Overview
The File Manager allows Author Users to manage files and folders. OvalEdge allows Author Users to connect to different file systems and quickly organize all folders and files on their local Network File System (NFS) server, Hadoop Distributed File System (HDFS), Microsoft Azure, and Cloud Storage Services like Amazon S3 or Google Cloud Storage.
With the File Manager, Author Users can efficiently organize every folder and file. It provides the ability to catalog folders and files, which Author Users can view in the Data Catalog. File Manager also can showcase different kinds of statistics about a file or folder in the module’s Folder Analysis section.
Data Lake Cataloging & Uploading
Using OvalEdge Connectors or Advanced Tools such as the Upload File or Folder, it is important to catalog data lakes before using the File Manager. This allows the user to view all the Files and Folders that exist in any particular Data Lake. There are various methods for adding files and folders to the File Manager.
Crawling Data Lake Connectors
OvalEdge works seamlessly with Data Lake Systems like Hadoop, Amazon S3, and Google Cloud Storage, specifically designed to store large amounts of unprocessed data in their original formats.
To connect OvalEdge with these File Systems, OvalEdge offers predefined connectors accessible on the OvalEdge Connectors page.
In the Administration section, Author Users can navigate to the Crawler module and add a new connection by entering the file system database name (NFS/S3/HDFS/MS Azure/Google Drive). The Manage Connection pop-up will appear, where Author Users must input, validate, and save connection credentials. After saving the connection, clicking the Crawl/Profile button in the Crawler section initiates the crawling process job. Upon successful completion, files are displayed in the File Manager module.
(Note: All files and folders in the file connection will be shown in the File Manager. However, only first-level folders and files will appear in Data Catalog > Files. Second-level files/folders from the file connection will be visible only in the File Manager. To view them in the data catalog the user will need to catalog the files/folders.
For example, in S3 > Hospital (First Level Folder) > Departments (Second Level Folder) > General Medicine (Third Level), the Hospital Folder will be automatically cataloged. Author Users can view it on the data catalog page. To catalog second, third, or other levels, Author Users must catalog them from the file manager.)
NFS - Upload Files or Folders
In addition to Data Lake Connectors, Author Users can manually upload files or folders via the NFS connection.
Within the File Manager module, Author Users can select the Data Lake (NFS connection) and click on the 9-Dots icon to access the ‘Upload’ option. The Upload File or Folder Page simplifies the uploading process, enabling Author Users to switch between uploading files and folders. Author Users can choose the file from their computer directory, start the upload, and create a new directory using the 9 Dots if needed. After a successful upload, the file is highlighted in green, signaling Author Users to click the Finish button.
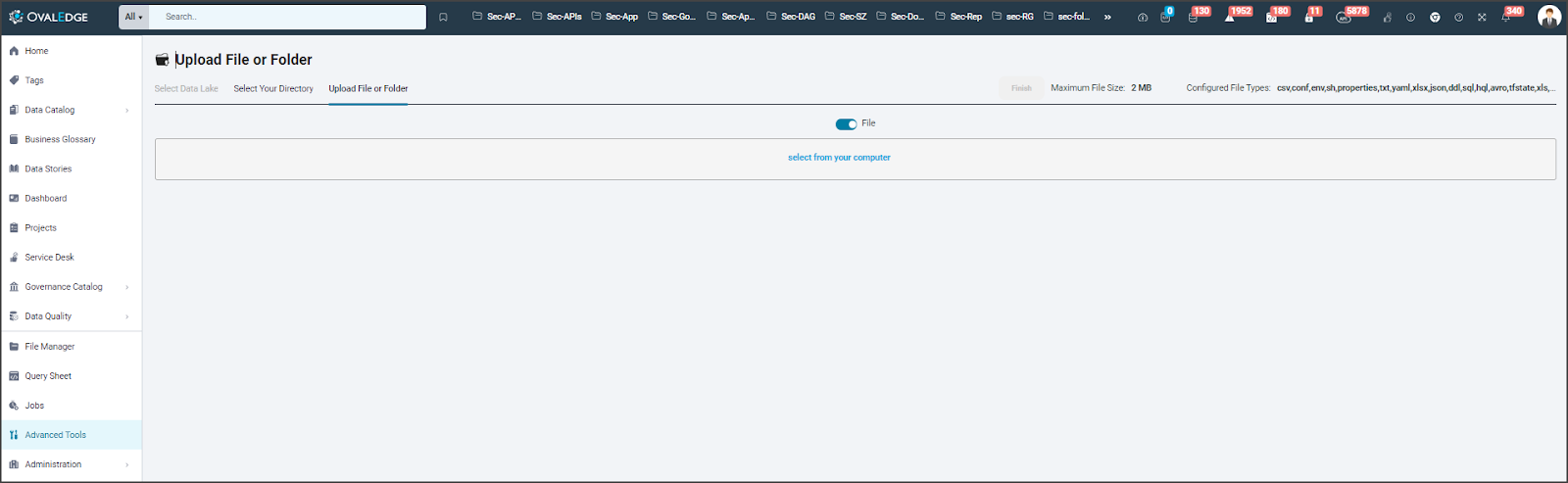
Supported Data Formats
The following are the data formats supported for the OvalEdge File Manager:
|
File Extension |
Format Supported |
Description of Format |
|---|---|---|
|
.csv |
Values Separated by Comma |
CSV (Comma-Separated Values) is a file format that stores tabular data in plain text. In a CSV file, each line represents a data record, and each record comprises one or more fields separated by commas. The file extensions commonly used for CSV files are .csv and .txt. |
|
.conf |
Plain Text |
A CONF (Configuration) file is stored in plain text format. CONF files are commonly used as configuration files in Unix and Linux systems. |
|
.ddl |
Plain Text |
A DDL (Data Definition Language) file is created in the Data Definition Language, which is used for describing database schemas. It is saved in plain text format and contains commands such as CREATE, USE, ALTER, and DROP for defining and managing database structures. |
|
.env |
Key-Value Pair |
The ".env" file extension is commonly associated with environment configuration files. These files often store configuration settings and sensitive information for applications. The content of a ".env" file typically consists of key-value pairs, where each pair represents a configuration variable and its corresponding value. |
|
.gz |
Gzip |
The '.gz' file extension is commonly associated with files that have been compressed using the gzip compression algorithm. This compression reduces the original file's size, making it more storage-efficient and facilitating faster transmission over a network. |
|
.hql |
Hive CLI |
Hive Query Language (HQL) scripts are typically saved with the ".hql" file extension. These scripts contain queries and commands that are used to interact with data stored in Hadoop through the Hive platform. Author Users can define tables, run queries, and perform various data manipulation tasks using HQL. |
