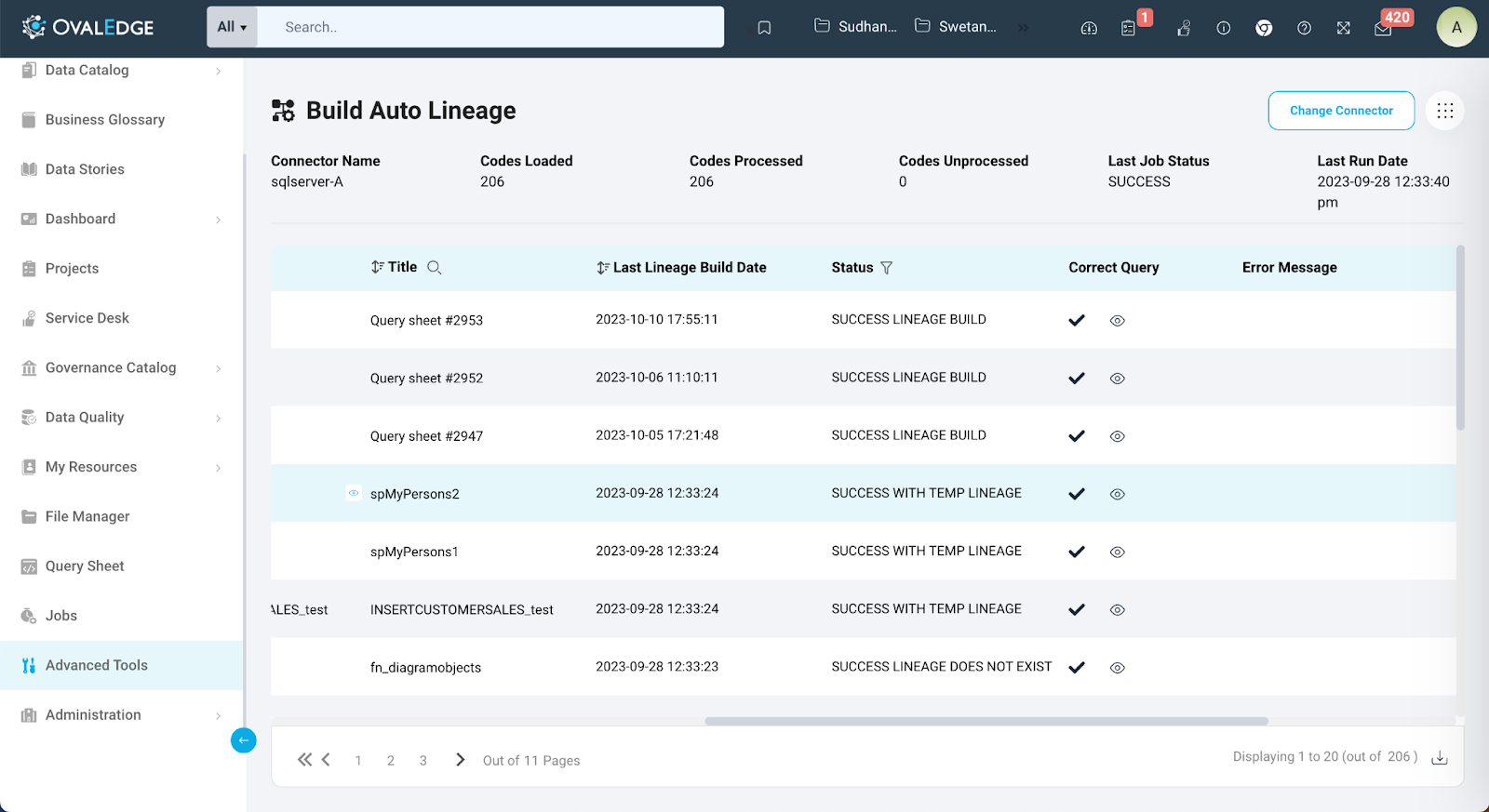
Connector Name
This part shows the name of the connector chosen, helping users remember which data source they are working with for lineage. It is a visual guide to keep the user on track with the project.
Codes Loaded
Here, users can easily ascertain the total number of source codes that have been successfully crawled within the selected connector. These codes are essential building blocks for creating lineage in OvalEdge, and this metric gives users an immediate understanding of the scope of available data.
Codes Processed
This informative metric reveals the number of source codes that have already been processed in the lineage-building journey. Users can track their progress and see how much of the work has been completed.
Codes Unprocessed
Complementing the "Codes Processed" metric, "Codes Unprocessed" indicates the count of source codes that are yet to be processed for lineage construction. It provides users with a clear overview of the remaining tasks.
Last Job Status
Users receive valuable feedback on the most recent job submission for building lineage within the connector. This status update informs them whether the process was successful, ongoing, or encountered any issues.
Last Run Date
The "Last Run Date" infographics display a timestamp, indicating when the last lineage-building job was executed within the connector. This information allows users to track the timeline of their activities and ensure that their data lineage remains up-to-date.
-
Action on Queries
In OvalEdge, the process of building lineage has been streamlined to cater to various user needs. OvalEdge offers a range of options to address specific requirements, making the lineage-building process flexible and efficient. Here is an overview of these options, along with some additional context:
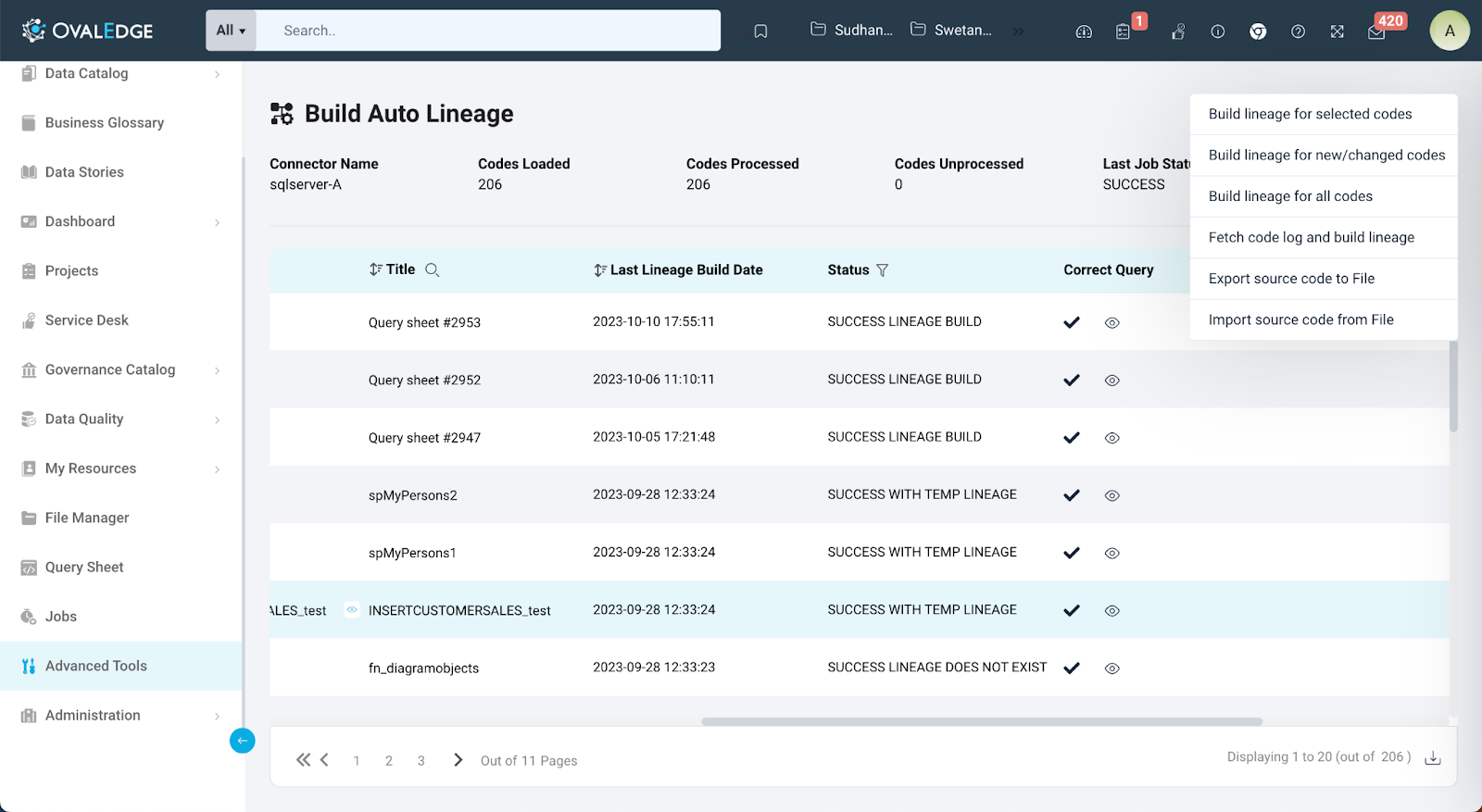
Build Lineage for Selected Codes
Users can pick and choose the specific codes they want to create lineage for. This helps users ensure that their lineage accurately represents the codes they've selected.
Build Lineage for New or Changed Codes
This option lets users create lineage for codes that are either new or have been modified. It is handy for keeping data lineage up-to-date when the data changes.
Build Lineage for All Codes
If users want to cover all available codes within the selected connector, this option automates the process. It gives users a complete view of the data lineage.
Fetch Code Log and Build Lineage
For Oracle , SQL Server , PostgreSQL, MySQL , Snowflake; OvalEdge offers a special lineage building using the code log. This option enables the user to build the lineage using the query logs. The query log setting needs to be done while creating the connection. The details of the the query log setting is explained in Connectors - Deep Dive Article
Export Source Code to File
OvalEdge understands the importance of data curation. With this feature, users can export the source code for the selected codes in a .zip format (Password protected for additional security) . A simple click initiates a job submission, and the file is promptly downloaded. This exported data can be curated and analyzed within OvalEdge Lab.
Import Source Code from File
This option allows users to re-integrate curated or updated data. USers can upload a .json file containing source code for the same connection that has been previously exported. This ensures that the lineage remains current and accurate.
These options provide OvalEdge users the flexibility to tailor their lineage-building process to their specific needs, whether they are focusing on specific codes, staying updated with data changes, or getting a comprehensive overview. OvalEdge provides the tools to make managing data lineage easier.
- Viewing Queries
After a user has submitted and executed a job, OvalEdge provides users with the capability to access essential information for each individual query within the "Build Auto Lineage" page dedicated to a specific connector. This feature is designed to give users granular insights into their data lineage creation process. Here is an in-depth look at the critical information available for each query:
Schema Name
This field reveals the schema associated with the code within the connector. It is a fundamental element for understanding the structure and context of the code, ensuring clarity in the data lineage.
