Governance of data quality is a process of regularly monitoring, controlling, verifying, and correcting the quality of data that comes into the systems being governed. Typically, systems in an enterprise landscape will have accumulated large volumes of data, and getting insights into this quality involves significant effort and technical skills that are always at a premium.
The Data Owners and Data Stewards responsible for different systems need an easy, fast and repeatable mechanism to govern data quality within their control span through data quality rules. With new data standards being introduced by regulatory bodies and governments, the frequency of data governance operations has increased significantly.
To enable these users, OvalEdge provides a framework for authoring and running Data Quality Rules (Rules) by the functional data owners that can be applied to data systems across the enterprise.
Data Quality Rule is a set of the processes written on a data object to monitor regularly, control, and verify data quality whenever data transformation happens. In OvalEdge, each data quality rule is governed across a domain or a business glossary associated with a data object.
Note: Each Data quality rule can have only one domain or a Business term. i.e., Multiple Business terms cannot be added to the same rule.
Rules are applicable to the following data sources:
- DBMS Tables & Columns like RDBMS, ODBMS< NoSQL, etc.
- Structured data files like .csv, .xls, .xml, .json, pqt etc.
DQR Lifecycle
A data quality rule's lifecycle begins with the design and development process, followed by the rule's publication. The rules are scheduled here, the results are generated, alerts are notified, and finally, it completes the cycle by creating a service desk ticket to improve the quality of the rules.
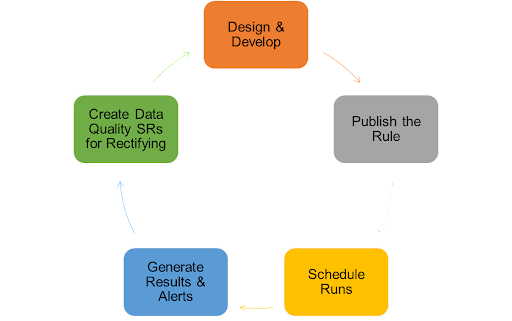
The Main Components of Rules
|
Components |
Description |
|---|---|
|
Function |
It is the rule function that is executed on the data of the target data object. |
|
Target Data Object |
The Table, Table Column, Files, File column, Business Term on which the rule is applied, |
|
The Rule type |
It is inferred from the function chosen for the rule. |
|
Custom Rules |
Custom rules require user inputs for data validation based on interpretation values
|
The Types of DQRs
A Data Quality Rule defines a specific condition to be verified on the target data element and returns the verification result.
The types of the DQRs defined in OvalEdge are
Standard Rule
The standard rule is developed using the functions available on the platform. The repository of functions includes functions that operate on different object types. Each function has an execution mechanism & it can be associated with a certain kind of object.
OvalEdge application comes with the following default Functions:
- Table Functions: DENSITY, NULL DENSITY, TOTAL ROW COUNT
- Table Column Functions: AVERAGE, DISTINCT, MIN, MAX, NULL COUNT, STD DEVIATION, SUM, TOP VALUES
- SQL Functions: SQL EXACT VALUE, SQL VALUE CONTAINS, SQL VALUE RANGE
- File Functions (FL) : FILE CREATED DATE(FL), FILE SIZE VALIDATION(FL), FILE FORMAT VALIDATION(FL), FILENAME CONTAINS(FL), FILE ROW VALIDATION(FL)
- File Column Functions(FC) :
- HAS_NOT_NULL
- HAS_NO_DIGITS_OR_SPECIAL_CHARS, HAS_FIRST_AND_LAST_CHAR, HAS_SUBSTRING_IN_STRING, HAS_LANGUAGE, HAS_WORD_RANGE, HAS_EXACT_VALUE, HAS_REGEX_MATCH, HAS_COLUMN_VALUE_MATCH, HAS_COLUMN_MATCH_FIXED_VALUE, HAS_FIRST_UPPER_REST_LOWER, HAS_UNIQUE_VALUE, WORD_VALIDATION, NUMBER_VALIDATION, DATE_VALIDATION
Important Note: Most used functions are considered based on the maximum number of times that a Function is used in creating Rules. Based on the selected function, the system will allow you to choose the Object (Table/Table Column/File / File Column/ SQL)
The application comes up with default functions with suffixes as shown below:
|
Suffix |
Object Type |
Example |
|
FC |
File Column |
HAS_NOT_NULL(FC) |
|
FL |
File |
FILE CREATED DATE(FL) |
|
SQL |
SQL Query |
SQL VALUE RANGE(SQL) |
|
TB |
Table |
TOTAL ROW COUNT(TB) |
|
TC |
Table Column |
NULL COUNT(TC) |
Custom Rule
The custom rule is developed for which the end-user provides the scripts for validating the data in the target data element. It helps in the data validation using customized rules by providing interpretation values such as (Boolean, Value, and Range).