|
.parquet |
Apache Parquet |
Parquet, part of the Apache Hadoop ecosystem, is a free and open-source column-oriented data storage format. Similar to other columnar-storage file formats in Hadoop, such as RCFile and ORC, Parquet is designed for efficient storage and processing of large datasets. |
|
.json |
JavaScript Object Notation |
A JSON (JavaScript Object Notation) file stores simple data structures and objects in the JSON format, a widely adopted standard for data interchange. Primarily used for transmitting data between web applications and servers, JSON files facilitate easy representation and parsing of data. |
|
.txt or .csv or .psv |
Pipe Delimited ( | ) |
A Pipe Delimited File, a type of delimited text file, is used to store data where each line represents a single entity (e.g., a book or company). Fields within each line are separated by a specific delimiter, often a pipe ('|'). This format offers flexibility by allowing field values of varying lengths, in contrast to flat files that use fixed-width spaces for each field |
|
.properties |
Plain Text |
A properties file in the context of Minecraft is a plain text file used to store configuration information for the server. This file is saved in a human-readable format, making it accessible for Author Users to manage and customize server settings. |
|
.sql |
Text |
The '.sql' file extension indicates a Structured Query Language (SQL) Data File. This plain text file stores SQL statements used for creating or modifying database structures, as well as performing operations such as insertions, updates, deletions, or other SQL transactions. |
|
.sh |
Text |
A file with the '.sh' extension is a script designed for the Unix shell. It comprises instructions written in the Bash scripting language and can be executed by typing a text command in the shell environment. |
|
.xls |
Microsoft Office Excel |
An XLS file, associated with Microsoft Office Excel, contains rows and columns of cells. Each cell can include various data types such as words, numbers, or formulas that dynamically solve equations. XLS spreadsheets may also feature tables and charts visualizing selected data sections. |
|
.xlsx |
XML Microsoft Office Excel |
A file with the .xlsx file extension is a Microsoft Excel Open XML Spreadsheet (XLSX) file created by Microsoft Excel. |
|
.tsv |
Tab Separated Values |
A tab-separated values file is a simple text format for storing data in a tabular structure, e.g., database table or spreadsheet data, and a way of exchanging information between databases. Each record in the table is one line of the text file. |
|
.txt |
Text |
A txt file is a standard text document that contains plain text. |
|
.yaml |
Text |
It is used for reading and writing data independent of a specific programming language |
|
.orc |
Apache ORC |
Optimized Row Columnar (ORC) files are commonly used in the Hadoop ecosystem, particularly with Apache Hive, as a storage format for structured data. They are designed to optimize query performance and reduce storage requirements in distributed data processing environments. |
|
.avro |
Apache Avro |
AVRO is a data serialization framework that facilitates the efficient exchange of data between systems. It is designed to be fast, compact, and versatile. AVRO supports a schema-based approach, allowing data to be self-describing, and it provides features like dynamic typing and schema evolution, making it suitable for scenarios where data structures may evolve. |
|
.class |
Java Source Code |
The ".class" file extension represents compiled Java classes, containing bytecode that is executed by the Java Virtual Machine. |
|
.zip |
ZIP |
ZIP is a popular archive file format that is widely used for compressing and packaging files and directories. It is a widely supported and versatile format, making it a standard choice for file compression and distribution. |
|
.html |
.html |
HTML, or Hypertext Markup Language, is the standard language for creating and designing web pages. It is a markup language that structures the content of a web page, defining elements such as text, images, links, forms, and more. |
|
.jar |
Java Archive |
A JAR (Java Archive) file is a standard file format used to aggregate and distribute Java classes, metadata, and resources. It is a compressed file format that simplifies the packaging of multiple Java files into a single archive, facilitating the distribution, deployment, and execution of Java applications and libraries. |
Note: OvalEdge does not support profiling for files with the following extensions: .class, .zip, .dll, .yaml, .sql, .html, .jar, and .txt.
Exploring Data Lakes
Accessing the File Manager module directs Author Users to the ‘Select Your Data Lake’ page, where available file connections are displayed alongside the connection type, the username of the creator/crawler, and the last modified date. This page enables Author Users to search for specific file connections by name and filter connections based on type using the search and filter icons provided within the respective columns.