Code Name
The "Code Name" section displays the specific name of the code under consideration. This information helps users quickly identify and reference the code within their lineage.
Lineage Status
A vital indicator of the data lineage progress, "Lineage Status" provides insights into the current status of the query within OvalEdge. Different lineage statuses are utilized to communicate the query's status, ensuring transparency and clarity in the lineage creation process. The different statuses are:
|
STATUS |
PARSE |
Lineage Discovered |
TABLE TYPE |
|
SUCCESS_LINEAGE_BUILD |
100% |
YES |
RT |
|
SUCCESS_WITH_TEMP |
100% |
YES |
TT |
|
SUCCESS_LINEAGE_DOES_NOT_EXIST |
100% |
NO |
– |
|
SUCCESS_LINEAGE_FIXED |
100% |
YES |
RT |
|
SUCCESS_LINEAGE_PARTIALLY_BUILD |
<100% |
YES |
RT |
|
SUCCESS_LINEAGE_PARTIALLY_BUILDWITH_TEMP |
<100% |
YES |
RT+TT |
|
PARSE_FAILED |
FAILED |
– |
– |
|
FAILED_UNSUPPORTED_QUERY |
FAILED |
– |
– |
|
SUCCESS_LINEAGE_BUILD_WITH_OVALEDGELAB |
100% |
YES |
RT |
|
SUCCESS_MANUALLY_BUILD_WITH_OVALEDGELAB |
100% |
YES |
RT |
|
SUCCESS_NO LINEAGE BUT ASSOCIATION |
100% |
NO |
- |
Correct Query
OvalEdge empowers users to take corrective action with the "Correct Query" option. By clicking the ‘Eye’ icon, Author users with Meta-write permission on the data asset can view the query and make necessary adjustments or refinements. This feature is particularly useful when users need to address parsing issues or make improvements to ensure a successful lineage creation process.
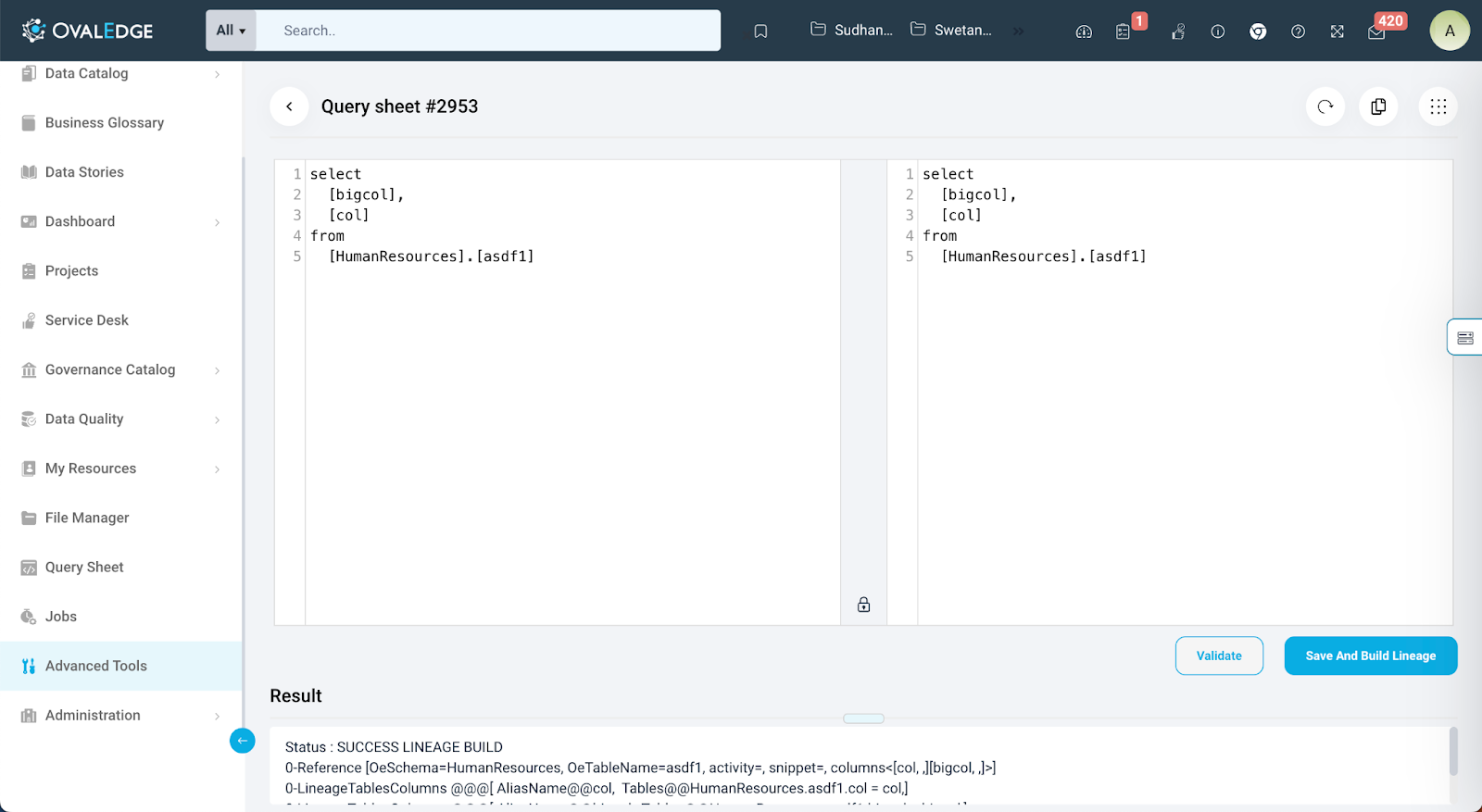
View Code: In OvalEdge, users can easily check and understand specific code components. They just need to click the ‘Eye’ icon in the "Correct Query" column on the "Build Auto Lineage" page. This feature provides insight to what is inside the code and makes it easier to understand how data lineage is built.
Correct Code: In OvalEdge, users have a useful tool to keep the data lineage accurate. If a code has problems or needs changes, the "Correct Code" (✓) option helps. Users can use this feature to fix the code i.e make changes to code or syntax and revalidating the code, making sure that the data lineage stays correct and reliable. It is essential for handling errors and adapting to changes, which helps maintain a strong data lineage system.
In OvalEdge, users have a wide range of options for improving and handling their code through the "Correct Code" feature. Compare Screens: OvalEdge provides a convenient side-by-side comparison, offering users two screens for code editing. The left screen shows the original query, and the right side is a blank workspace where users can make changes to the code. Operations in Correct Query:
- Copy Query: This operation facilitates the seamless transfer of the original query to the editing window, which is the left window. Users can effortlessly copy and paste the original code, making it the foundation for their editing process.
- Validate: The "Validate" button empowers users to check the correctness of their edited query. It ensures that the query adheres to the required syntax and structure.
- Save & Build Lineage: Users can preserve their edited query and initiate the lineage-building process with the "Save & Build Lineage" option. This function becomes enabled only when the code successfully passes validation, ensuring that the lineage is based on a validated query.
- Reset: The "Reset" option restores the query to the previous version. It undoes any validation changes, allowing the user to make more adjustments or address parsing problems.
- Replace: The "Replace" feature streamlines bulk corrections by enabling users to replace incorrect strings with the correct ones throughout the code with a single click.
- Format Query: To enhance readability and comprehensibility, the "Format Query" operation aligns the query into a structured format. This ensures that the code is easy to understand and curate, contributing to a smoother curation process.
- Results: This section offers users a window into the outcome of the query parsing process. It displays the results of the parsing, along with any associated logs, providing a clear overview of the code's status.
- Build Lineage using Shutter (Box Icon at the Right Center of the Screen): The "Shutter" feature offers users a versatile approach to building lineage. Within Shutter, users can perform the following actions:
b) Relationships: Users can select schemas, tables, and columns on the left and right sides to establish relationships. This facilitates the establishment of connections between data elements.
c) Associations: Users can select objects to associate with the query and save those associations. This feature allows for the creation of meaningful connections between queries and other data elements.
Error Message
In cases where a query encounters parsing difficulties and the status is marked as "Parse failed," the "Error Message" section comes into play. It provides users with the error log, shedding light on specific issues that need attention. This information helps users diagnose and resolve parsing errors effectively.
Viewing Lineage on Queries
After successfully building lineage in OvalEdge, users gain access to information regarding the specific queries they havev worked on. Viewing the lineage of these queries opens up a world of insights. Here is an expanded explanation of what is available:
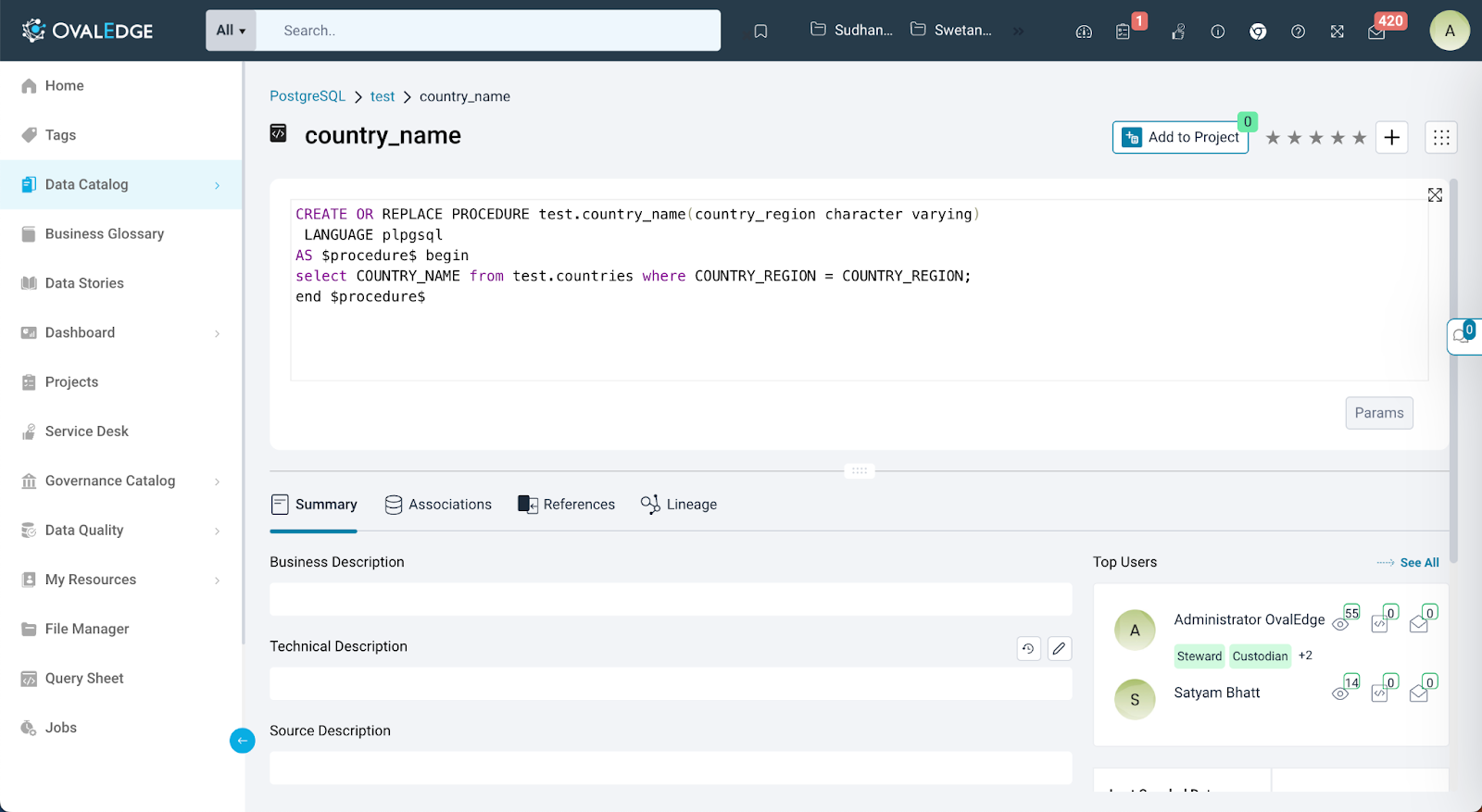
Query Summary
This section offers a comprehensive summary of the query. It includes business description, a technical description, associated business glossary terms, tags, top users who have interacted with the query, the last crawled date, and the lineage status.
