In OvalEdge, Classification refers to the process of categorizing data objects based on their sensitivity, confidentiality, and importance to an organization. This categorization helps to define appropriate access levels, security controls, and data handling procedures to ensure compliance with regulations and protect sensitive information.
Organizations are given the flexibility to customize their own classifications based on the business needs. This typically involves labeling data objects according to predefined levels such as PII, Public, Internal use only, Confidential, Highly sensitive, etc. Or, in the case of a privacy domain for PII terms, labels to regulations themself (i.e GDPR, CCP, HIPAA, etc.).
These labels guide employees on how to handle the data, who can access the data, and the level of protection the data requires. Effective data classification is fundamental for maintaining data integrity, safeguarding against unauthorized access, and ensuring data is used and shared responsibly within an organization.
Walkthrough Data Classification in OvalEdge
Data Classification leverages the Business Glossary Terms to classify cataloged data objects. The classifications are configured at the domain level and are automatically linked to the terms created within that domain. When data objects are linked to a term, the classifications at the term level are expanded and assigned to those data objects. Consequently, data objects associated with a specific term are marked with the corresponding classification.
Configuring Classifications at Domain Level
Navigating Domain Security
At the core of OvalEdge's data classification system is the concept of domains. Each domain serves as a container for terms and their associated data. At the domain level, users can configure various classifications, such as "public", "private", "sensitive", "GDPR", "CCPA”, and so on. The roles configured as domain admins (System Settings) can configure classification as per their requirement by accessing the Administration > Security > Domains Security. Setting a default classification streamlines the classification process, ensuring that terms within the domain and their associated data objects automatically inherit the defaulted classifications.
|
Note: Default checkboxes are provided for every classification configured to activate the functionality. When these checkboxes are unchecked at the domain level, the classifications configured are transferred to the term level but remain inactive. Enabling the checkboxes is essential for the system to apply term classifications to associated data objects, ensuring data labeling and management functions correctly. |