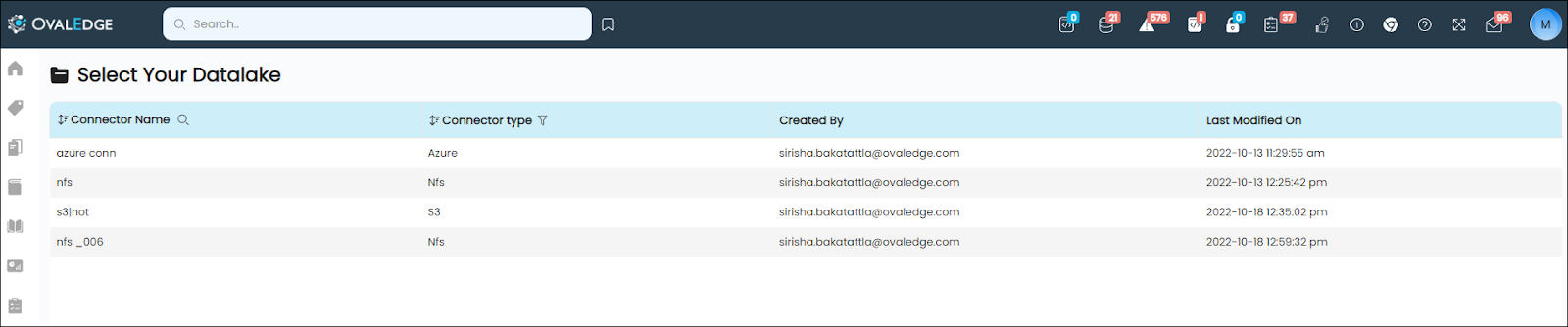
Author Users can choose the Connection Name from the existing Connector List, leading them to the File Explorer. On this page, all available files and folders within the selected connection are displayed.
File Explorer
In OvalEdge's File Explorer for each available Data Lake, the following information is collected and displayed for each connection:
- Type: Indicates whether the object is a File or a Folder.
- Name: The name of the file or folder from the connection.
- File Type: Displays the file type (e.g., .csv, .xlsx). For folders, the entry remains empty.
- Catalog: OvalEdge mandates Author Users to categorize each file or folder for efficient metadata management. Cataloging a file is a necessary step before profiling.
- Cataloging a File: The first level of data is automatically cataloged when creating a connection. The second level of data must be manually categorized using the ‘+’ sign for each file or folder in the file manager. Alternatively, Author Users can catalog multiple folders or files in the data catalog using the 9 Dots options.
- Size: Displays the physical size of a file in the system.
- Last Modified Date: This shows the date on which changes were made to the file or folder in the source system.
- Preview Link: Author Users can click on the given icon for the respective Folder or File to copy a link, which they can paste on another tab of the browser and view the object’s Data Catalog Summary Page.
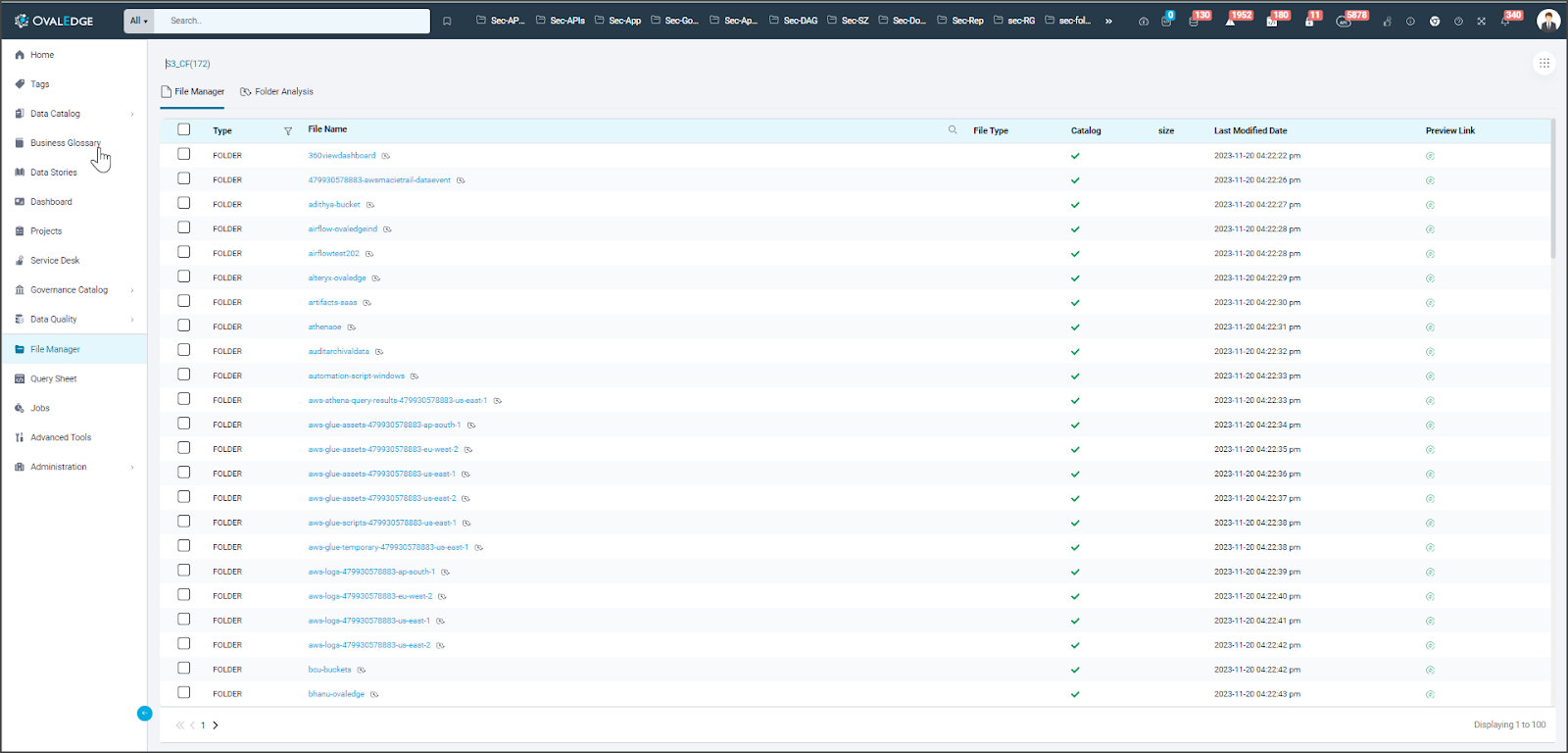
Exploring a Folder
Author Users can click the Folder Name in the File Explorer to view all the files and subfolders within the folder. The List Page of any particular folder shows similar data to the File Explorer page, with Type, Name, File Type, Catalog, Size, Last Modified Date, and Preview Link details.