Associations
The "Associations" tab provides a list of objects that are directly associated with the query. These associations are crucial for understanding the query's connections and its impact on other data elements within the system.
References
In the "References" tab, users can explore a list of objects where the root object is being referred to. This information is valuable for understanding where and how the object is being utilized across the system.
Lineage
Under the "Lineage" section, users can delve into the details of how the lineage was constructed. This includes two viewing options:
- Graphical: The "Graphical" view offers a visual representation of the lineage built using the source codes crawled. It showcases the one-to-one lineage between objects created by the query. Users should be aware that there might be duplicate nodes of the same object in this graphical representation.
- Tabular: The "Tabular" view is designed for interpretation of the lineage graph. It presents the lineage in a table format, for users to analyze and comprehend the lineage. Additionally, users have the option to download the tabular lineage for further analysis.
By exploring lineage, users can gain a comprehensive understanding of the data's journey. For an even deeper understanding of each field, users can refer to the Data Catalog Deep Dive Article, which provides detailed explanations and insights.
Manual Lineage
Users can build lineage manually in OvalEdge by using the Lineage Maintenance and Load Metadata from Files tools.
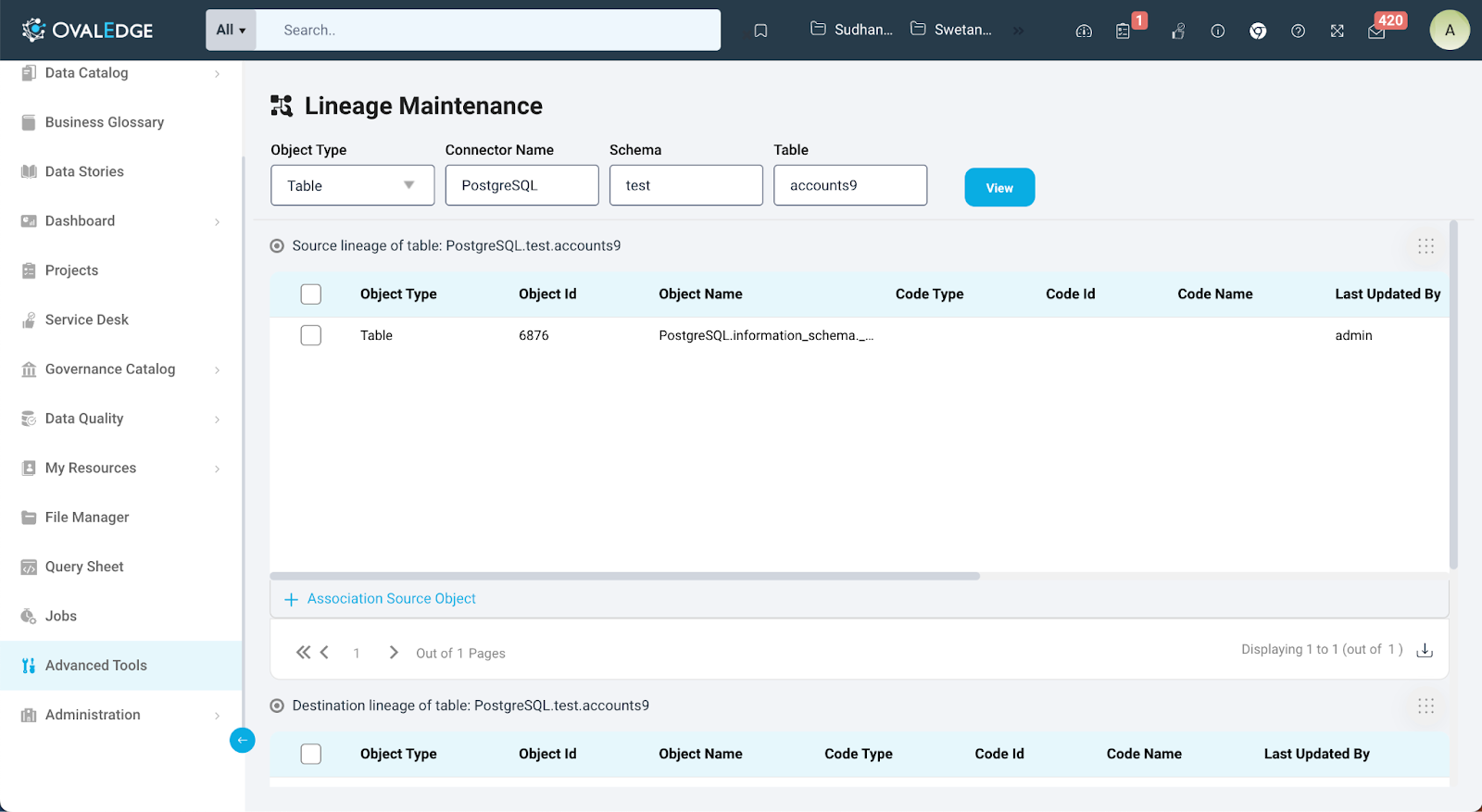
Accessing Manual Lineage
Building manual lineage within OvalEdge can be accomplished through three distinct methods, each tailored to user preferences and requirements:
- Advanced Tools
Users can access the Lineage Maintenance module within the Advanced Tools section. Once in Lineage Maintenance, users must select the desired schema and object for which they intend to construct the lineage manually. After selecting the object, they can add source and destination objects, along with any responsible queries if applicable.
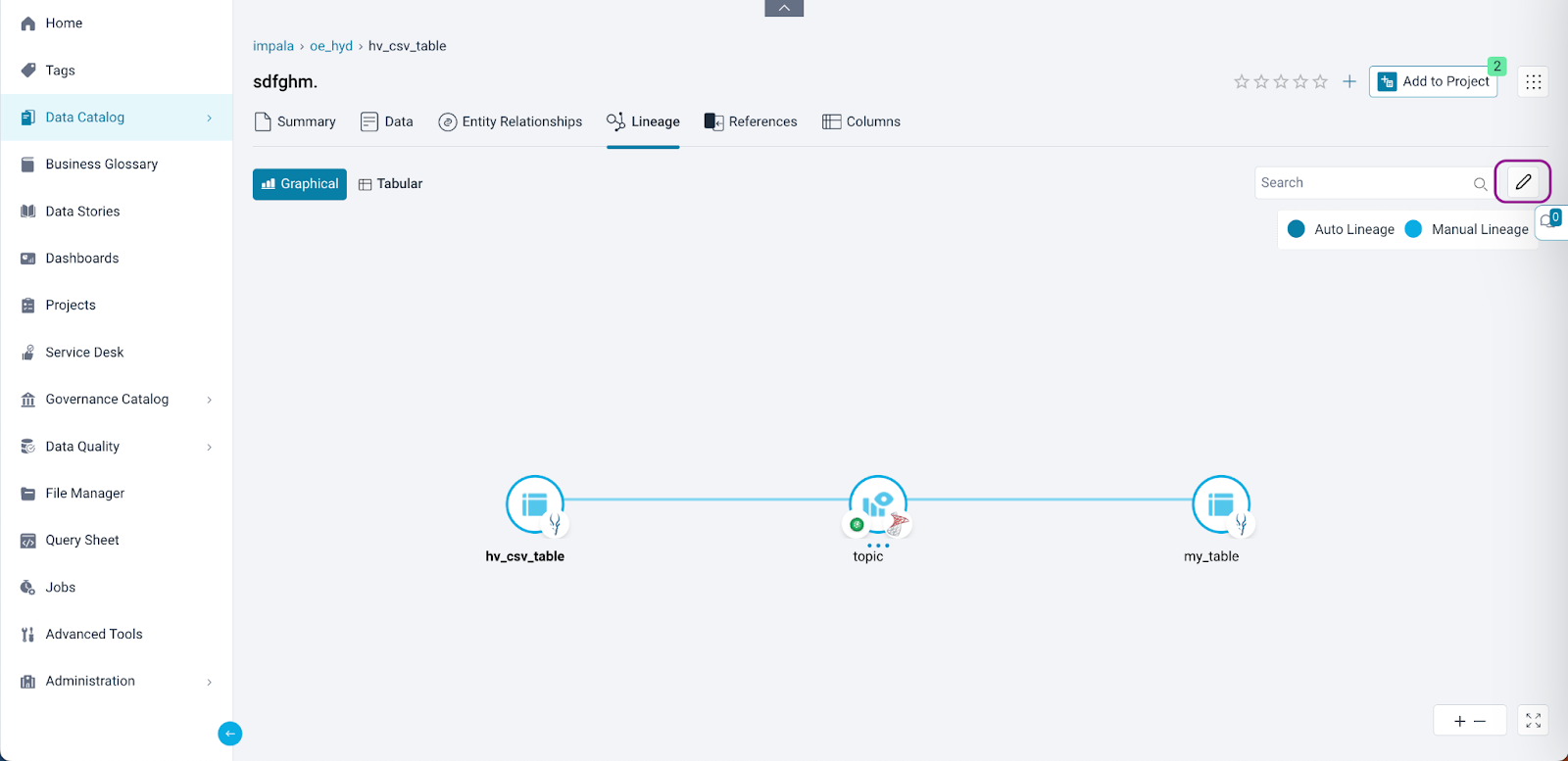
- Data Catalog
Lineage maintenance is also accessible directly from the Data Catalog. Users can navigate to the graphical Lineage tab within the Data Catalog and locate an edit icon (Pencil icon). By clicking on this icon, the screen will redirect to the Lineage Maintenance page, allowing users to build the lineage manually by adding source or destination objects.