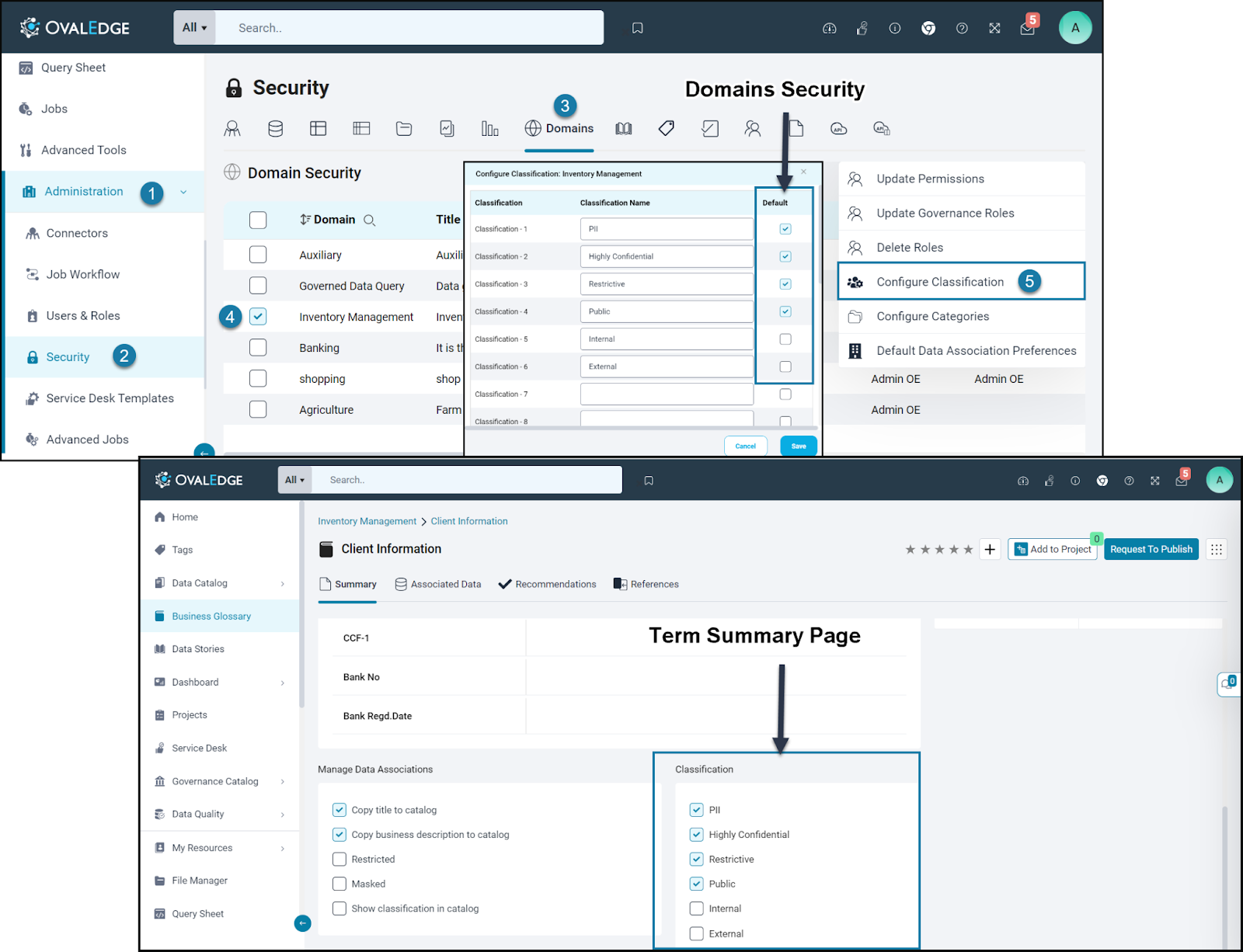
Configuring Classifications at Term Level
Every term automatically inherits the classification options set at the domain level. The system offers flexibility, enabling users to set classifications at the individual term level. This means that stakeholders can review the inherited classifications and, if needed, modify them to accurately reflect the sensitivity and nature of the data for that term. Users can easily activate or deactivate classifications by checking or unchecking the corresponding checkboxes.
- When checkboxes are selected, all data objects associated with the term adopt the configured classifications.
- If the checkboxes for classifications remain unchecked, the respective classifications won't be applied to the data objects.
- In the Term Summary screen, the User needs to check "Show classification in the catalog" to view the classification of objects.
Navigating Term Properties
|
Note: The term must be in "draft" status to make any edits to the term Classifications configured at the domain level. Initially, when a new term is created within a domain, the domain-level classifications are automatically linked to the term. Even if the term is associated with multiple data objects, these classifications won't be applied to the data objects while the term remains in draft status. To associate the term's classifications with the associated data objects, it is necessary to publish the term. When a published term is transitioned back into draft status for further modifications, the classifications remain linked to the data objects until the latest changes are made and published. Upon publication with new modifications, the term will then reflect the updated classifications. |
Imagine a "Customer" domain where default classifications - "Public," "Confidential," and "PII" are configured. Within this domain, various terms are created including "Customer Name," "Customer Address," and "Customer Aadhar Number".
- For the Term - "Customer Name”, it naturally inherits all the domain-level classifications. Since customer names typically don't pose data risks, users can uncheck "Confidential" and "PII" classifications.
- On the other hand, for "Customer Address" and "Customer Aadhar Number," users must consciously select "PII" or "Confidential." This highlights that this data is private and sensitive, with restricted access for authorized users only.
This flexibility allows users to choose or remove preferred classifications at the term level based on the term’s scope or the magnitude of associated data object’s sensitivity.