- Boolean. It is a default value.
- Value. The rule query result should match the value specified for the success
- Range. The rule query result should be within the range specified.
Both these types of rules can be defined on target data elements the platform has crawled. In addition, for file-based data sources, file DQR can also be applied on batch or offline files that are available on file systems visible to the platform. It allows you to apply rules as a pre-validation on transient files before they get processed into data systems to ensure that only good quality data is persisted. In addition, an additional customized option to run rules on file type data sources is also available in the Advanced Jobs micro-application module of the platform.
Data Granularity Levels
Rules can be run at different data granularity levels:
- A rule can be run at individual object levels, for example, Table, Table Column, File, File column
Examples: For the object type table, if we specify the rule TOTAL ROW COUNT(TB), on the successful execution of this rule it will give the total row count of that table associated with this rule function. - A business glossary Term that groups a set of objects. For example, this allows the application of rules based on business context across a set of similar base data objects, significantly extending the scope of a rule. It also allows the rule to be dynamic, increasing the scope of application as the term size grows.
Note: A standard rule scope is limited to one function and one scope item (among the above ones).
Data Quality Insights & Enablers
The Data Catalog module provides some predefined data quality indicators and enablers, which are explained before detailing the DQR functionality in subsequent sections.
Profiling to get data quality insights
As part of the data catalog, data objects can be profiled to gain quality insights at the column level. Profiling a schema is easy to identify fundamental data quality issues at first sight. The profiling measures include null count, distinct count, row count, etc.
SQL Queries can also be executed to collect one-off custom data quality measures of a data object.
Example: Use the OvalEdge Query Sheet module to write a simple query.
SELECT AVERAGE(column_name)
FROM table_name
WHERE column_name IS NULL; it will give the count of rows with null values in the column.
Reporting Data Quality Issue
In OvalEdge, the data quality issues identified on a data object such as Table/ Column/ File/ Report/ Business glossary can be reported as service requests in the ServiceDesk module.
System owners resolve the data quality service requests outside the OvalEdge platform. Data Owners and Data Stewards will have to follow up offline on the status and close the service request once the issue is resolved on the actual system.
Resolving Data Quality Issue
Coordinate with the responsible users to correct the issues in the source system. Each data quality issue can be notified to responsible users in the DBA team. These issues are later resolved in the organization's ETL pipeline of the source system.
A request of any DATA QUALITY(DQ) ISSUE on a data object is notified to that data object STEWARD at the schema level. Later the STEWARD sends an e-mail notification to the responsible user to resolve the issue at the source system. Once the issue is resolved in the source system, STEWARD approves the data quality service request raised. Additionally, users who have ADMIN rights can also approve the DQ issues.
Roles and Permissions to Access the Data Quality Rule
A user who has access to a specific DOMAIN with Read-Write permission can create a data quality rule ONLY in that DOMAIN. Whereas a user with an OE_ADMIN role can create DQR in any DOMAIN.
|
Domain Access |
Meta Permission Type |
Permission Abbreviation |
Access Privileges |
|
Yes |
READ ONLY |
RO |
Cannot create a Data Quality Rule |
|
Yes |
READ WRITE |
RW |
Can create a Data Quality Rule |
|
No |
READ ONLY/ READ WRITE |
RO/RW |
Cannot create a Data Quality Rule |
Rule Types attribute
Once a Domain is selected, you can select the variable type needed. Data Quality rules are set at the following three variable levels,
- Object Level
- Field Level
- Custom SQL
Object Level Variables
Object-level variables work at the Database tables or columns. Following is the list of rule checks on the object levels:
- DENSITY PERCENT(TB): You can create a rule for the data quality on the table (Including all columns) and on the column in percentage format from 0 to 100.
