OvalEdge is a n-Tier web application that can be deployed on multiple infrastructure platforms like:
- Cloud based containerized infrastructure. AWS EKS, AWS Fargate, Azure AKS
- Cloud based VM environments. AWS EC2, Azure IaaS
- On-premise environments. Linux, Windows
On the AWS cloud, OvalEdge can be deployed using any one of the following options:
- Elastic Kubernetes Services
- Fargate
- EC2
The scope of this document is the deployment of OvalEdge on AWS EKS containerized environment.
Solution Architecture Overview
OvalEdge can be deployed as a single instance or as a cluster that hosts multiple pods of the OvalEdge platform, which perform the required activities to extract metadata of data and reporting entities from the configured data sources and process it to provide the stated functionality. The multi-pod architecture is targeted for high usage environments to provide horizontal scalability.
Data connectors on the system are configured on the system by the users to connect to the data sources and once done, the connectors are used to extract metadata on a periodic schedule in the form of jobs. Access to these data systems should be enabled on the network, both internal and external. The data jobs are distributed across the pod's set up to balance the load on the system. The number of pods can be varied based on the job load observed. Each pod is independent of the others and pods can be scaled up or down based on the load.
The metadata, processed data from the same, user-defined queries for data governance, data quality are stored in the OvalEdge database. Sensitive information like passwords is stored in non-human readable encrypted form. All the pods in a cluster are connected to one database instance.
Users have to access the system through the web portal. The user requests are distributed across the pods in the setup through a load balancer, to provide optimal response time. User authentication is single sign-on enabled through integration with the Active Directory services and other supported options.
The following diagram illustrates the logical architecture described.
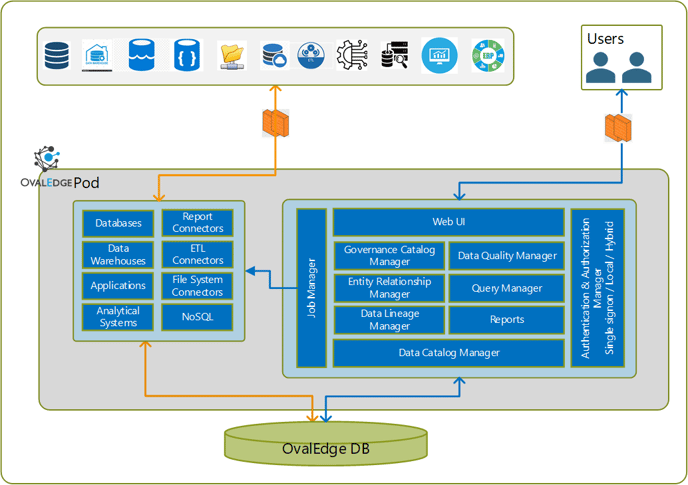
Reference Integration Architecture
AWS Cloud Platform
1. Reference Infrastructure Deployment Architecture
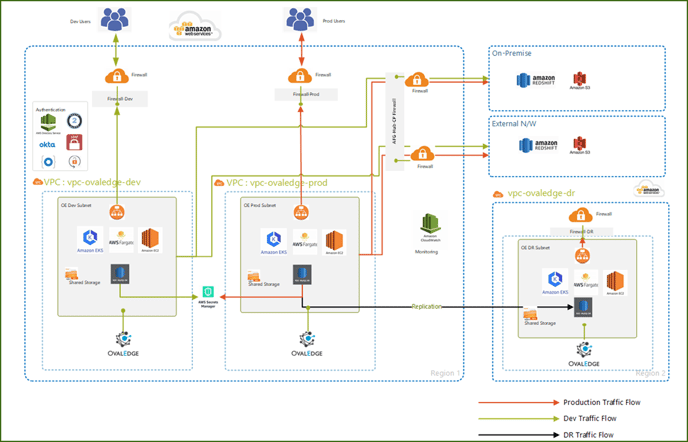
2. Pre-requisites
The following are the Prerequisites, hardware specifications, and deployment automation process used for AWS.
|
SNo |
Description |
|
1 |
AWS IAM user account Access permissions for EKS, RDS, Secrets Manager |
3. Reference Hardware Specifications
The below are the Solution Components and the required Sizing details based on the above NFR inputs.
|
Sl. |
Component |
Deployment Model |
Sizing Required |
Remarks |
|
1 |
AWS Elastic Kubernetes Services (EKS) |
PaaS |
t2.xlarge 2core 16GB RAM nodes x 730 Hours; Pay as you go; 2 General Purpose SSD (gp2) Volumes - 100GB, 0 clusters |
Basic specification |
|
2 |
AWS RDS MySQL |
Azure, PaaS |
Single Server Deployment, General Purpose Tier, 4 vCore x 730 Hours, 100 GB Storage, 0 GB Additional Backup storage - LRS redundancy |
|
|
3 |
AWS Firewall |
Azure, PaaS |
0 VM nodes x 730 Hours, 0 App Service nodes x 730 Hours, 0 SQL Database servers x 730 Hours, 0 Storage transactions, 0 IoT Devices, 0 IoT Message transactions, 64 Kubernetes vCores x 730 Hours |
Indicative specification |
|
4 |
AWS Secrets Manager |
Azure, PaaS |
10,000 operations, 10,000 advanced operations, 0 renewals, 0 protected keys, 0 advanced protected keys |
Indicative specification |
|
5 |
AWS Cloud Watch |
Azure, PaaS |
8 VMs monitored, 5 GB average log size, 90 additional days of data retention |
Indicative specification |
Note: The specification for Fargate and EC2 options will be similar to the EKS configurations, for multi-pod deployments.
4. Deployment Automation
The various deployment activities are detailed in the table below:
|
Deployment Activity |
Mode of Deployment |
Artifacts |
|
First Time Deployment |
Manual |
OvalEdge binary WAR file. SQL DDL scripts file for the database. Deployment YAML file. Helm chart deployment file (Optional). |
|
Upgrade |
Automated |
Docker image name |
|
Pod scale up / down |
Semi-automated |
Docker Image name |
|
Automated pod scaling |
Automated |
This is part of the roadmap. |
Scalability
The Vertical scalability for the OvalEdge instance can be achieved by increasing the H/W configuration of the node(s).
For horizontal scalability, OvalEdge supports the multi-pod deployment architecture provided by the cloud platforms. The number of pods in the deployment can be scaled up or down, through EKS to match the load. There are two pod configurations:
- User Pod. This pod configuration is for servicing user requests and can be scaled up or down based on the number of concurrent user loads. There should be a minimum of 1 pod.
- Job Pod. These pods are configured for executing the background jobs for data catalog building, data governance management, and other processing-intensive processes. There should be a minimum of 1 job pod.
High Availability
To handle disruptive scenarios, a disaster recovery deployment is recommended.
The default availability level is managed through the cloud service provider.
Backup services will be used for automated backup of OvalEdge application data in MySQL DB.
Monitoring & Alerting
The OvalEdge deployment can be monitored using :
- OvalEdge health check monitor, which is an in-built feature.
- AWS Cloud Watch or Azure Monitor.
- Prometheus exporter, which exports the monitoring data to a Prometheus server. This is integrated with the OvalEdge platform.
Copyright © 2019, OvalEdge LLC, Peachtree Corners GA US