Editing Classification
The table below presents a use case model where classifications are selected/deselected at the term level based on the Term’s scope or the sensitivity of data within that term.
|
Default Classifications (Domain Level) |
Terms |
Configuring Term Classifications |
|
✅Public ✅Confidential ✅PII |
Customer Name |
✅ Public ⌧ Confidential ⌧ PII |
|
Customer Address |
⌧Public ✅ Confidential ✅ PII |
|
|
Customer Social Security Number |
⌧ Public ✅ Confidential ✅ PII |
Association Policy “Show Classification at Catalog”
Within a term summary page, the data association option to “Show classification in catalog” can be selected. When the "Show classification at catalog" policy is activated on the term level, it enhances the visibility of classifications configured for that term. Classifications will be displayed in the summary details of data objects, such as tables, table columns, files, file columns, reports, report columns, API and API attributes.
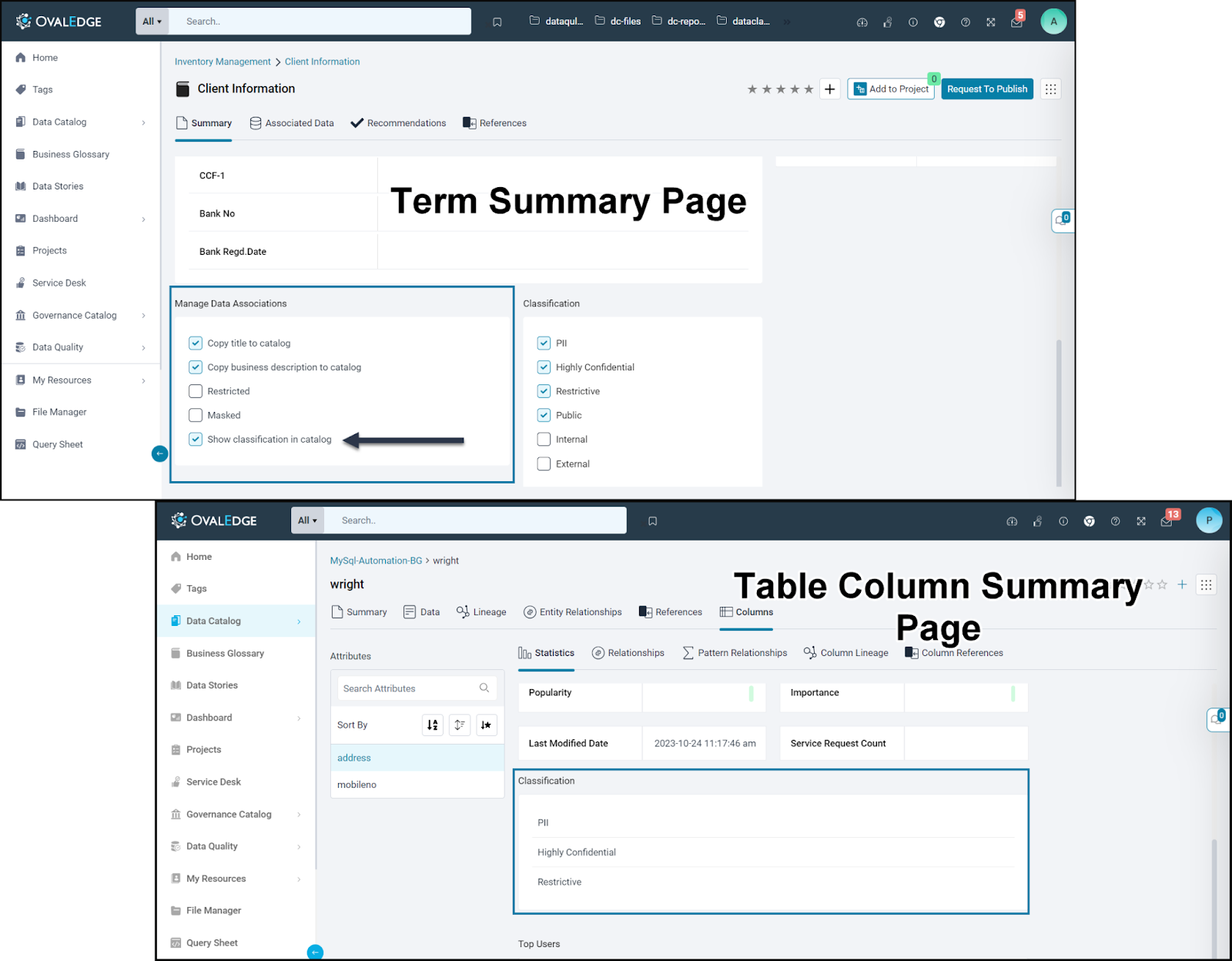
Viewing Classified Data Objects in Data Classification Page
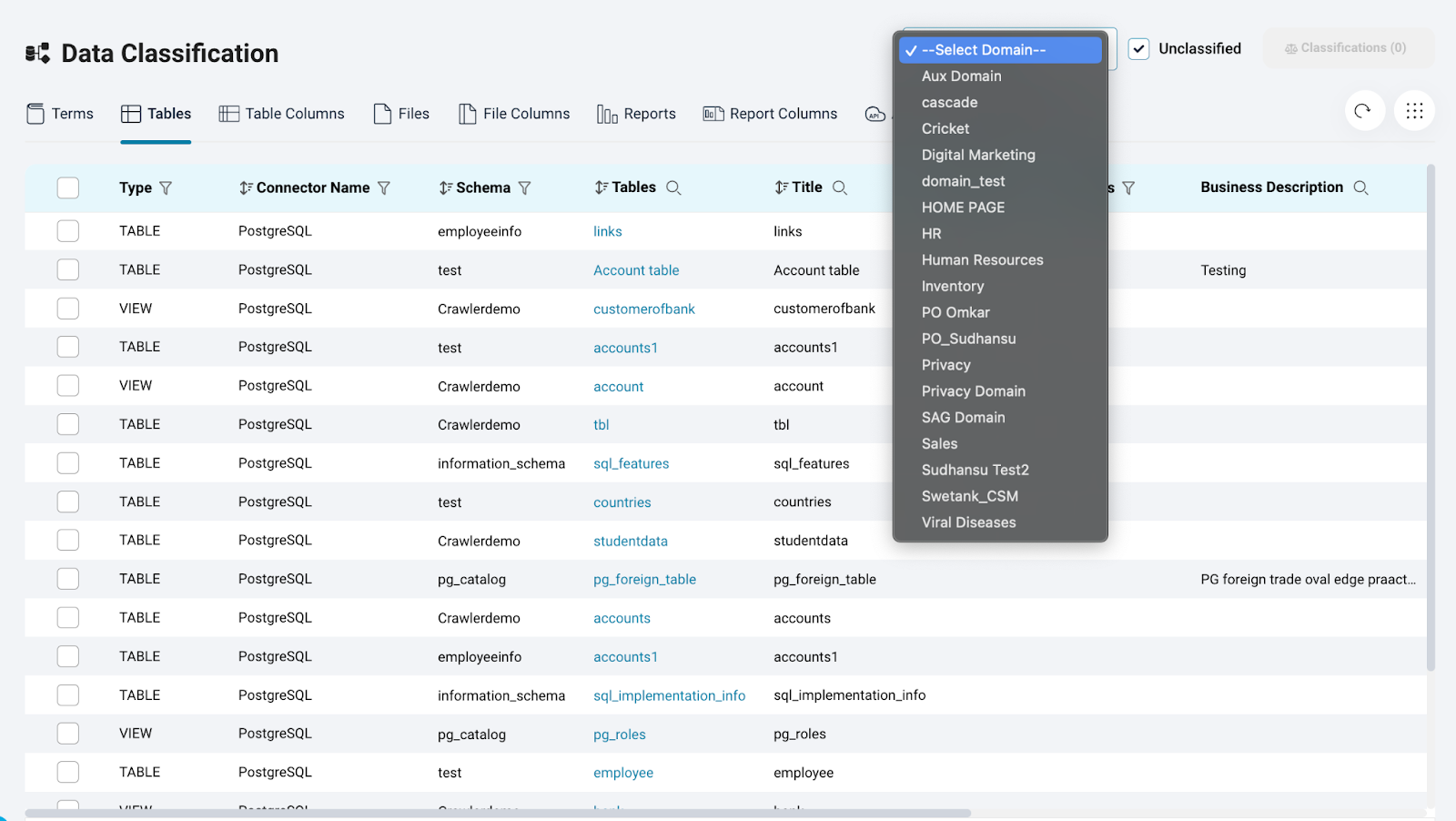
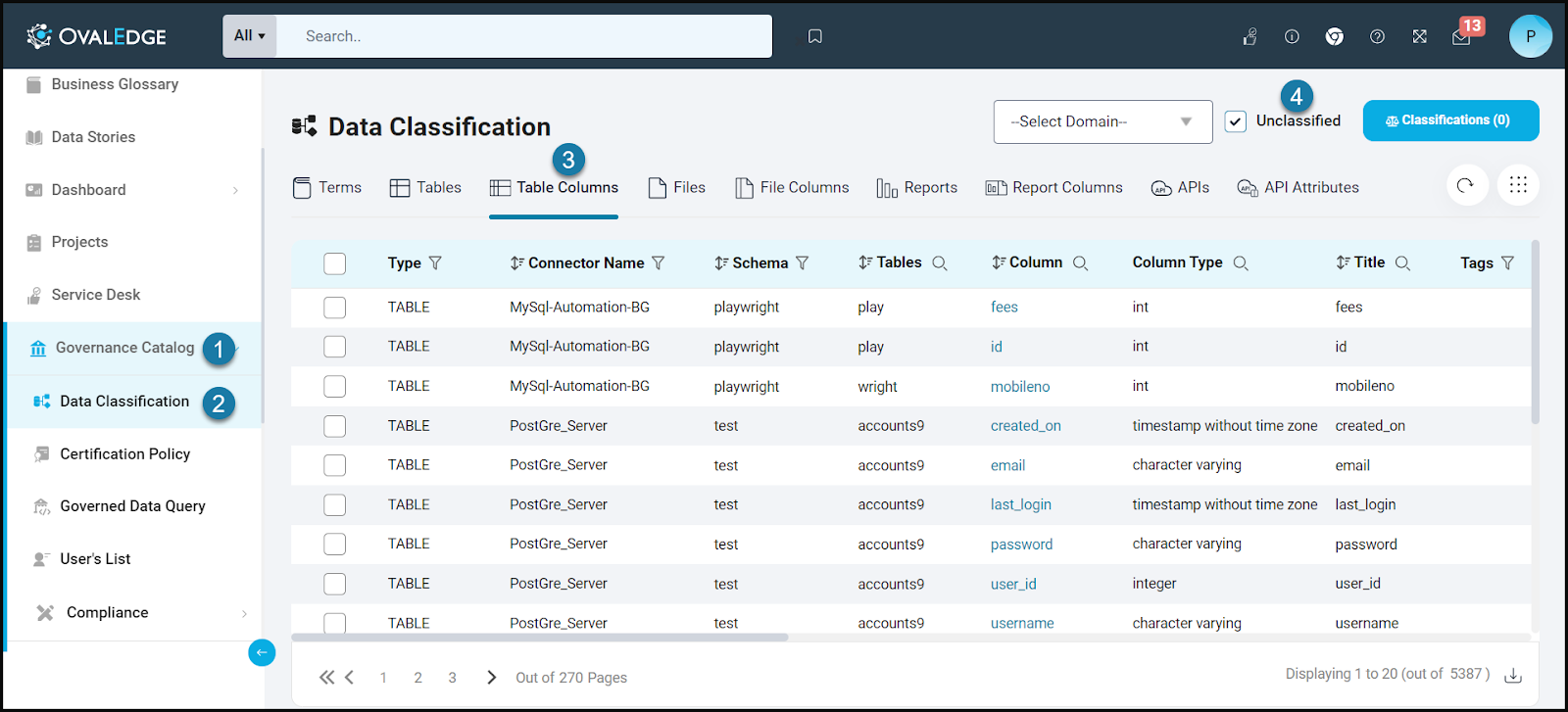
Navigating Data Classification
In OvalEdge, the Data Classification page is the centralized hub for viewing classified and unclassified data objects. Users can select a specific domain and the classifications defined within that domain. This results in a list of data objects associated with the terms from that domain and corresponding classification
|
Note: Classified data objects are those with terms linked to them, while unclassified data objects are those without any associated terms. |
Filtering by Domain
Classifications are configured at domain level, thus when a user comes to the data classification page they can view data objects which have terms associated with them from a specific domain. This functionality allows users to view data objects classified with terms under a specific domain, users have the ability to access classified data objects within particular categories and subcategories..