User Actions in File Explorer
Author Users can perform various tasks on files and folders using the 9-Dots icon at the page's top right corner. The available options include View File, Download File, Upload File, Delete File, and Catalog Files/Folders.
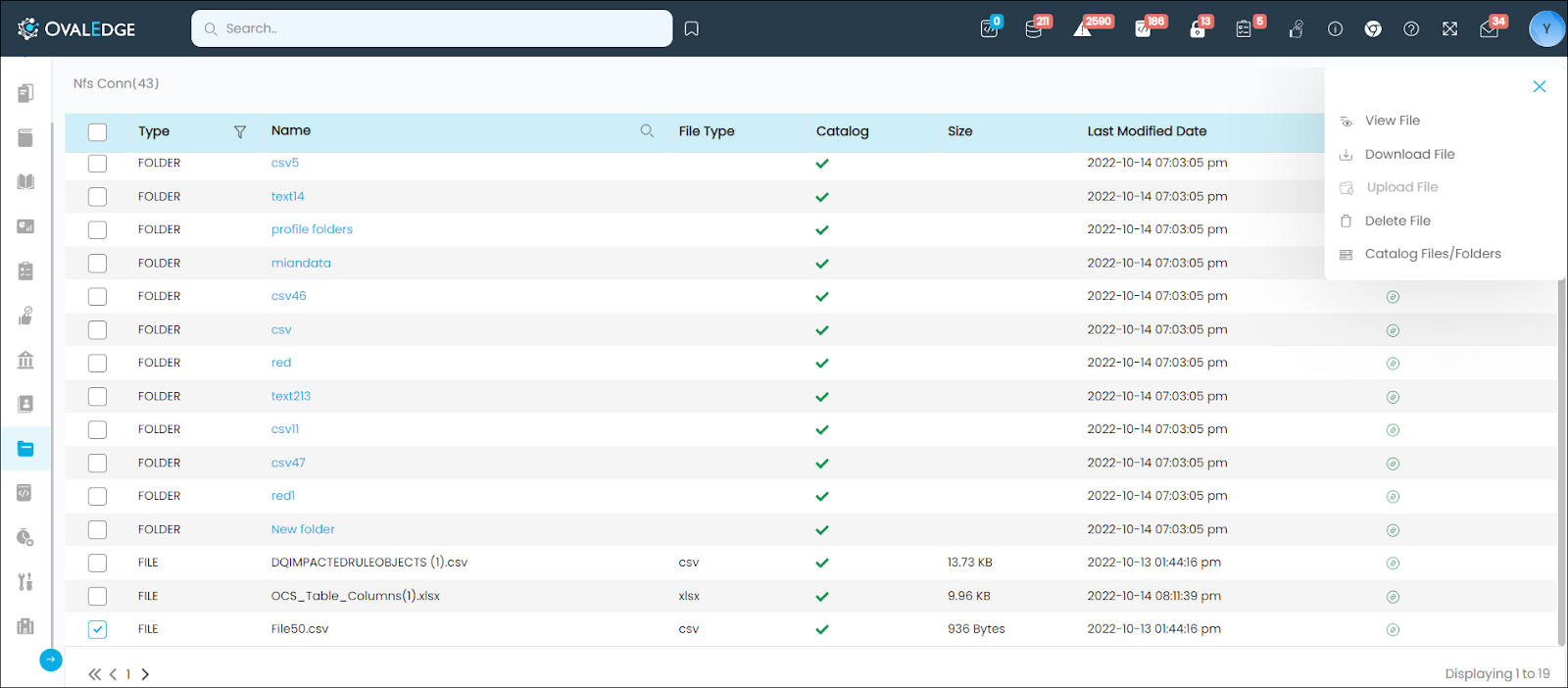
- View File: Author Users can preview the data contents of a file (.csv or .xlsx) in raw or table form by selecting this option.
- Raw View: Author Users can see data in unstructured format.