Success Range: It determines the success or failure of a rule validation depending on the average calculated between Lower Range and Upper Range for that rule or function. Some Functions take values in Range, and some take in percentages.
How to compute the density percentage of the object
To calculate the Density percentage of the object, you need to select the function DENSITY PERCENTAGE (TB) and then provide the Success Range (AV IS IN B/W UR / LR) when the AV >= GV then rule validation is PASS. This function returns TRUE if the computed density percentage falls in the range else FALSE
Generic Query: select COUNT(DISTINCT($COLUMN)) as densitycnt from $TABLE where $COLUMN is NOT NULL.
For example, the DENSITY PERCENTAGE function can succeed if the table object's density percentage is between 2% to 10%.
Note: If the validation rule fails, it will raise an alert and ticket only when alerts and tickets are enabled for that rule. - NULL DENSITY PERCENT(TB): You can create a rule for the data quality on the table (Including all columns) and on the column in percentage format from 0 to 100. Returns TRUE if the computed null density percentage falls in the range else FALSE
Success Range: It determines the success or failure of a rule validation depending on the average value calculated between Lower Range and Upper Range for that rule or function. Some Functions take values in Range, and some take in percentages.
How to compute the Null density percentage of the object?
To calculate the Null Density percentage of the object, you need to select the function NULL DENSITY PERCENTAGE (TB) and then provide the Success Range (AV IS IN B/W UR / LR ) when the AV <= GV, then rule validation is PASS. This function returns TRUE if the computed null density percentage falls in the range else FALSE
Generic Query: select count(*) as nulldensity from $TABLE WHERE $COLUMN is NULL.
For Example, The Null dentistry percentage function can be successful if the null count(address) is between 2% to 5% of the total rows. - TOTAL ROW COUNT(TB): You can create a rule for the data quality on the table (Including all columns in the table) and on the column within the range of zero to N (0-Nth). Returns TRUE if the total row count in the table falls in the range else FALSE
Success Range: When an average value is greater than or equal to the given value, the rule validation is successful (Pass).
Generic Query: select count(*) from $TABLE.
For Example, The MAX function can be successful if the Max value of the column(order) is between 20000 to 25000.
Field Level Variables
Field-level variables work at the Database Schema level, tables, or columns. Following is the list of rule checks on the field levels:
Field Level: It relates to Table Column Level
Field-level variables work at the Database Schema level, tables, or columns. Following is the list of rule checks on the field levels:
- NULL COUNT RANGE (TB): This rule is used to check the acceptable Null count in the total available data. It may be in a number of counts of the total for that object.
How to compute the density percentage of the object
To calculate the Null Count Range of the object, you need to select the function DENSITY PERCENTAGE (TB) and then provide the Success Range (AV IS IN B/W UR / LR) when the AV >= GV then rule validation is PASS. For example, the null if the computed density percentage falls in the range else FALSE
Generic Query: select count(*) as count from $TABLE WHERE $COLUMN is NULL.
For Example, The NULL COUNT function can be successful if the null count of a column(customer) is between 1 to 10 of the total rows. - DISTINCT COUNT RANGE (TB): This rule checks the acceptable, distinct range in the total available data. It may be in numbers of the total for that object.
Generic Query: select COUNT(DISTINCT($COLUMN)) as distinct from $TABLE where $COLUMN is NOT NULL.
For example, the DISTINCT COUNT function can succeed if the null count of a column(customer) is between 1 to 10 of the total rows. - SUM RANGE: This rule checks the acceptable range of numbers (X to Y) of SUM Count total entry in the column or field.
Generic Query: select SUM($COLUMN) as the sum from $TABLE WHERE $COLUMN is not null
For Example, The SUM Range function can be successful if the null count of a column(customer) is between 1 to 10 of the total rows. - AVERAGE RANGE: This rule is used to check the acceptable range of numbers (X to Y) of the Avg. Count of total entries in the column or field.
Generic Query: select avg($COLUMN) as avg from $TABLE WHERE $COLUMN is NOT NULL.
