OvalEdge uses a JDBC driver to connect to the data source, which allows users to Crawl and Profile data objects (Tables, Table Columns, etc.), execute Queries, and build lineage.
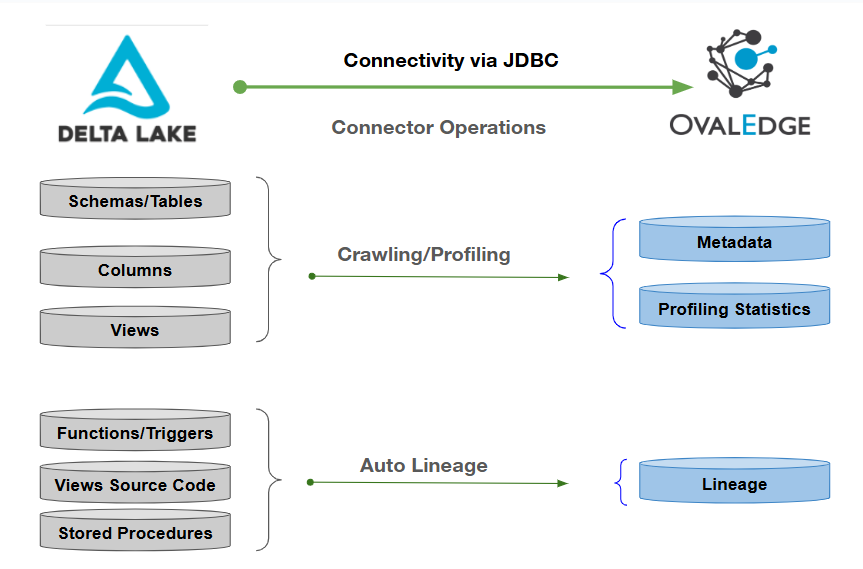
Overview
Connector Details
|
Connector Category |
RDBMS System |
|
Connector Version |
6.3.4 |
|
OvalEdge Releases Supported (Available from) |
Release6.0 onwards |
|
Connectivity [How OvalEdge connects to Delta Lake] |
JDBC |
Connector Features
| Crawling |
✅ |
|
| Delta Crawl |
❌ |
|
| Profiling |
✅ |
|
| Query Sheet |
✅ |
|
| Data Preview |
✅ |
|
| Auto Lineage |
✅ |
|
| Manual Lineage |
✅ |
|
| Authentication via Credential Manager |
✅ |
|
| Data Quality |
✅ |
|
| DAM (Data Access Management) |
❌ |
|
| Bridge |
✅ |
|
Getting Ready to Establish a Connection
Prerequisites
The following are the prerequisites to establish a connection between Delta Lake and OvalEdge:
Service Account User Permissions
|
Important: We recommend having a separate service account to establish a connection from OvalEdge to the data source with minimal permissions. |
|
Operation |
Access Permission |
|
Connection Validation |
SELECT |
|
Crawl Schemas |
SELECT |
|
Crawl Tables |
SELECT |
|
Profile Schemas, Tables |
SELECT |
|
Lineage Building |
SELECT |
Note: To fetch the System Views from the data source, the Service Account user needs to have Read Access to the Public Synonyms.
Setup a Connection
|
Important: You must have the Connector Creator role to set up a connection in OvalEdge. |
- Log into OvalEdge, navigate to Administration > Connectors, click + (New Connector), search for Delta Lake, and complete the specific parameters.
Note: Fields marked with an asterisk (*) are mandatory for establishing a connection.
Field Name
Description
Connector Type
By default, "Delta Lake" is displayed as the selected connector type.
Connector Settings
Authentication*
OvalEdge supports the following two types of authentication for Delta Lake:
- Personal Access Token
- Service Principal
Credential Manager*
Select the desired credentials manager from the drop-down list. Relevant parameters will be displayed based on your selection.
Supported Credential Managers:
- OE Credential Manager
- AWS Secrets Manager
- HashiCorp Vault
- Azure Key Vault
License Add Ons
Auto Lineage
Supported
Data Quality
Supported
Data Access
Not Supported
- Select the checkbox for Auto Lineage Add-On to build data lineage automatically.
- Select the checkbox for Data Quality Add-On to identify data quality issues using data quality rules and anomaly detection.
Connector Name*
Enter a unique name for the Delta Lake connection
(Example: "Delta Lake_Prod").
Connector Environment
Select the environment (Example: PROD, STG) configured for the connector.
Client id*
Enter Client ID.
Note: This field is available when the authentication mechanism is set to Service Principal.
Client secret*
Enter Client Secret.
Note: This field is available when the authentication mechanism is set to Service Principal.
Server*
Enter the Delta Lake database Server name or IP address.
Port*
By default, the port number for the Delta Lake database "443" is auto-populated. If necessary, you can change this to a different port number.
Database Type*
Select the database type from the drop-down list:
- Deltalake_Regular
- Deltalake_Unity_Catalog
Database*
Enter the database name associated with the data type.