Building Manual Lineage
-
Source Mapping
Author users with meta-write permissions can add source objects to the selected object by clicking on the "Add Source Object" link within the Source Object table on the Lineage Maintenance page. Users can choose the object they wish to add as the source. Additionally, users can specify the codes responsible for the relationship between two objects in the lineage by clicking on edit icon in the codes column. Transformation notes can be added, and a list of associated source objects can be downloaded by clicking the download button at the bottom of the table.
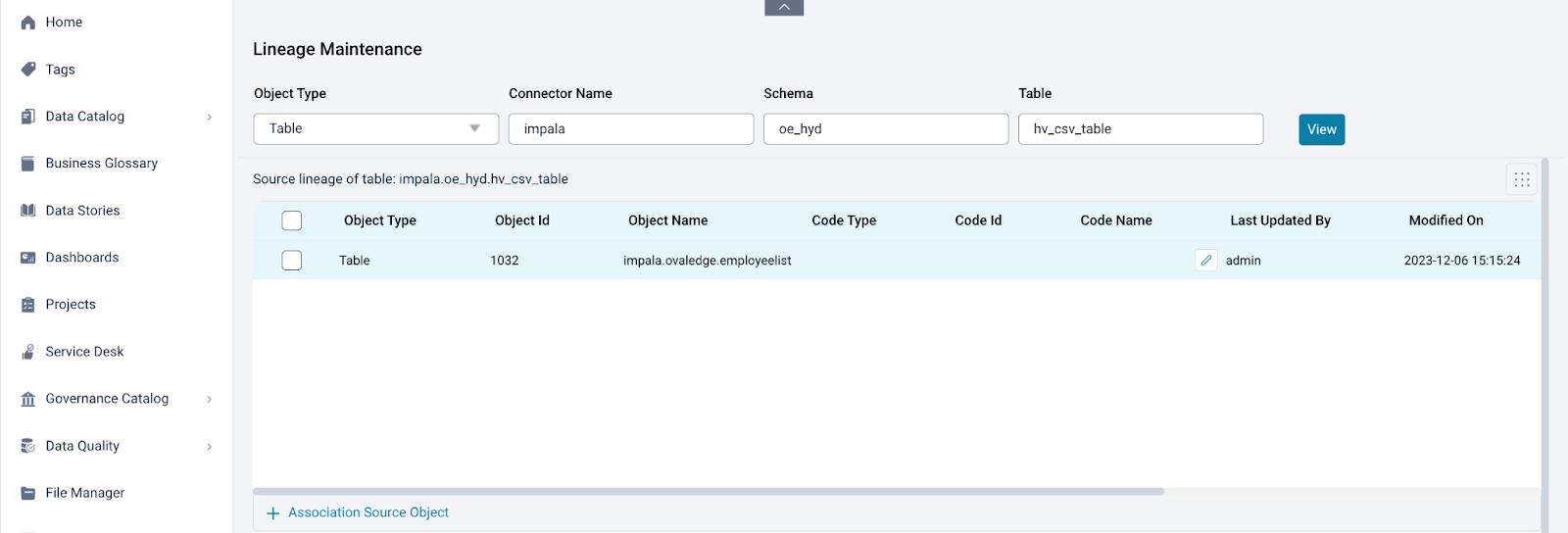
- Destination Mapping
Similarly, the author user with meta-write permissions can add destination objects to the selected object by clicking on the "Add Destination Object" link in the Destination Object table on the Lineage Maintenance page. They can select the desired object for the destination and indicate any responsible codes. Transformation notes can be included, and a list of associated destination objects can be downloaded for reference.
NOTE: Editing and Deletion of Auto Lineage is not permitted. Changes to auto lineage can only be done through OvalEdge Lab.
- Load Metadata from Files
OvalEdge offers a convenient bulk upload feature known as "Load Metadata from Files" (LMDF). In this method, users can download a template from the LMDF module, complete it with details such as source object ID, source object schema, target object ID, target object schema, query details, and column mappings. After populating the sheet, users upload the file back to the LMDF module. This action triggers a job submission. Upon successful execution of the job, the lineage is constructed based on the information provided in the sheet.
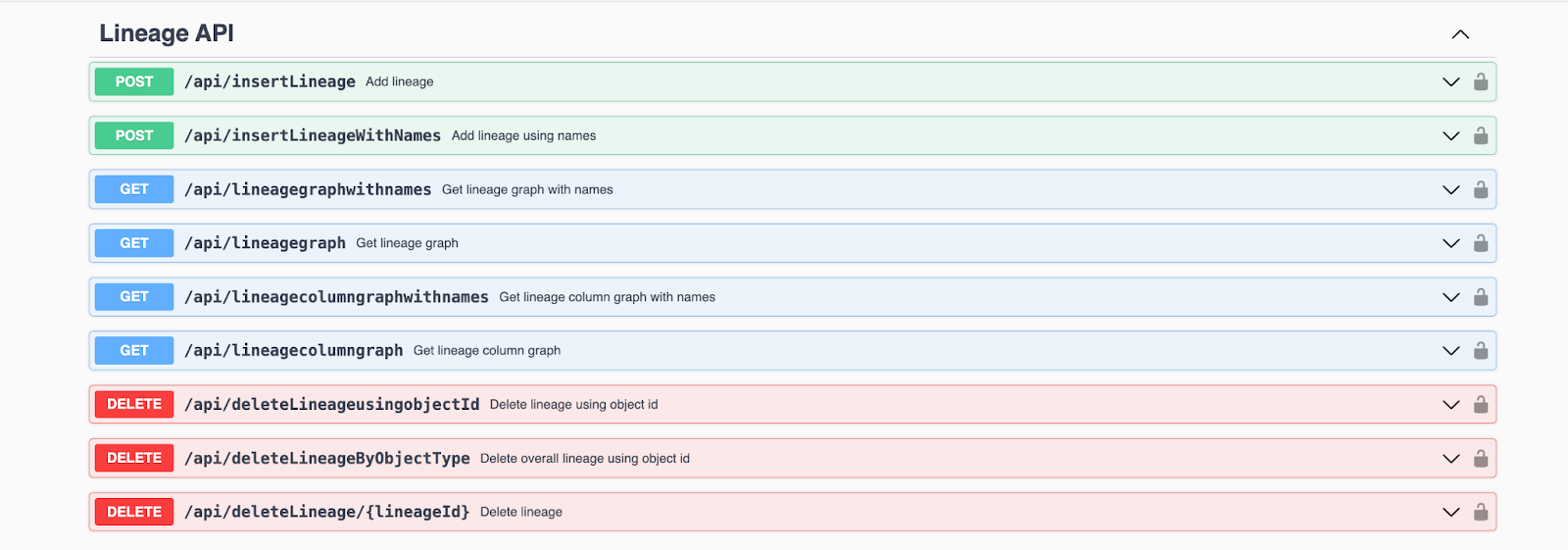
- Lineage Building Using APIs
OvalEdge also has the ability to build, edit and delete lineage using API’s. User can build lineage by providing some of the basic required field in the API.
These are the API present in OvalEdge for lineage. For more details on API , Refer APIs | Deep Dive Article
These manual options give OvalEdge users the power to carefully manage their data lineage, ensuring accuracy and precise tracking. This meticulous approach is crucial for maintaining data integrity in the OvalEdge platform.
Accessing Lineage in Catalog
Understanding lineage data is essential for effective data management, OvalEdge provides a wide range of tools and resources to assist users in accessing and interpreting this information. This detailed overview, willexplore how users can navigate and comprehend lineage data within the Data Catalog:
Accessing Lineage
Lineage information is accessible at the object level within the Data Catalog. Users can find the lineage details at the lineage tab, which is available for every object within the catalog. This tab provides a wealth of information about how data objects are interconnected and how they flow through the connected source systems.
