This document outlines the integration with Microsoft SQL Server, enabling streamlined metadata management through features such as crawling, profiling, querying, data preview, and lineage building (both automatic and manual). It also ensures secure authentication via Credential Manager.
Overview
Connector Details
|
Connector Category |
RDBMS |
|
Connector Version |
6.3.4 |
|
Releases Supported (Available from) |
Legacy Connector |
|
Connectivity [How the connection is established with Microsoft SQL Server] |
JDBC driver |
|
Verified Microsoft SQL Server Version |
Microsoft SQL Server 2019 (15.0.4236.7) |
The Microsoft SQL Server connector has been validated with the mentioned "Verified Microsoft SQL Server Versions" and is expected to be compatible with other supported Microsoft SQL Server versions. If there are any issues with validation or metadata crawling, please submit a support ticket for investigation and feedback.
Connector Features
| Feature | Availability | |
| Crawling | ✅ | |
|
Delta Crawling |
❌ |
|
|
Profiling |
✅ |
|
|
Query Sheet |
✅ |
|
|
Data Preview |
✅ |
|
|
Auto Lineage |
✅ |
|
|
Manual Lineage |
✅ |
|
|
Secure Authentication via Credential Manager |
✅ |
|
|
Data Quality |
✅ |
|
|
DAM (Data Access Management) |
❌ |
|
|
Bridge |
✅ |
|
Metadata Mapping
The following objects are crawled from Microsoft SQL Server and mapped to the corresponding UI assets.
|
SQL Server Object |
SQL Server Attribute |
OvalEdge Attribute |
OvalEdge Category |
OvalEdge Type |
|
Table |
Table Name |
Table |
Tables |
Table |
|
Table Type |
Table |
Tables |
Table |
|
|
Table Comments |
Source Description |
Descriptions |
Source Description |
|
|
Columns |
Column Name |
Column |
Table Columns |
- |
|
Data Type |
Column Type |
Table Columns |
- |
|
|
Description |
Source Description |
Table Columns |
- |
|
|
Ordinal Position |
Column Position |
Table Columns |
- |
|
|
Length |
Data Type Size |
Table Columns |
- |
|
|
Views |
View Name |
View |
Tables |
View |
|
Text |
View Query |
Views |
View |
|
|
Procedures |
Routine_name |
Name |
Procedures |
- |
|
Description |
Source Description |
Descriptions |
- |
|
|
Routine_definition |
Procedure |
Procedures |
- |
|
|
Functions |
Routine_name |
Name |
Functions |
- |
|
Routine_definition |
Function |
Functions |
- |
|
|
Description |
Source Description |
Descriptions |
- |
|
|
Triggers |
Trigger Name |
Name |
Triggers |
- |
|
Trigger Definition |
Trigger Data |
Triggers |
- |
|
|
Trigger Type |
Type |
Triggers |
- |
Set up a Connection
Prerequisites
The following are the prerequisites to establish a connection:
External Supporting Files
|
File Name |
Description |
|
Jtds-1.3.1.jar |
Use this file when the application is deployed in a Linux or Unix environment. Place the file in the Third Party Jars directory. |
|
Ntlmauth.dll |
Use this file when the application is deployed in a Linux or Unix environment. Place the file in the Tomcat bin directory. |
|
Sqljdbc_auth.dll |
Use this file when the application is deployed in a Windows environment. Place the file in the Tomcat bin directory. |
The supporting files listed above are required for Windows authentication. Ensure that the correct supporting files are used based on the specific installation environment.
Whitelisting Ports
Make sure that inbound port “1433” is whitelisted to enable successful connectivity with the Microsoft SQL Server database.
The default port number for SQL Server is 1433. If a different port is used, ensure that the updated port number is specified during connection setup, the port is whitelisted, and communication between the system and SQL Server is properly established.
Service Account User Permissions
It is recommended to use a separate service account to establish the connection to the data source, configured with the following minimum set of permissions.
👨💻Who can provide these permissions? These permissions are typically granted by the Microsoft SQL Server administrator, as users may not have the required access to assign them independently.
|
Objects |
Access Permission |
|
Schema |
SELECT |
|
Tables |
SELECT |
|
Table Columns |
SELECT |
|
Views |
View Definition |
|
Functions & |
View Definition |
|
Triggers |
SELECT |
|
Synonyms |
SELECT |
|
Relationships |
SELECT |
Connection Configuration Steps
Users are required to have the Connector Creator role in order to configure a new connection.