Driver*
By default, the Delta Lake driver details are auto-populated. OvalEdge artifacts include the required drivers for supported databases.
Http Path*
Enter the HTTP Path associated with Delta Lake and it helps in connecting with the legacy-specific cluster or with the warehouse.
Example: sql/protocolv1/o/781181XXXXXXX/0717-094118-bathe927
Lineage Fetching Mode*
Choose the mode for retrieving and displaying lineage details in OvalEdge by selecting either Query or API.
Username*
Enter the service account username set up to access the Delta Lake database (Example: "oesauser").
Note: This field is available when the authentication mechanism is set to Personal Access Token.
Password*
Enter the password associated with the service account user. (Example: "password").
Note: This field is available when the authentication mechanism is set to Personal Access Token.
Connection String
Configure the connection string for the Delta Lake database:
- Automatic Mode: The system generates a connection string based on the provided credentials.
- Example (Delta Lake):
jdbc:databricks://{server}:443/{sid};AllowSelfSignedCerts=1;transportMode=http;ssl=1;AuthMech=3;httpPath={httppath}
- Manual Mode: Manually enter a valid connection string.
Default Governance Roles
Default Governance Roles*
Select the appropriate users or teams for each governance role from the drop-down list. All users and teams configured in OvalEdge Security are displayed for selection.
Admin Roles
Admin Roles*
Select one or more users from the dropdown list for Integration Admin and Security and Governance Admin. All users configured in OvalEdge Security are available for selection.
No of Archive Objects
No Of Archive Objects*
It indicates the number of recent metadata changes to a dataset at the source. By default, it is off. You can enable it by toggling the Archive button and specifying the number of objects to archive.
Example: Setting it to 4 retrieves the last 4 changes, shown in the 'version' column of the 'Metadata Changes' module.
Bridge
Select Bridge*
If applicable, select the bridge from the drop-down list.
The drop-down list displays all active bridges configured in OvalEdge. These bridges enable communication between data sources and OvalEdge without altering firewall rules.
- After entering all connection details, you can perform the following actions:
- Click Validate to verify the connection.
- Click Save to store the connection for future use.
- Click Save & Configure to apply additional settings before saving.
- The saved connection will appear on the Connectors home page.
Connectivity Troubleshooting
If incorrect parameters are provided, you may encounter error messages. To resolve these issues, ensure all input is correct. If problems persist, contact your assigned OvalEdge support team.
|
S.No. |
Error Message(s) |
Error Description / Resolution |
|
1 |
Failed to establish a connection; please check the credentials |
Invalid credentials provided or user or role does not have access. |
|
2 |
java.sql.SQLException: [Simba][SparkJDBCDriver](500593) Communication link failure. Failed to connect to the server. |
Invalid credentials or token expired |
Manage Connector Operations
Crawl/Profile
|
Important: You must have the Integration Admin role in OvalEdge for crawl/profile operations. |
A Crawl/Profile button allows you to select one or more schemas for crawling.
- Navigate to the Connectors page and click Crawl/Profile. It allows you to select the schemas that need to be crawled.
- The crawl option is selected by default.
- Click on the Run button, which gathers all metadata from the connected source and puts it into the OvalEdge Data Catalog. After a successful crawl, all the information is displayed in the Data Catalog > Databases tab.
Other Operations
The Connectors page in OvalEdge provides a centralized view of all configured connectors, including their health status.
Managing connectors includes:
- Connectors Health: Displays performance with a green (active) or red (inactive) icon, helping monitor data flow and address issues early.
- Viewing: Shows connector details (e.g., Databases, Tables, Table Columns, Codes, etc) via the View icon.
Nine Dots Menu Options:
You can view, edit, validate, and delete connectors using the Nine Dots menu.
- Edit Connector: Update and revalidate the data source.
- Validate Connector: Check the connection's integrity.
- Settings: Modify connector settings.
- Crawler: Configure data that needs to be extracted.
- Profiler: Customize data profiling rules and methods.
- Query Policies: Define rules for executing queries based on roles.
- Access Instructions: Specify how data can be accessed as a note.
- Business Glossary Settings: Manage term associations at the connector level.
- Anomaly Detection Settings: Configure anomaly detection preferences at the connector level.
- Others: Configure notification recipients for metadata changes.
- Build Lineage: Automatically build data lineage using source code parsing.
- Delete Connector: Remove connectors with confirmation.
Metadata Mapping
|
Source Object Name |
OvaEdge Data Object |
OvalEdge Data Object Type |
|
Schemas |
Schemas |
- |
|
Tables |
Tables |
Table |
|
Columns |
Columns |
Column |
|
Views |
Tables |
View |
|
Functions |
Codes |
Function |
|
Triggers |
Codes |
Trigger |
|
Stored Procedures |
Codes |
Procedure |
Copyright © 2025, OvalEdge LLC, Peachtree Corners GA USA