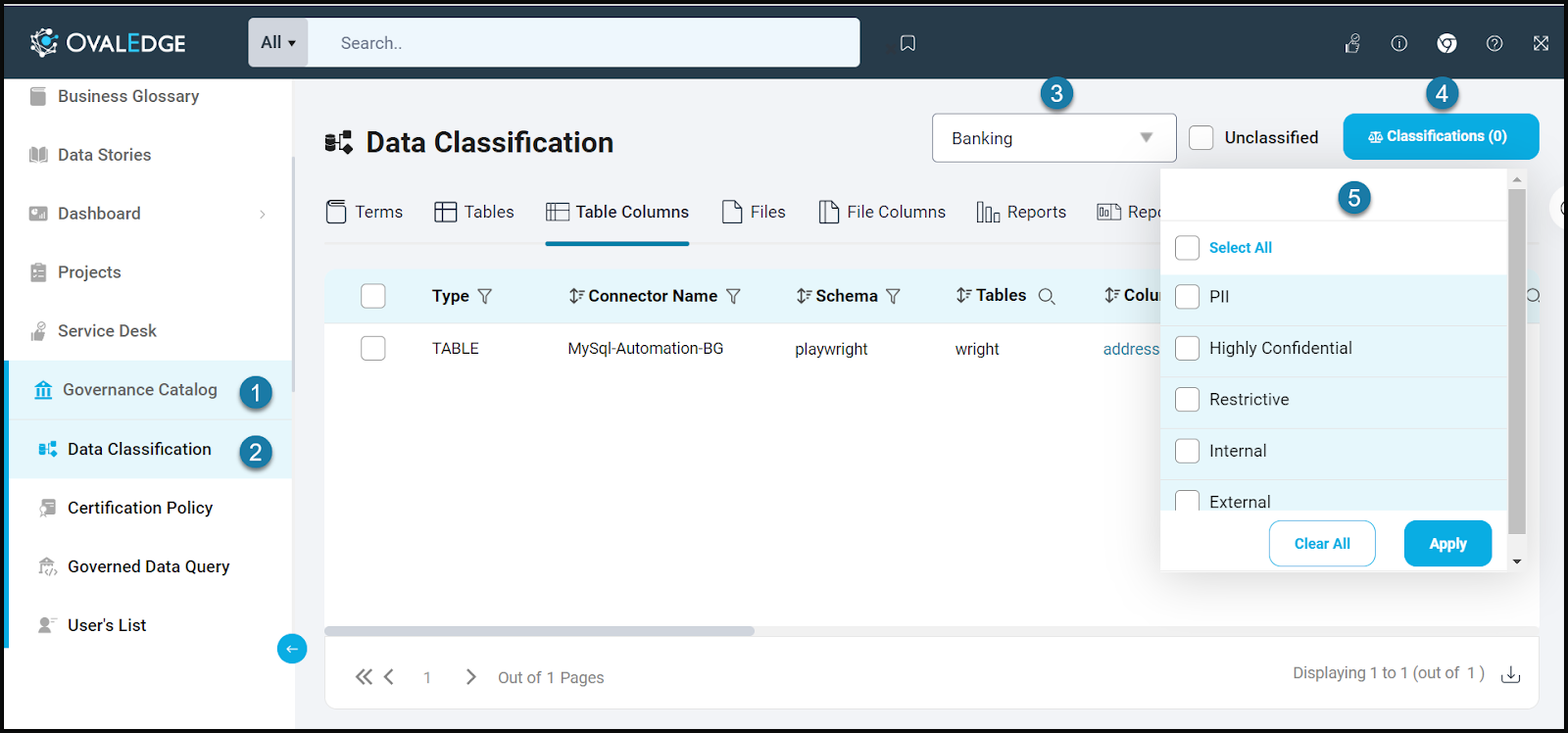
Filtering by Classification
Auditors can use the Data Classification page to filter data objects based on their classification.