Graphical View
The Graphical View presents a visual overview of the lineage, offering insights into the connections and relationships between different data objects. Here is a detailed breakdown of what the graphical view entails:
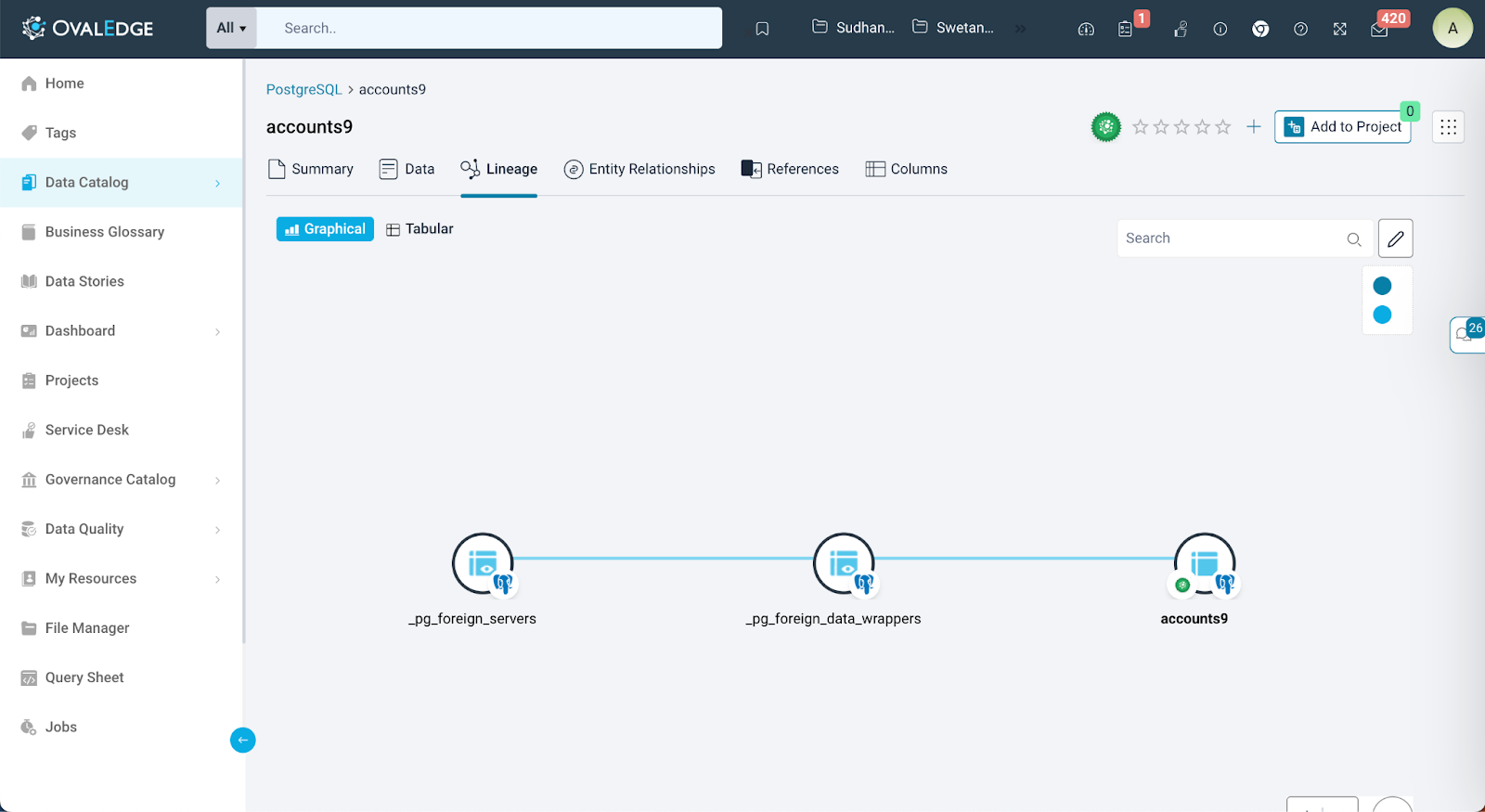
Lineage Nodes
In the lineage diagram, each object is symbolized by a circular node. These nodes are not mere visual elements; they are information hubs that deliver valuable insights at a glance. By simply looking at a node, users can immediately access the following essential information:
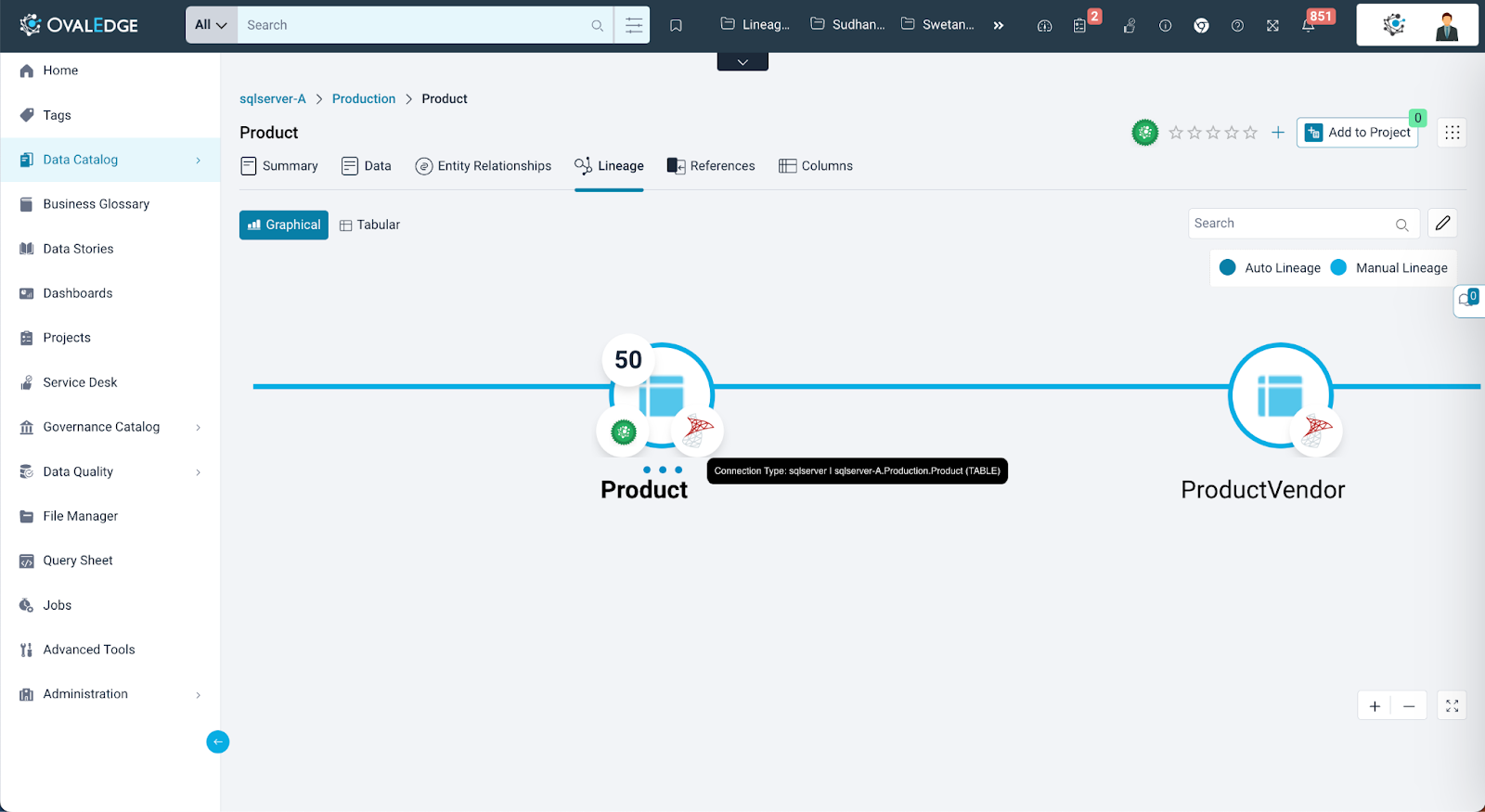
- Certification
Positioned at the bottom left of the object node, the certification information is represented through an icon. Clicking on this icon grants access to the certification history of the object, offering clarity on its certification status over time.
- DQ Score
Located at the top left of the node, the overall Data Quality (DQ) score of the object is showcased (if it has been calculated within OvalEdge). By clicking on this DQ score, users can delve into the DQ dashboard for that specific object, gaining deeper insights into data quality.
- Additional Info on Node
At the bottom right of the node, additional information is presented. OvalEdge displays an icon representing the connector of the object, providing a quick reference to the system with which the object is associated. This visual cue aids users in understanding the object's origins and connections within the system.
Differentiation in Lineage
In OvalEdge, the color of the lines connecting two nodes in the lineage diagram signifies the process of lineage creation between those nodes. Light blue lines indicate that the lineage was manually constructed, while dark blue lines indicate automatic lineage creation.
Lineage Lines
The lines connecting two nodes in the graphical view represent the data's journey as it moves from the source node to the destination node. These lines are interactive and can be clicked to reveal additional information:
- Summary
A quick overview of the query responsible for building the lineage. This summary page is displayed when there's a query linking two nodes.
- Code/Query
The tab that displays the transformation code with proper syntax, outlining how the data is processed.
-
-
Column Mapping
-
This section illustrates the mapping between columns in the source and destination objects.
Graphical: A graphical representation of the column mapping, showing all columns of the source object on the left and the columns of the destination object on the right, along with the mappings.
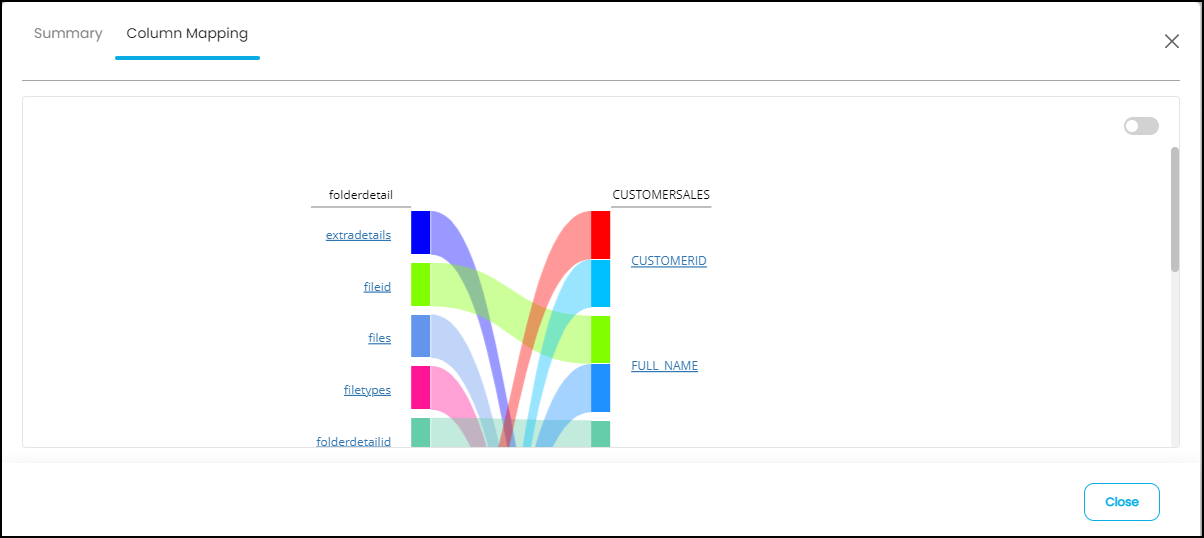
Tabular: A tabular representation of the column mapping, which can be downloaded for more in-depth analysis.