- Log into OvalEdge, go to Administration > Connectors, click + (New Connector), search for SQL Server, and complete the required parameters.
Fields marked with an asterisk (*) are mandatory for establishing a connection.
|
Field Name |
Description |
||||||
|
Connector Type |
By default, "SQL Server" is displayed as the selected connector type. |
||||||
|
Connector Settings |
|||||||
|
Authentication |
OvalEdge supports the following three types of authentication for SQL Server:
|
||||||
|
OvalEdge Installed Environment |
Select the environment that OvalEdge has been installed in.
Note: This field will appear, when the authentication type is selected as Windows Authentication. |
||||||
|
Credential Manager* |
Select the desired credentials manager from the drop-down list. Relevant parameters will be displayed based on your selection. Supported Credential Managers:
|
||||||
|
License Add Ons |
|
||||||
|
Connector Name* |
Enter a unique name for the SQL Server connection (Example: "SQL Server_Prod"). |
||||||
|
Connector Environment |
Select the environment (Example: PROD, STG) configured for the connector. |
||||||
|
Server* |
Enter the SQL Server database server name or IP address (Example: xxxx-sqlserver.xxxx4ijtzasl.xx-south-1.rds.amazonaws.com or 1xx.xxx.1.x0). |
||||||
|
Port* |
By default, the port number for the SQL Server, "1433" is auto-populated. If required, the port number can be modified as per custom port number that is configured for your SQL Server. |
||||||
|
Database* |
Enter the database name to which the service account user has access within the SQL Server. |
||||||
|
Domain |
Enter the qualified SQL Server domain name. |
||||||
|
Driver* |
By default, the SQL Server driver details are auto-populated. |
||||||
|
Username* |
Enter the service account username set up to access the SQL Server database (Example: "oesauser"). Note: This field will be disabled only when the installation environment is selected as Windows. |
||||||
|
Password* |
Enter the password associated with the service account user. Note: This field will be disabled only when the installation environment is selected as Windows. |
||||||
|
Connection String |
Configure the connection string for the SQL Server database:
Replace placeholders with actual database details. {sid} refers to Database Name. |
||||||
|
Default Governance Roles |
|
|
Default Governance Roles* |
Select the appropriate users or teams for each governance role from the drop-down list. All users and teams configured in OvalEdge Security are displayed for selection. |
|
Admin Roles |
|
|
Admin Roles* |
Select one or more users from the dropdown list for Integration Admin and Security & Governance Admin. All users configured in OvalEdge Security are available for selection. |
|
No of Archive Objects |
|
|
No Of Archive Objects* |
This shows the number of recent metadata changes to a dataset at the source. By default, it is off. To enable it, toggle the Archive button and specify the number of objects to archive. Example: Setting it to 4 retrieves the last four changes, displayed in the 'Version' column of the 'Metadata Changes' module. |
|
Bridge |
|
|
Select Bridge* |
If applicable, select the bridge from the drop-down list. The drop-down list displays all active bridges configured in OvalEdge. These bridges enable communication between data sources and OvalEdge without altering firewall rules. |
- After entering all connection details, the following actions can be performed:
- Click Validate to verify the connection.
- Click Save to store the connection for future use.
- Click Save & Configure to apply additional settings before saving.
- The saved connection will appear on the Connectors home page.