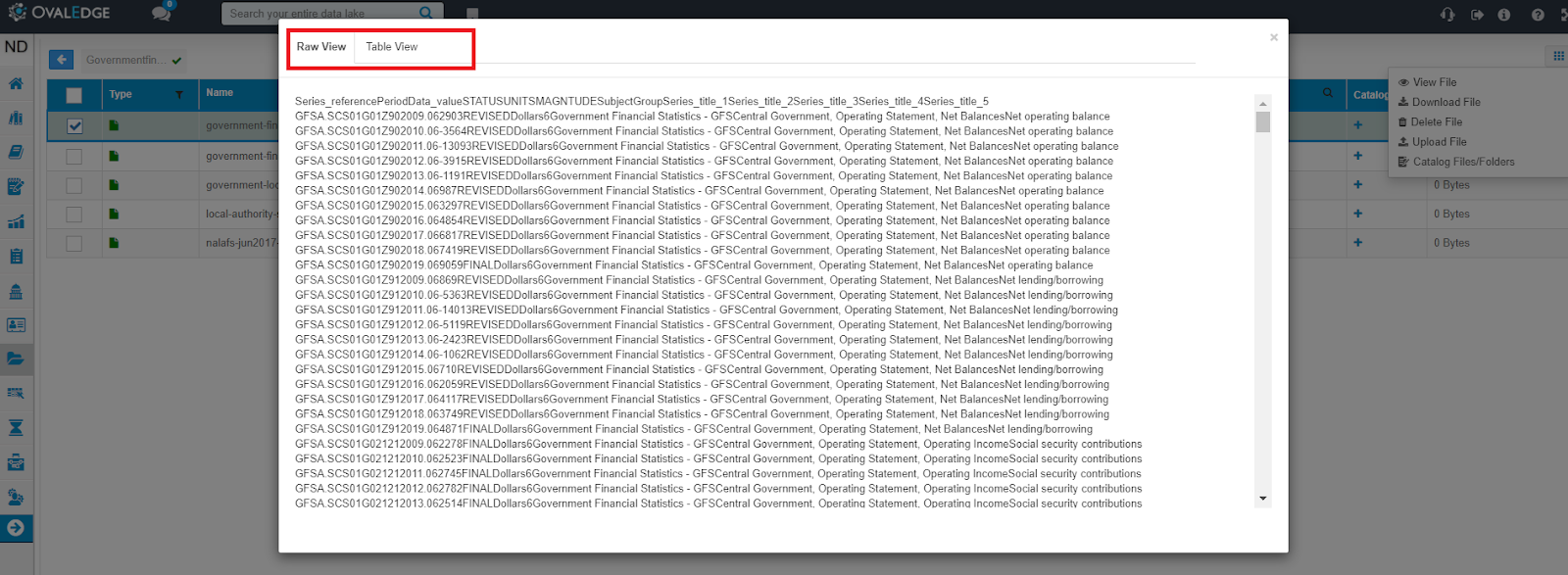
- Table View: Author Users can view available data in a structured format.
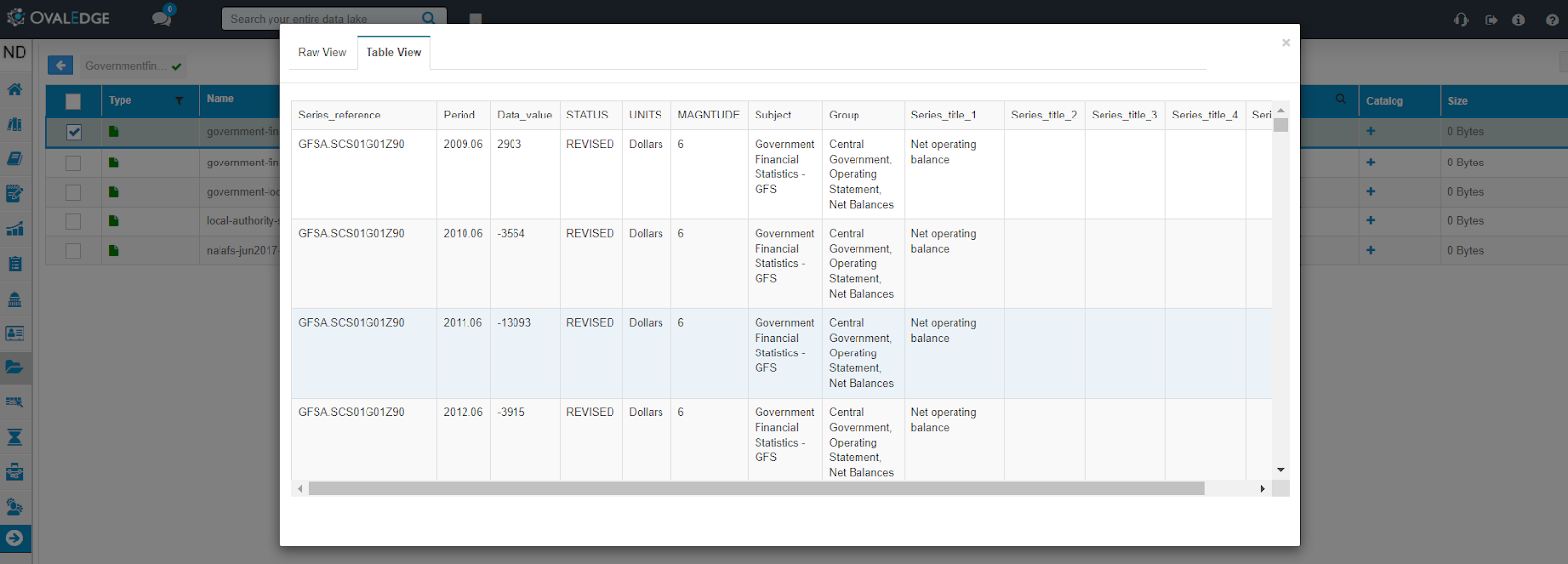
- Download File: Author Users can download the file uploaded in the File Manager.
- Delete File: This option enables Author Users to permanently delete uploaded files from OvalEdge. Deleted files cannot be recovered.
- Upload File: Author Users can upload a file to the File Manager by selecting the upload file/folder button. This option is available only for the NFS Connector.
- Catalog Files/Folders: Author Users can use this option to catalog files or folders, making them visible in the Data Catalog.
- Folder Analysis: This option allows Author Users to view a folder in the Folder Analysis or the, providing various analytical facts about a particular folder, for instance, the Folder Size or the File Count inside the Folder.
- Run Folder Analysis: This option allows Author Users to run the Folder Analysis job for a specific folder.
Folder Analysis
Folder Analysis provides Author Users with valuable insights into the composition and arrangement of a selected folder in a connector. This feature enables Author Users to fully understand the folder structure and extract important details about the files and folders it holds. It streamlines the process of understanding folder contents, empowering Author Users to make informed data management decisions efficiently. It can be considered a "light cataloging" feature.