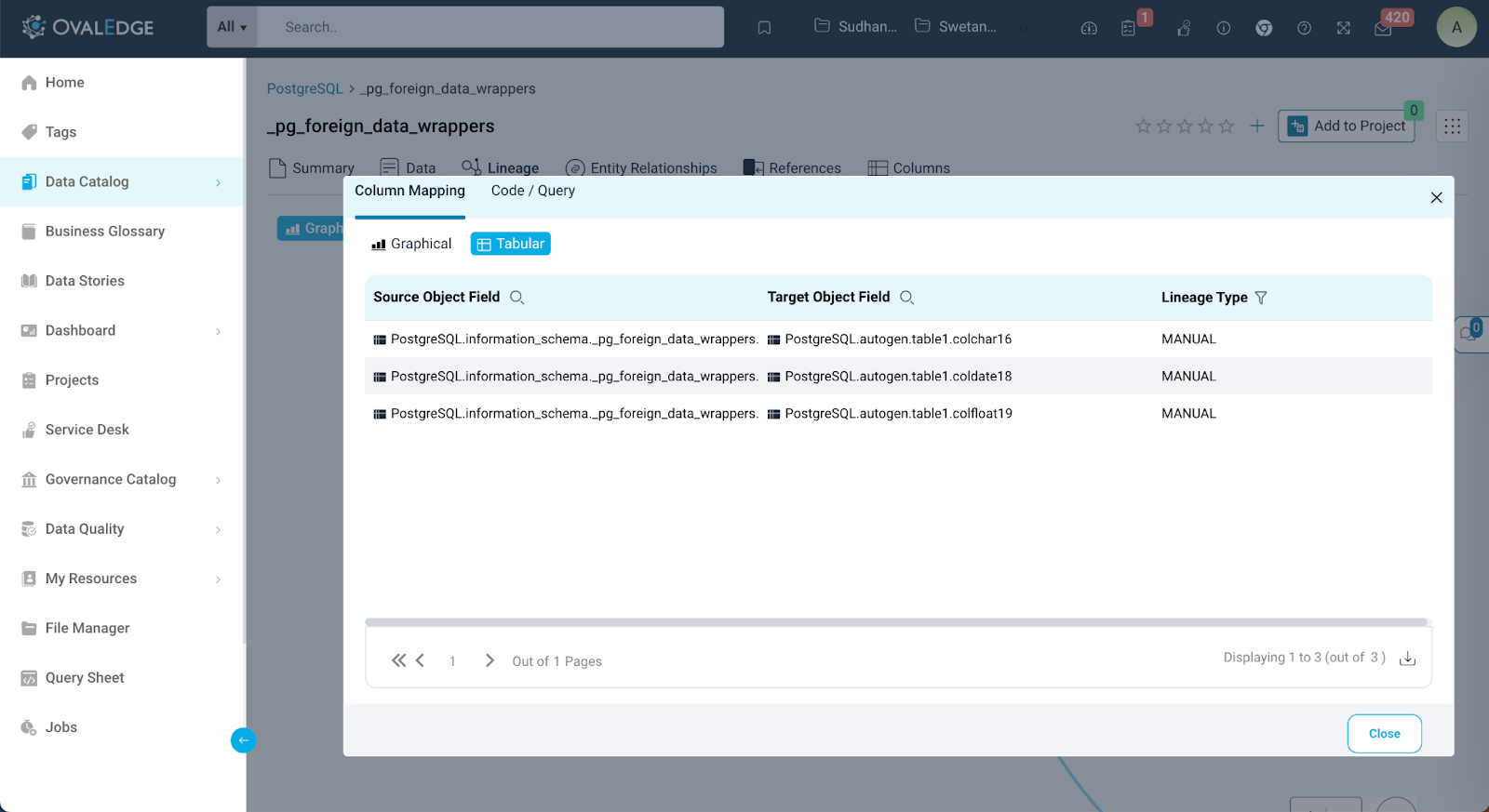
This comprehensive lineage visualization empowers OvalEdge users to effectively manage the data by providing a clear, interactive, and detailed view of how data objects are interconnected and transformed throughout their journey.
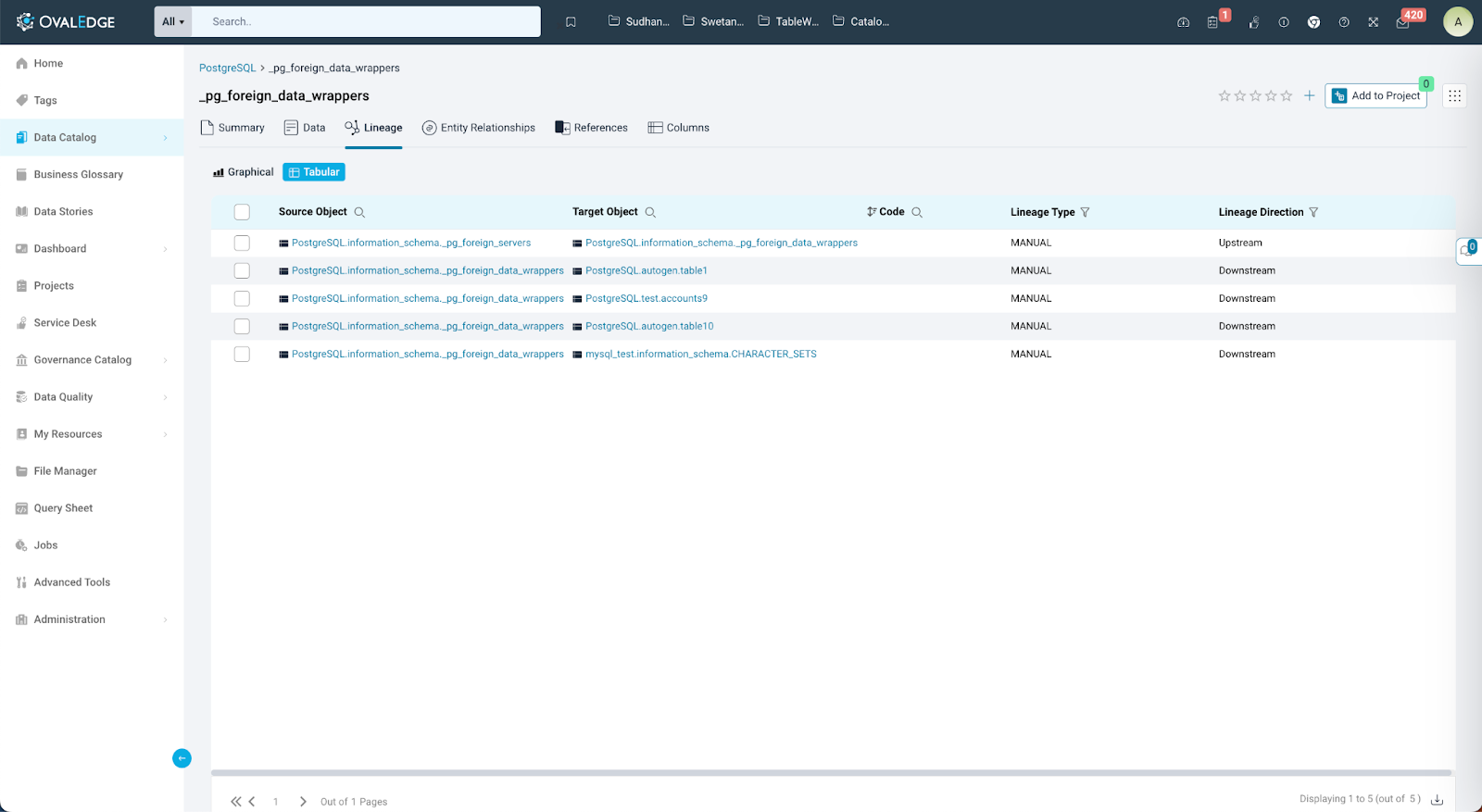
Tabular View
OvalEdge takes data lineage exploration a step further by introducing tabular lineage representation. This feature allows users to view lineage data in a structured table format, offering insights into one level of upstream and downstream lineage. This streamlined presentation makes it easier for users to grasp the data's flow, and they can even download the tabular representation for more in-depth analysis. This feature is a valuable tool for gaining a comprehensive understanding of data lineage and its effects.
- Download and Analysis
Users have the flexibility to download the tabular lineage representation, enabling them to conduct in-depth analyses and assessments of their data lineage. This feature empowers users to gain insights, make informed decisions, and ensure the integrity of their data.
- Customizable Download
When initiating a download, OvalEdge offers users the ability to specify their preferences. This includes defining what they want to download and determining the level of lineage to include in the downloaded data. These customization options ensure that users receive precisely the information they need for their analyses.
- Upstream and Downstream
Upstream: This refers to all the objects in the source data flow, illustrating how data moves from its origins to the selected object. Understanding the upstream lineage is crucial for comprehending data sources and their contributions to the focal data object.
Downstream: In contrast, downstream lineage captures all the objects in the destination, shedding light on the path data takes as it is processed and delivered to its ultimate destination. Downstream lineage is instrumental in tracing data flow and transformations.
- Level of Lineage
Level -1: This option allows users to download lineage data encompassing all levels of lineage, providing a comprehensive overview of the data's journey. Users can access intricate details of how data is sourced, transformed, and delivered, offering a holistic perspective on data lineage within OvalEdge.
The tabular lineage feature in OvalEdge is a powerful tool for data professionals, offering a structured and comprehensive view of data lineage. It facilitates detailed analysis and empowers users to make well-informed decisions regarding their data management strategies.
Propagating Information Using Lineage
In OvalEdge, data lineage also enables users to pass on important information. OvalEdge has a powerful feature that lets users easily share vital information throughout the data lineage. This capability is a valuable tool that improves data management and ensures that important details are effectively communicated across the lineage.
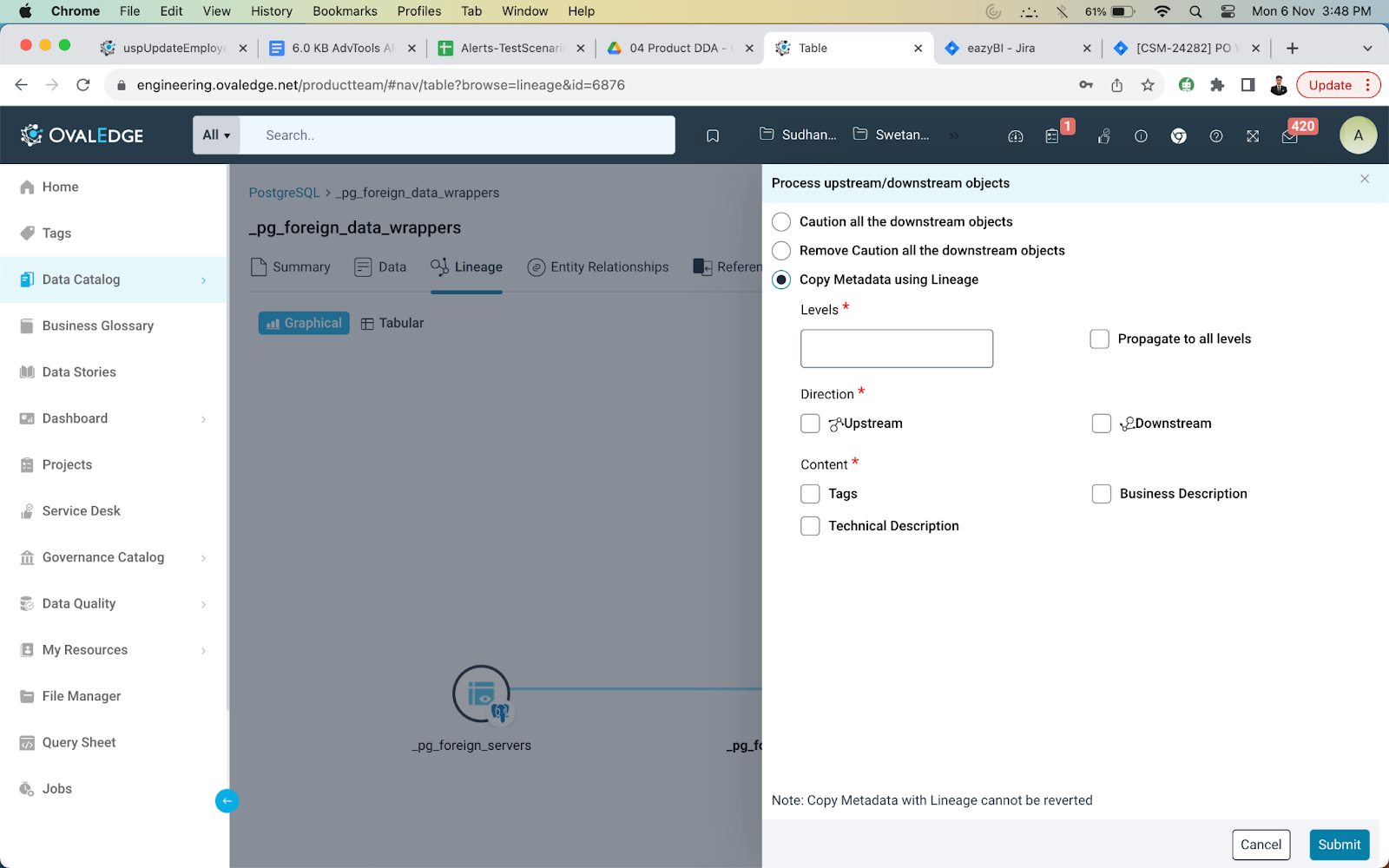
- Caution All
One of the key applications of lineage information propagation is the "Caution All" feature. This functionality enables users to apply caution to all downstream objects, alerting users to exercise caution when interacting with these objects. Caution is applied to downstream objects when the source object is certified as "cautioned." However, it is essential to note that this action can only be performed if the root object itself is certified as cautioned.