Manage Connector Operations
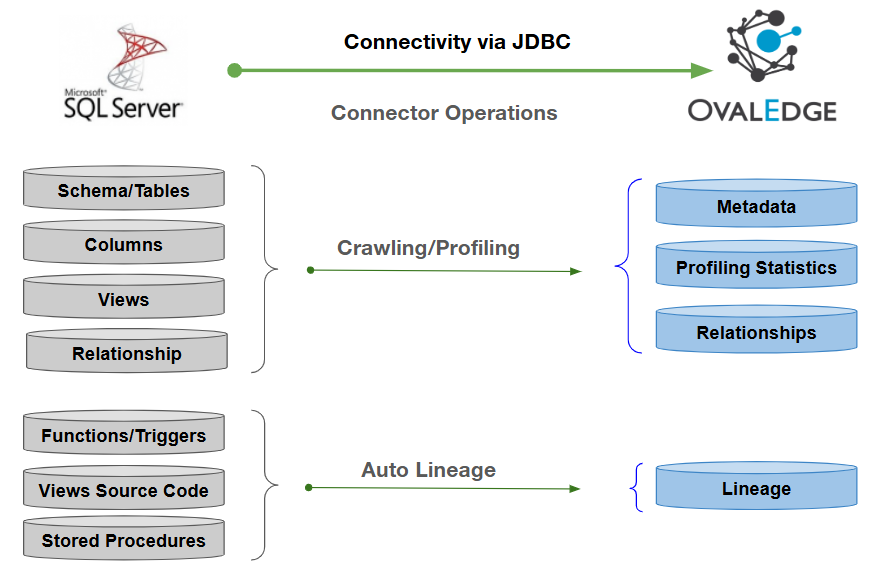
Crawl/Profile
To perform crawl and profile operations, users must be assigned the Integration Admin role.
The Crawl/Profile button allows users to select one or more schemas for crawling and profiling.
- Navigate to the Connectors page and click Crawl/Profile.
- Select the schemas you want to crawl.
- The Crawl option is selected by default. Click the Crawl & Profile radio button if you want both operations.
- Click Run to collect metadata from the connected source and load it into the OvalEdge Data Catalog.
- After a successful crawl, the information appears in the Data Catalog > Databases tab.
The Schedule checkbox allows automated crawling and profiling at defined intervals, from a minute to a year.
- Click the Schedule checkbox to enable the Select Period drop-down.
- Select a time period for the operation from the drop-down menu.
- Click Schedule to initiate metadata collection from the connected source.
- The system will automatically execute the selected operation (Crawl or Crawl & Profile) at the scheduled time.
Other Operations
The Connectors page in OvalEdge provides a centralized view of all configured connectors, including their health status.
Managing connectors includes:
- Connectors Health: Displays the current status of each connector using a green icon for active connections and a red icon for inactive connections, helping to monitor the connectivity with data sources.
- Viewing: Click the Eye icon next to the connector name to view connector details, including databases, tables, columns, and codes.
Nine Dots Menu Options:
To view, edit, validate, build lineage, configure, or delete connectors, click on the Nine Dots menu.
- Edit Connector: Update and revalidate the data source.
- Validate Connector: Check the connection's integrity.
- Settings: Modify connector settings.
- Crawler: Configure data extraction.
- Profiler: Customize data profiling rules and methods.
- Query Policies: Define query execution rules based on roles.
- Access Instructions: Add notes on how data can be accessed.
- Business Glossary Settings: Manage term associations at the connector level.
- Anomaly Detection Settings: Configure anomaly detection preferences at the connector level.
- Others: Configure notification recipients for metadata changes.
- Build Lineage: Automatically build data lineage using source code parsing.
- Delete Connector: Remove a connector with confirmation.
Connectivity Troubleshooting
If incorrect parameters are entered, error messages may appear. Ensure all inputs are accurate to resolve these issues. If issues persist, contact the assigned support team.
|
S.No. |
Error Message(s) |
Error Description & Resolution |
|
1 |
Error while validating connection: Exception occurred while validating in SQL Server Connection: Failed to obtain JDBC Connection; nested exception is com.microsoft.sqlserver.xxx.SQxxxxrException: Login failed for user 'xxxxx'. ClientConnectionId: 9xxxxx2-6xxx-4xx2-xx13-xxxx846xx |
Error Description: Either username and password might be wrong. Resolution: Ensure the correct username and password are entered in the setup form.Share feedback on the editor Verify the username format. Share feedback on the editor Confirm the user account is active. |
|
2 |
invalid DB Error while validating connection. Error:Exception occured while validating in SQL Server Connection: Failed to obtain JDBC Connection; nested exception is com.microsoft.sqlserver.xxx.SQLxxxException: Cannot open database "xxx" requested by the login. The login failed. ClientConnectionId:1xxxxx7a- xxxa-4xx9-bxxx-xxxxxx6bxxx7 |
Error Description: The database name provided is invalid. Resolution: Provided an incorrect database name in the setup form's Database Name field.Ensure that the database name is correctly spelled and exists in the target system. |
Copyright © 2025, OvalEdge LLC, Peachtree Corners GA USA