Accessing Folder Analysis
To access the Folder Analysis tab in File Manager and Data Catalog, OvalEdge administrators must enable the following System Settings configuration in the ‘Others’ tab by changing the key value of enable.folder.analysis to ‘True’.
Once enabled, Author Users will be able to view the Folder Analysis tab in both File Manager and Data Catalog:
- File Manager: Author Users can view the Folder Analysis tab.
- Data Catalog: A separate tab will appear beside the Summary tab for any particular folder.
To navigate to the Folder Analysis, Author Users can take two paths:
- For All Folders in a File Connection: Author Users can navigate to the Folder Analysis tab of the particular connector to view the folder analysis of all folders.
- For a Specific Folder: Author Users can click on the 'View in Folder Analysis' icon next to the folder name in File Manager to view the folder analysis for that specific folder.
Running Folder Analysis
Author Users can initiate the Folder Analysis in three different ways:
- 9-Dots in File Explorer of File Manager: Within the 9-Dots user actions in File Explorer, Author Users have the option to 'Run Folder Analysis.' This allows them to run the folder analysis for any selected folder.
- Run Folder Analysis Button in Folder Analysis: In the Folder Analysis, Author Users can run the job by clicking on the 'Run Folder Analysis' button displayed.
- 9-Dots in File Summary View of Data Catalog: Within the 9-Dots user actions in the Files Summary of Data Catalog, Author Users have the option to 'Run Folder Analysis.' This allows them to run the folder analysis for any selected folder.
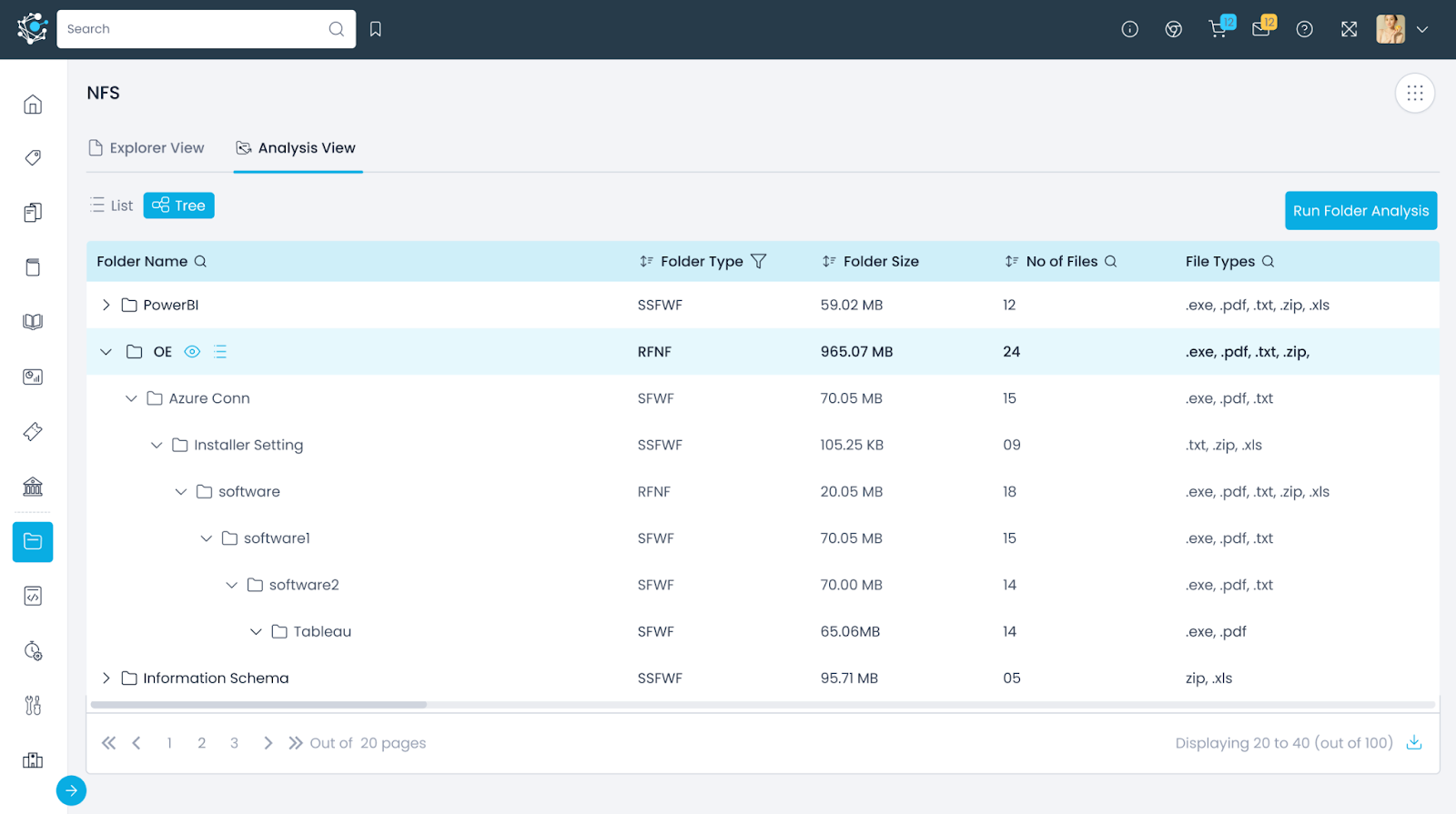