- Remove Caution
The "Remove Caution" feature is designed to remove the caution applied to downstream objects through the lineage. This action can be made when it is necessary to maintain data clarity and ensure that caution labels are not applied unnecessarily. However, it is important to understand that this operation can only be executed when the root object's certification is set to "None."
- Copy Metadata - Enhancing Data Consistency
OvalEdge provides users with the ability to copy metadata across specified levels, either upstream or downstream, based on user preferences. This metadata includes essential information such as business descriptions, technical descriptions, and tags. This feature streamlines the process of ensuring data consistency and clarity by propagating relevant metadata to the selected levels within the lineage.
By offering these robust lineage propagation features, OvalEdge empowers users to maintain data integrity, enhance data transparency, and improve data management efficiency. The ability to caution downstream objects, remove caution labels, and copy metadata across lineage levels ensures that data professionals have the tools they need to make informed decisions and optimize data management strategies.
Temp Lineage in OvalEdge
OvalEdge connectors are flexible and offer users two ways to build data lineage. Through the "Build Auto Lineage" feature for automatic lineage creation, or through the manual method to create lineage from scripts to gain valuable insights into data flow.
But to create lineage effectively, OvalEdge relies on associated objects to show how data moves. When the original associated objects are not available, OvalEdge generates temporary associations to help create the lineage, called temporary tables. Once the original schemas and tables are identified, these temporary objects are replaced with the actual originals. This replacement and merging of lineage is done seamlessly through the "Temp Lineage Correction" module, ensuring that the lineage accurately reflects the data's path.
Understanding Temp Objects
Temp objects are like the outcome of the lineage creation process I mentioned earlier. Temp Objects are temporary placeholders that users can work with in the "Temp Lineage Correction" module.
Navigating Temp Lineage Correction
To access the "Temp Lineage Correction" module, navigate through "Advanced Tools" and select "Temp Lineage Correction." This action prompts a pop-up window where users can choose the "Temp Schema" from a drop-down menu displaying all available temporary schemas in the application.
User Actions and Nine Dots Icon
Upon accessing the "Temp Lineage Correction" page, users can take various actions enabled by the "Nine Dots" icon:
- Change Schema Button
Users have the option to change the schema foe temp lineage correction by clicking the "Change Schema" button on the Temp Lineage Correction page.
- Choose Table To Merge
This option comes into play when selecting a temp table. Once a temp table is chosen, users can enable the "Choose Table To Merge" option, which allows them to select a table from the application for merging with the selected temp table.
- Run Job with Schema
This option facilitates the display of original or recommended schemas available within the application.
- Run Job with Table
Similarly, this option provides users with a list of original or recommended tables available within the application.
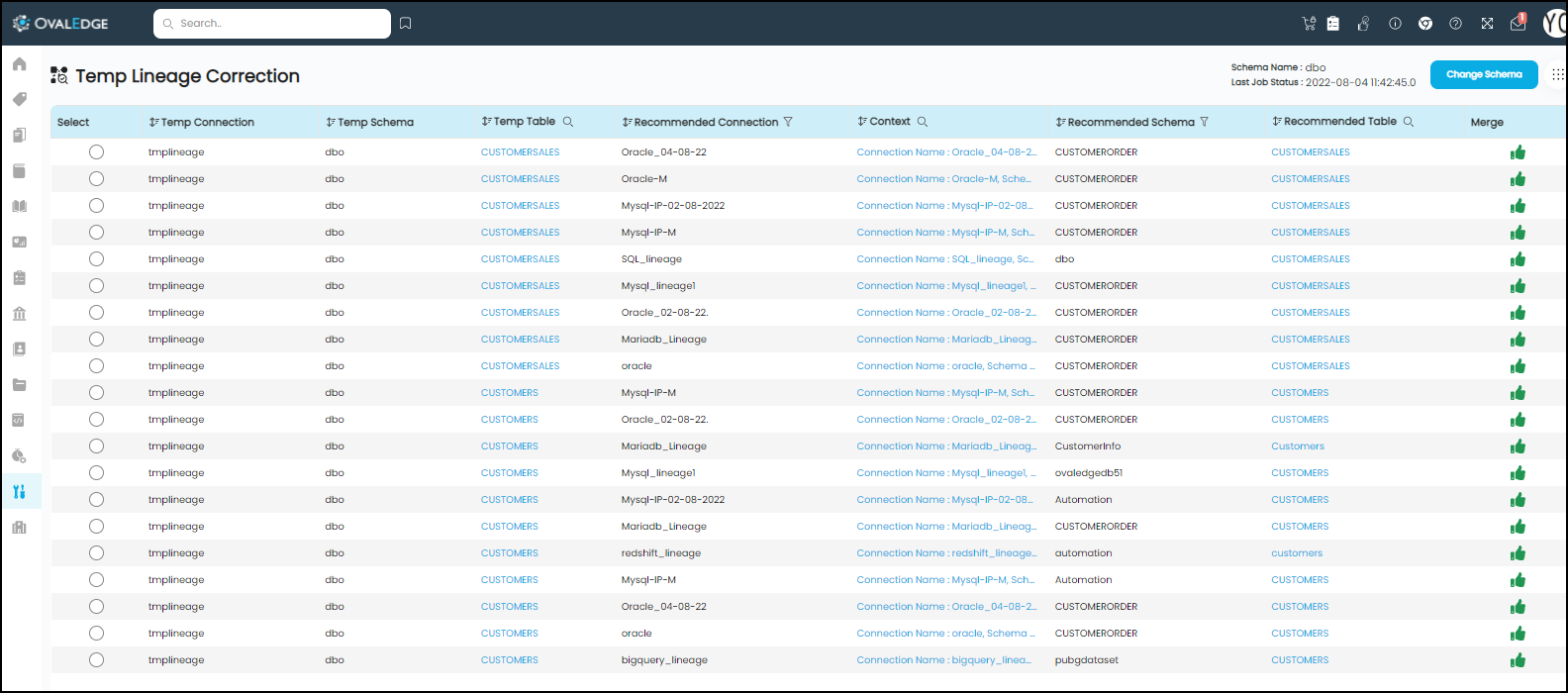
Information Displayed on Temp Lineage Correction Page: The "Temp Lineage Correction" page presents a wealth of information, including Temp Connection, Temp Schema, Temp Table, Recommended Connection, Context, Recommended Schema, Recommended Table, and Merge. Users can opt to view this information by selecting either "Run job with schema" or "Run job with table" from the "Nine Dots" icon, depending on their specific requirements.
|
Fields |
Description |
|
Temp Connection |
Displays the Name of the selected Temp Connection. |
|
Temp Schema |
Displays all the Temp Schema Names available within the Temp Connection. |
|
Temp Table |
Displays all the Temp Table Names available within the Temp Connection. |
|
Recommended Connection |
Displays the Recommended Connection Name to which the recommended Schema/table belongs. Example: The recommended table name CUSTOMERSALES belongs to the connection Oracle-M. So, Oracle-M is the recommended connection name for the recommended table. |
|
Context |
Displays the query used to build the temp lineage. |
|
Recommended Schema |
Displays the list of the original schema available in the application. |
|
Recommended Table |
Displays the list of the original table available in the application. |
|
Merge |
Displays the Merge icon to merge the Temp Schema/Table with the original Schema/Table. |
Lineage Dashboard
The Data Lineage Dashboard provides viewer users with a visualization of the end-to-end flow of data from the source to the destination for all the data connections in OvalEdge.
The connected data objects are called nodes and the data flowing between them is called links. The width of each link is proportional to the quantity represented in Sankey view.
The Data Lineage Dashboard can be viewed in two ways:
- Flow View
- Sankey View
Flow View
The "Flow view" is a graphical representation of data lineage that provides a high-level overview of how data flows from one schema to another. It includes the following features:
- Schema Representation: In the flow view, data schemas or data sources are visually represented as boxes or nodes. These nodes indicate where the data originates or is stored.
- Arrows or Lines: Arrows or lines connect these schema nodes, indicating the direction of data flow. They show how data moves from one schema to another, providing a clear visual path.