- Take the "Customer" domain as an example. Inside this domain, there are terms like "Customer Name" and "Customer Aadhar Number," each linked to specific data objects (tables, files, etc.).
- These terms inherit classifications like "public," "private," or "sensitive" from the domain level.
- When users select the "Customer" domain and the "sensitive" classification, the Data Classification page displays a list of all data objects categorized as "sensitive" within the "Customer" domain. This makes it easy for auditors to find and review sensitive customer data.
Unclassified Data Objects
On the same page, there's another section that displays unclassified data objects. Unclassified data objects are those that do not have any associated terms in the system. This area is designed to identify data objects that do not have any terms associated with them.
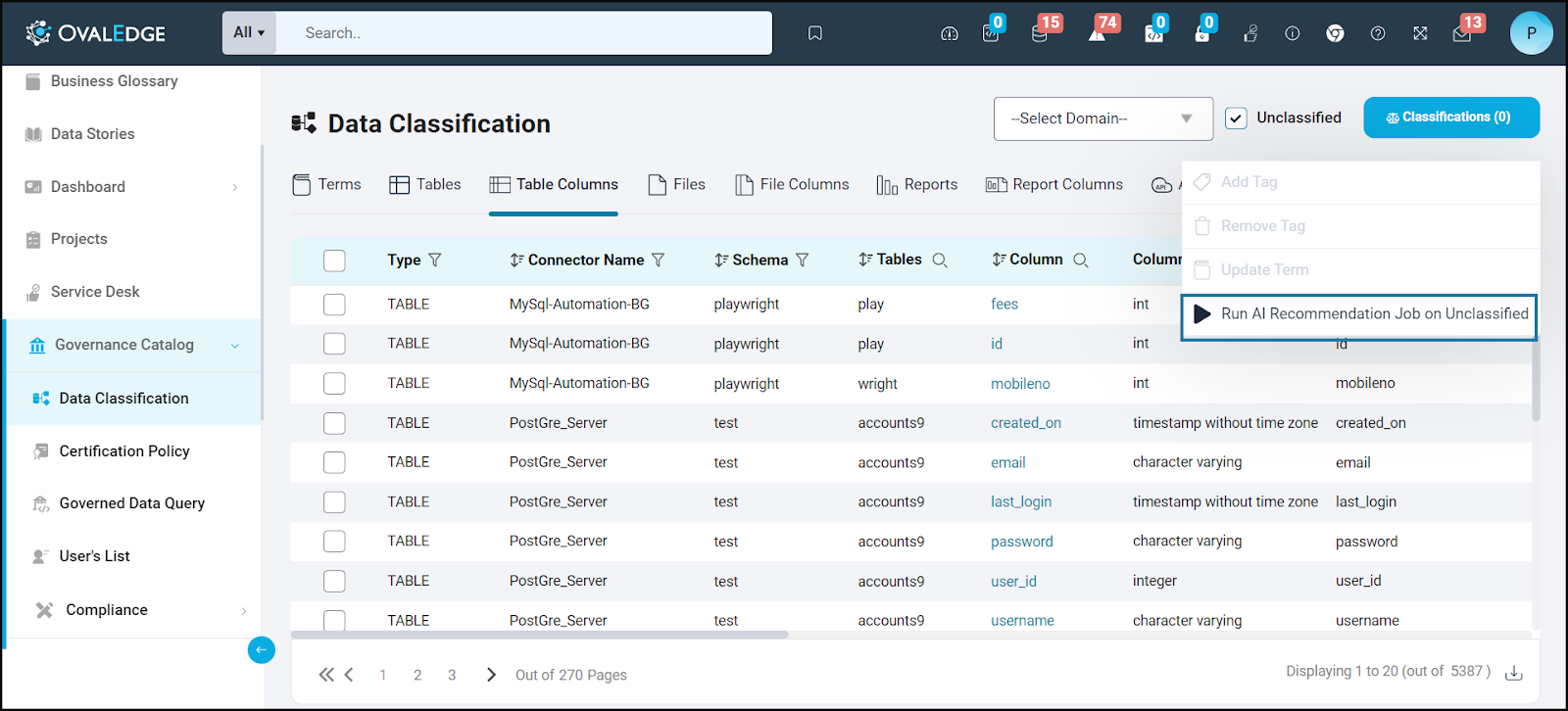
On the Data Classification page, users can manually add or perform bulk updates on terms for the selected data objects using the 9-dots menu. Additionally, users can utilize AI Recommendations to automate the process of suggesting terms for unclassified data objects.
Operations on Data Objects
Run AI Recommendation
The AI algorithms offer an efficient way to recommend terms for unclassified data objects, resulting in significant time and effort savings compared to manual term associations. AI recommendations can be run only on table columns from data classification screen. However, these AI algorithms focus on suggesting terms that are pertinent to the data objects. The final decision regarding the acceptance or rejection of recommended terms lies with the users like stewards of the term or domain, ensuring that the right terms are associated with the data objects.
The AI recommendations are initiated based on selected domains and classifications which serve as the foundation for suggesting terms on unclassified data objects.
The functioning of the AI recommendation algorithms happens in the background, primarily relying on a Smart Score, Name of the object, Data of the object and pattern. This score is calculated by scrutinizing the attributes of data objects, such as their name, metadata, and content. It also takes into account data patterns, including the frequency and co-occurrence of various terms within the data objects. After the Smart Score computation, the algorithm generates a list of the most relevant data objects for the specified term.
