Crawling is a process of collecting information about data from various data sources like on-premise and cloud databases, Hadoop, visualization software, and file systems. When an OvalEdge crawler connects to a data source, it collects and catalogs all the data elements (i.e. metadata) and stores it in the OvalEdge data repository. The crawler creates an index for every stored data element, which can later be used in data exploration within the OvalEdge Data catalog which is a smart search. OvalEdge crawlers can be scheduled to scan the databases regularly, so they always have an up-to-date index of the data element.
Data Sources
OvalEdge crawler integrates with various data sources to help the users to extract metadata and build a data catalog. In this document, you can see how to make a connection to your SQL server instance and crawl the databases and schemas.
Connect to the Data
Before you can crawl and build a data catalog, you must first connect to your data. OvalEdge requires users to configure a separate connection for each type of data source. The users must enter the source credentials and database information for each type of connectivity. Once a data connection is made, a simple click of the Crawl button starts the crawling process.
Configure a new database connection
- Select the Administration tab and click on it to expand the functions.
- Select the Crawler.
- Click the New Connection from the Crawler window.
The dialog box for configuring a database connection is displayed.
Example: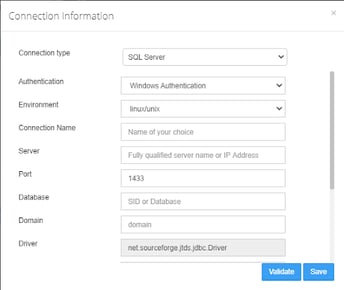
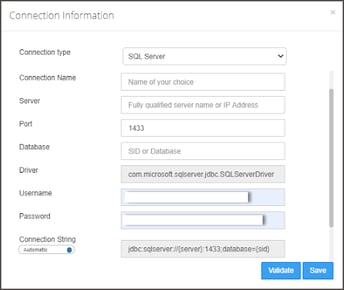
-
Select the Database type in the drop-down menu.
- Select the Authentication “Windows Authentication”.
- Select the Environment “linux/unix”.
-
Click Validate to test the database connection.
- When validation completes, click Save to finish the configuration of the database connection.
A dialog box that the database added successfully is displayed.
Connection details
|
Configuration |
Default/Sample value* |
Description |
|
Database Type |
SQL Server |
Select the database type from the list |
|
Authentication |
Windows Authentication |
This is the default authentication (Only for SQL server connection) |
|
Environment |
linux/unix |
OE Platform |
|
Connection Name |
Requires input |
Reference name for database identification in OvalEdge |
|
Hostname / Server |
Requires input |
Database instance URL(on-premises/cloud-based) ** |
|
Port Number |
Requires input Default 1433 |
Port number of the database instance |
|
Sid/Database |
Requires input |
A unique name that identifies the selected database (Only for SQL Server connection) |
|
Domain |
Requires input |
Domain name(on-premises/cloud-based) |
|
Driver Name |
net.sourceforge.jtds.jdbc.Driver |
jtds driver name for SQL server |
|
Username |
Requires input |
User account login credential. User account needs Read access on the remote server |
|
Password |
Requires input |
User Password |
|
Connection String |
jdbc:jtds:sqlserver://{server}:1433;database={sid};domain={domain} |
SQL server.This external jar jtds-1.3.1.jar will be configured in the application during installation.If SSL is enable, in the connection string ;ssl=require;NTLMv2=true should be added manually . |
*- Requires Client-specific input
Note: During the installation, a .dll file must be copied in the apache tomcat. This file will be provided by OvalEdge during installation.
Crawl a database connection
In OvalEdge, each data source can be crawled at a Schema level. In other words, when there are multiple schemas within a database, you have an option to select a specific schema and crawl.
To crawl a specific Schema or multiple schemas,
- Select the Administration tab and click the + button to expand the functions.
- Select the Crawler.
- Select a database from the list.
- Click the Crawl/Profile button on the crawler page.
The dialog box to select Important schema for crawling and Profiling is displayed.
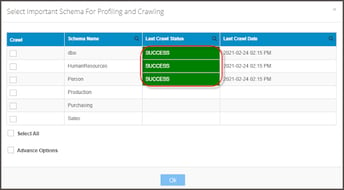
- Click the Checkbox next to the schema name and select a single schema or multiple schemas to crawl and profile.
- To crawl all schemas, click Select All.
- Click OK to initiate Crawling the database connection immediately.
Alternatively, select Advance options to schedule a Crawl and Profile action
later.
- A dialog box displays that a crawl job is Initiated.

- Select the Jobs tab in the object explorer(left side of the window) to know the status of the job submitted.
- Check the Job step status and click the Refresh button.
- INIT - The Job has been initiated.
- RUNNING - Jobs are being processed in the submitted order
- Waiting - Submitted Job is on Queue to get executed
- SUCCESS - An invoked task is completed successfully
- ERROR - The job has failed. Check error message in the Logs
- Hold - The initiated job has been kept on hold.
- KILLED - The initiated job has killed.
- PARTIAL SUCCESS- The initiated job has completed partially.
- Go to the Crawl window to check the Last Crawl Status of the selected Schemas.