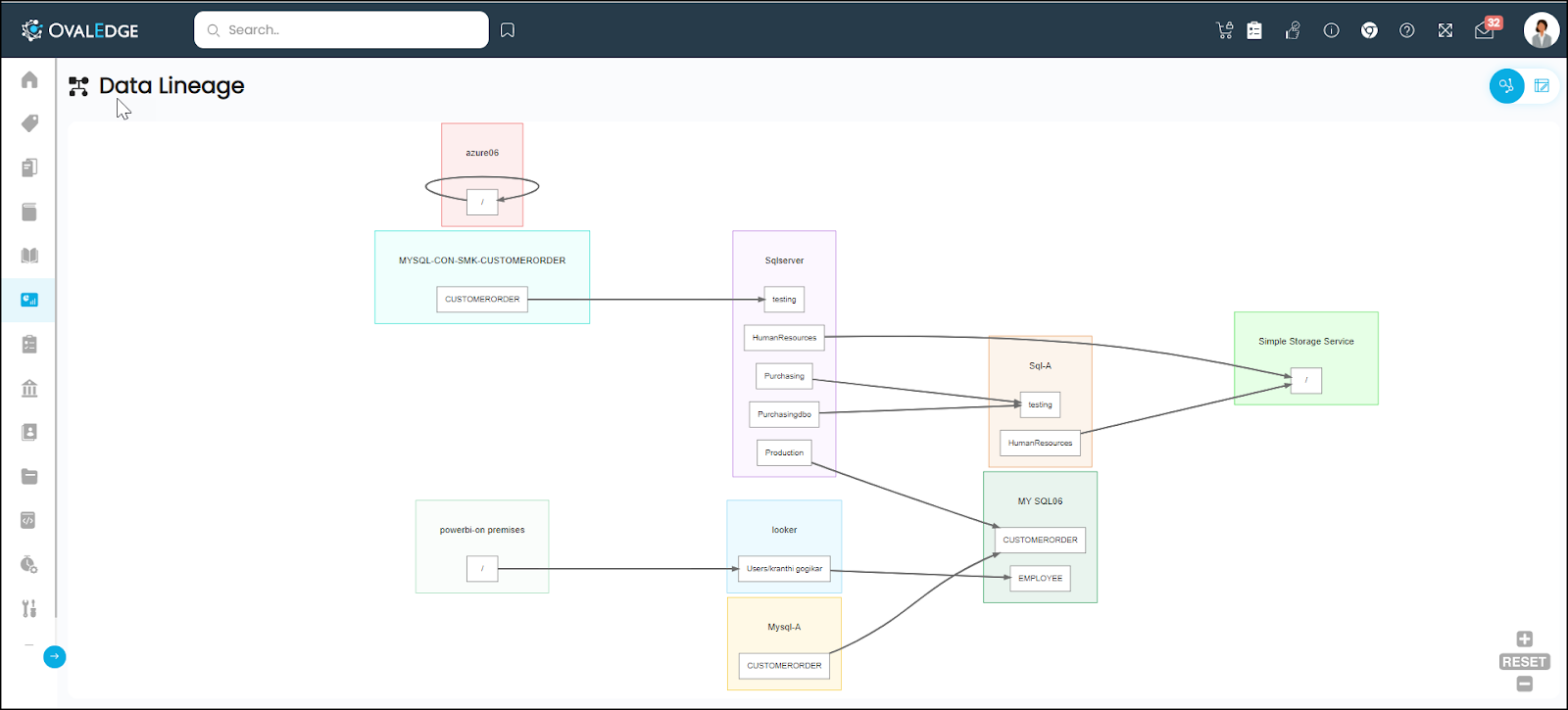
Sankey View
The "Sankey view" is a detailed lineage representation that offers a fine-grained view of data lineage, mapping data flow from schema to schema down to the column level. Here's how the Sankey view works:
- Sankey Diagram: A Sankey diagram is used to illustrate the complex flow of data between schemas. It consists of interconnected columns and flows, creating a detailed, network-like structure.
- Schema-to-Schema Flow: The Sankey view shows the journey of data as it moves from one schema to another. Users can trace data flow at this high level.
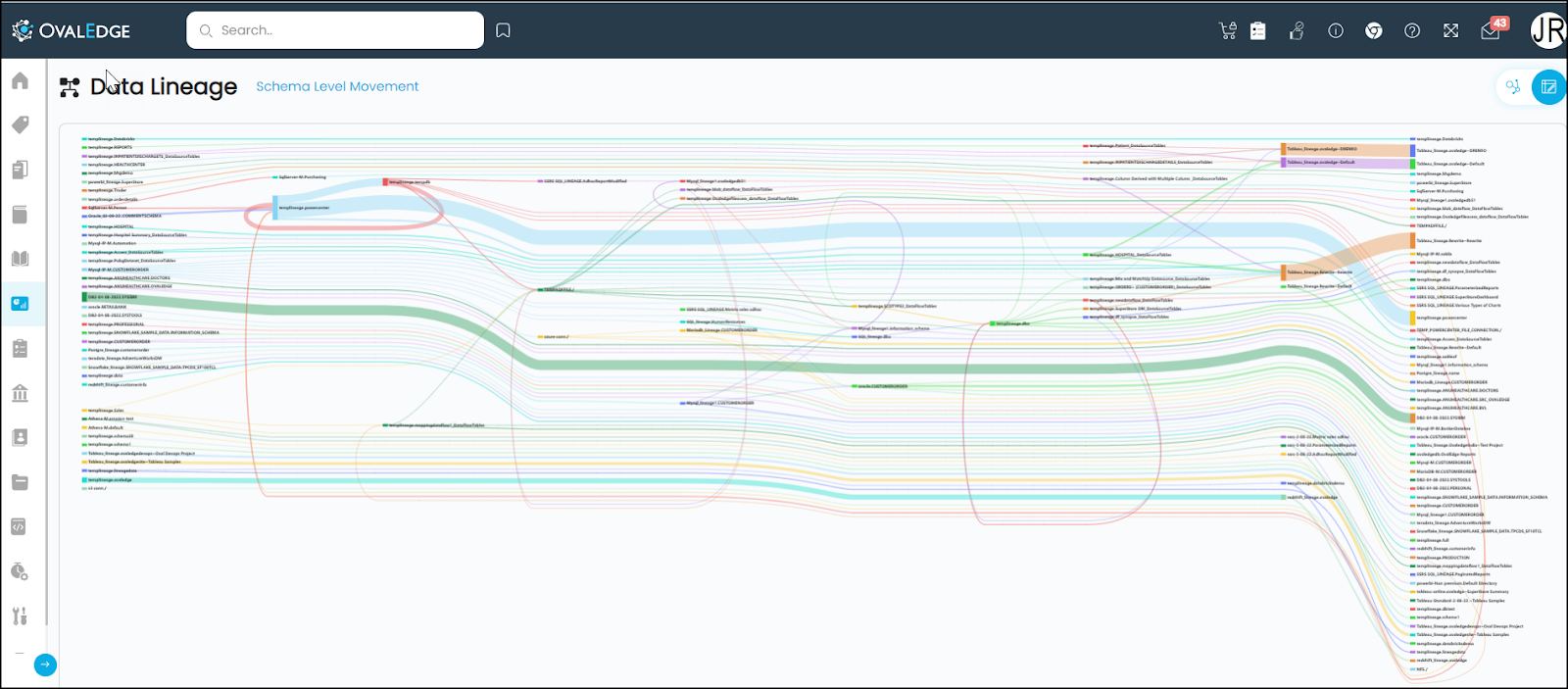
- Table-to-Table Flow : The view also explains the flow from one table to the other when the user clicks between any schema connection, It shows all the tables which have lineage between those 2 schemas.
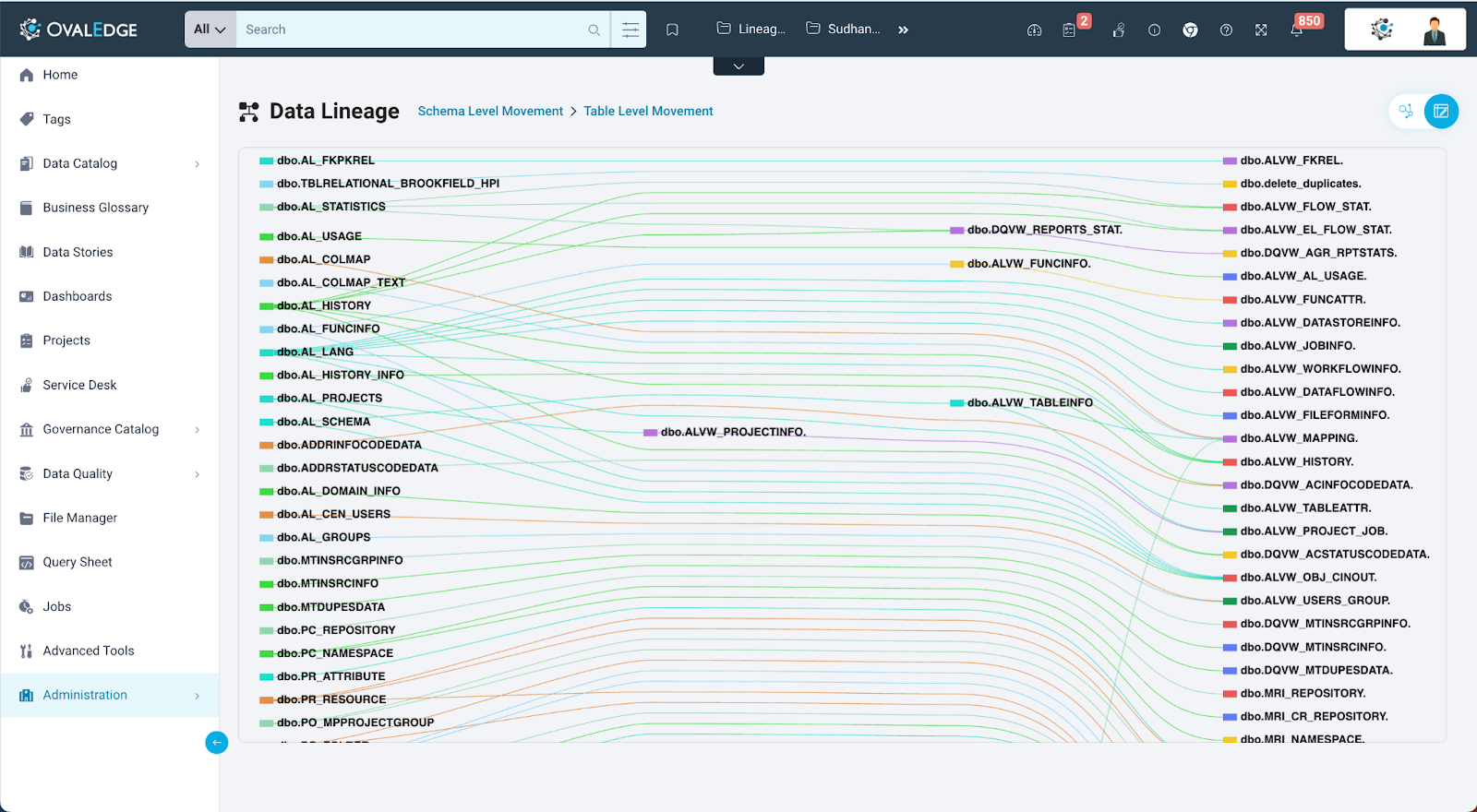
- Column-to-Column Flow: The view drills down to the column level, providing information about which specific columns in one schema relate to columns in another schema. It shows how data is transformed and mapped from one column to another.
- Data Mapping and Transformations: The Sankey view highlights data transformations and mapping operations with precision, offering insights into how data is processed throughout the lineage.
The Sankey view is especially valuable for users who require a granular understanding of data lineage. It helps in identifying specific columns, transformations, and potential data quality issues within the lineage.
In summary, the "Flow view" and "Sankey view" are two essential visual representations within the "Data Lineage" module of a dashboard. They offer different levels of detail and are used to understand how data flows between schemas, databases, and tables, providing users with a holistic view of data movement, transformations, and relationships in the system.