List View of Folder Analysis
After running Folder Analysis on a folder, Author Users can view various analytical details of that folder in the List View with the following details:
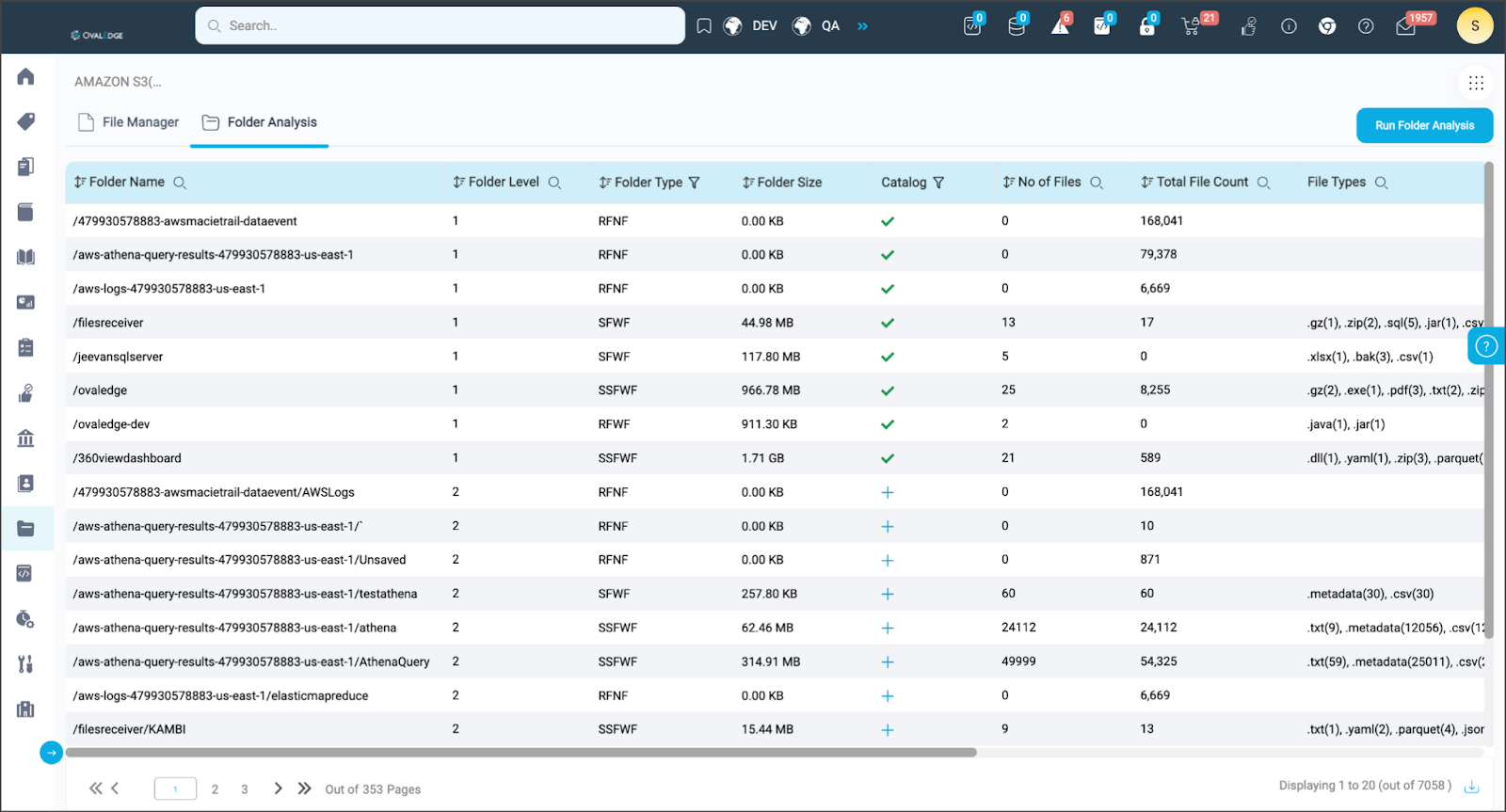
- Folder Name: Names of all folders and subfolders in a File System. If Author Users are viewing the folder analysis of a specific folder, it displays the sub-folders of that particular folder.
- Folder Level: Displays the folder level of any particular folder featured in the Folder Analysis tab. The main or first level of a folder is assigned a Folder Level of '1', the second level as ‘2’ and so on.
- Folder Type: Indicates the category the folder falls into, with five defined categories:
- RFWF - Regular Folder with Files
- RFNF - Regular Folder with No Files
- SFWF - Structured Folder with Files
- SSFWF - Semi-Structured Folder with Files
- UFWF - Un-Structured Folder with Files
- Folder Size: Displays the size of the folder in kilobytes (KB).
- Catalog: Shows the option for Author Users to catalog a folder.
- Number of Files: Displays the number of files in that particular folder, excluding files in its subfolders.
- Total File Count: This shows the total number of files in that particular folder, including files in its subfolders.
- File Types: Displays the different types of files present in that particular folder, such as .ddl, .yaml, .parquet, and .csv.
- File Sizes (KB): It displays the number of files below a certain size limit, between two size limits, and above a certain size limit.
- Is Encrypted: Indicates whether the folder is encrypted in the source.
- Sample Files: Shows a selection of sample files from the folder.