To know more about the AI process you can refer to the below article
AI Recommendations Business Glossary
Add / Remove Tags
Users (Meta-Write access) have the flexibility to add or remove tags to the data objects from the data classification page.
Add Tags: Users can assign new tags to the data, making it easier to find and organize later. For example, they could tag a document as "Important" or "Work-related."
Remove Tags: Users can also take away these tags from the data. So, if they mistakenly added the tag "Personal" to a work document, they can remove it.
Change Management
Changing Classifications at the Domain Level
In OvalEdge, metadata, including classifications, can be modified by authorized users like users with Meta-Write and users assigned to governance roles at both the term and domain levels. These modifications can involve changing, deleting, or updating classifications. The level of authority is determined by the user's role and permissions within the domain.
For instance, consider the "Customer" domain. Authorized stakeholders at the domain level can change or delete classifications within the entire domain. If they decide that certain data previously classified as "sensitive" should now be considered "internal use only", they can make this change at the domain level. Once updated, this modification cascades down the entire hierarchy, ensuring consistency in the classification of related terms and associated data objects.
Change Management at Term Level
At the term level, stakeholders also have the authority to modify classifications. For example, the term "Customer Social Security Number" might have been initially classified as "private". If the stakeholder responsible for this term decides that it should be classified as "confidential", they can move the term to the draft state, update the classification, and then republish it. This change will then affect any associated data objects, ensuring that the updated classification is reflected wherever this term is used.
In summary, OvalEdge allows authorized users, both at the domain and term levels, to have granular control over data classifications. They can make changes, delete, or modify classifications based on evolving business needs, ensuring that data is accurately classified and managed throughout the entire hierarchy, and promoting effective data governance and compliance.