File Analysis
Additionally, the Folder Analysis provides a concise analysis of the files within the folders. Clicking the ‘Eye’ icon next to the Folder Name reveals a pop-up with specific details of the files inside it:
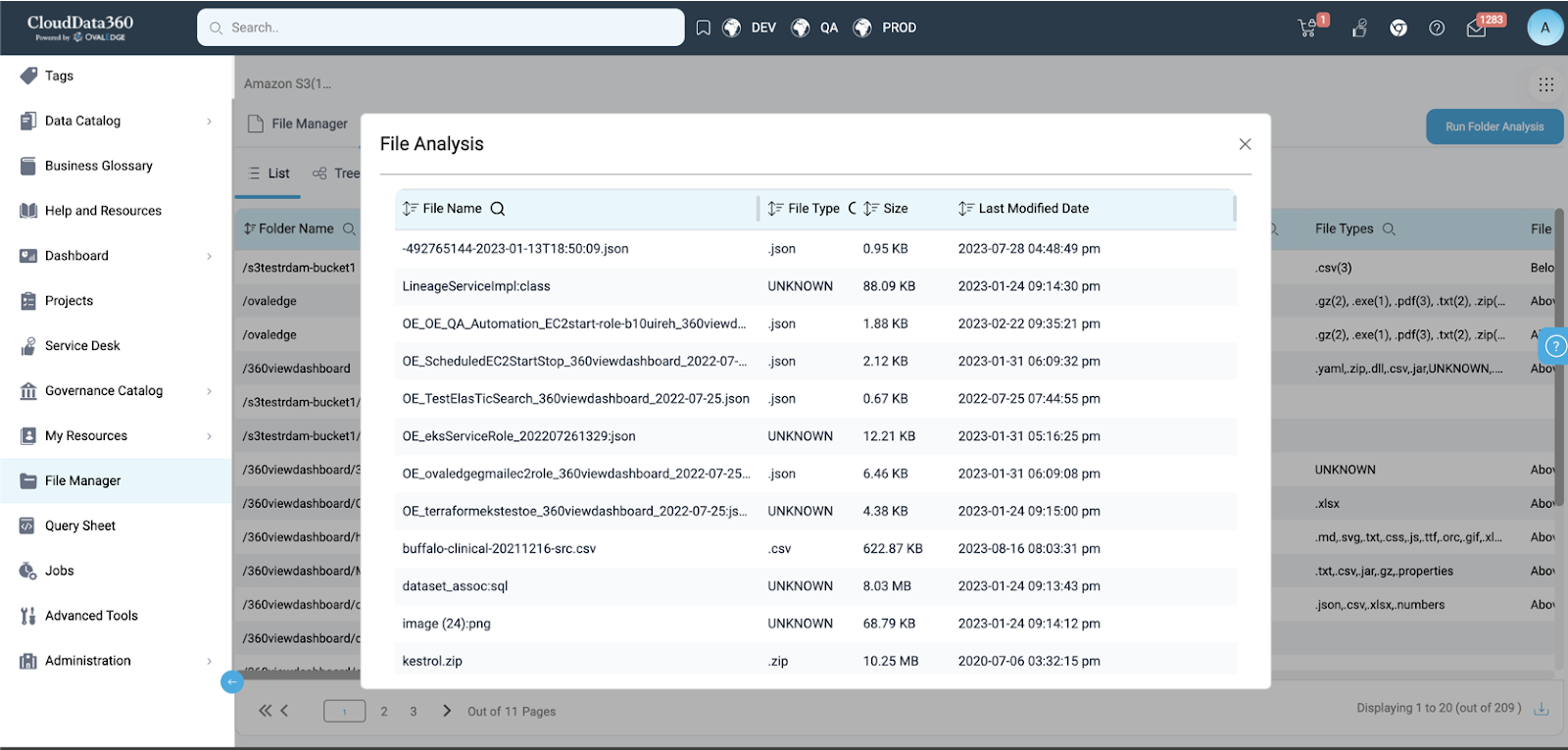
- File Name: Displays all the file names existing in that particular folder.
- File Type: Shows the type of file, such as .json, .csv, .zip, etc.
- Size: Displays the size of the file in kilobytes (KB).
- Last Modified Date: This shows the latest date when the file was modified at the source system. The change of this date will be reflected when the admin will re-catalog the Data Lake.
Quick & Easy Discovery of Analysis
Folder Analysis List View provides an easy-to-navigate tabular format that enhances comprehension of data objects by providing filters, search options, and sorting capabilities.
- Filter: A drop-down menu provides attribute options for narrowing down search results. For each column, Author Users can select a predefined filter option. Additionally, the search bar can be used to find particular column filter attributes.
- Search: The search filter helps Author Users locate the desired data objects within the extensive data ecosystem. An additional Conditional search button, represented by the eight dots icon next to the search field, allows Author Users to further refine search results by excluding or including keywords.
- Sort: Author Users can arrange data objects in ascending or descending order. After sorting the first column, the remaining columns can also be sorted.
By using these options, Author Users can effectively navigate and explore folder analysis, enhancing their discovery process based on the types of data displayed within the columns.
Tree View of Folder Analysis
The Tree View, as the name suggests, provides Author Users with the additional functionality of drilling down into the 1st level of folders and sub-folders inside it. Author Users can drill down or drill up on the folder analysis of any folder, accessing all the available details similar to the List View.
System Settings of File Manager
The System Settings for File Manager are designed to provide administrators and Author Users with the flexibility to configure the behavior and display of the File Manager. These settings enable Author Users to tailor their search experience, control the visibility of certain features, and fine-tune the search parameters according to their specific requirements. These settings can be configured from the Administration> System Settings > Others tab.
|
Key |
Value |
Description |
|
config.file.types.to.be.cataloged |
avro, csv, xlsx, xls, parquet, json, sql, txt, yaml |
The default value is csv,conf,env,sh,properties,txt,yaml, xlsx,json,ddl,sql,hql,parquet. Specify the file type formats that are allowed for cataloging. |
|
config.folder.enable.folder.analysis. |
true |
If the folder type is true only the folder analysis option will turn on enable mode. |
|
ovaledge.filesize.limit |
2097152 |
Specify the maximum size of uploaded files(in bytes). |
|
ovaledge.fileupload.maxfiles |
10 |
Specify the maximum number of files that can be uploaded to the OvalEdge Application. Parameters: The default value is 10. Enter any Value in the field provided. |
|
filemanager.pagination.row.limit |
100 |
Define the maximum number of records of files in the File Manager. Parameters: The default value is 100. Enter the value in the field provided. |