For Example, The Average Range function can be successful if the average count of a column(customer) is between 100 to 3000 of the total rows. - MIN RANGE: This rule checks the acceptable range of numbers (X to Y) of the Min Count of total entry in the column or field.
Generic Query: select Min($COLUMN) as min from $TABLE WHERE $COLUMN is NOT NULL.
For Example, The Minimum Range function can be successful if the min value of a column data( customerid) is between 1 to 10 for numeric values of the total rows.
For Example, The Minimum Range function can be successful if the min value of a column data a column(customername) is between (Anny to Mary) for the string value of the total rows. - MAX RANGE: This rule checks the acceptable range of numbers (X to Y) of the Max Count of total entry in the column or field.
Generic Query: select MAX($COLUMN) as max from $TABLE WHERE $COLUMN is NOT NULL.
For Example, The Maximum Range function can be successful if the maximum value of column data (customerid) is between 1 and 10 for numeric values of the total rows.
For Example, The Maximum Range function can be successful if the maximum value of a column data a column(customername) is between (Anny and Mary) for the string value of the total rows. - STD DEVIATION RANGE: This rule checks the acceptable Std Deviation range for the total entry in the column or field.
Generic Query: select STDEV($COLUMN) as stddev from $TABLE WHERE $COLUMN is not null.
For Example, The Std Deviation Range function can succeed if the standard deviation falls in the given range (X to Y).
Field Level: It relates to Table Colum level
- AVERAGE(TC): Returns TRUE if the average computed falls in the range; else FALSE
- DISTINCT(TC): Returns TRUE if the count of distinct values falls in the range; else FALSE
- MIN(TC): Returns TRUE if the min value falls in the range; else FALSE
- MAX(TC): Returns TRUE if the max value falls in the range; else FALSE
- NULL COUNT(TC): Returns TRUE if the count of null values falls in the range; else FALSE and gets the stats and first50failedvalues
- STD DEVIATION(TC): Returns TRUE if the computed standard deviation falls in the range; else FALSE
- SUM(TC): Returns TRUE if the sum of all cells computed falls in the range; else FALSE
- TOPVALUES(TC): Returns TRUE if the top values of the column match with at least one value in param 1; else FALSE
Generic Query: To calculate TOP VALUES, SELECT $COLUMN, COUNT(*) AS cnt FROM $TABLE WHERE $COLUMN IS NOT NULL GROUP BY $COLUMN ORDER BY 2 DESC
Example: In a table having a list of students, on the column is having marks. The teacher wants to get top 50 marks. This rule can be used here to get the top 50 marks.
Note: To get the top values within a particular, you must run the DQ Rule. - VALIDATE EMAIL(TC): Returns TRUE if the format of the elements in the column is “%_@_%._%,” else FALSE, and Executes the stats and values code
Generic Query: To calculate the VALIDATE EMAIL(TC), select SUM((CASE WHEN (trim($COLUMN) like '%@%._%' AND trim($COLUMN) not like '% %' AND trim($COLUMN) not like '%@%@%' AND trim($COLUMN) not like '%..%' AND trim($COLUMN) not like '.%' AND trim($COLUMN) not like '%.' AND trim($COLUMN) not like '%.@%' AND trim($COLUMN) not like '%@.%' AND trim($COLUMN) not like '%&%' AND trim($COLUMN) not like '%$%') then 1 else 0 END)) * 100 / count(*) as result from $TABLE
Example: A table having customer name and email address. You want to validate the email address and the percentage of the correct email address you wants to get. If you want to get the % within a range. - DENSITY PERCENT(TC): If the density computed falls in the given range, it returns a TRUE value; otherwise, a FALSE value.
Generic Query: To calculate the DENSITY PERCENT(TC) select count(distinct($COLUMN)) * 100 / (CASE WHEN count() = 0 THEN 1 ELSE count() END) as densitycnt from $TABLE WHERE $COLUMN IS NOT NULL.
Example: To get the number of occupied cells present in a column by the distinct values, you can run this query. The data density figure represents the percentage of records with values for an attribute. If only half the total number of records in the Address data object have a non-null value populated for the State attribute, then the data density value for State is 50%. - NULL DENSITY PERCENT(TC): Returns TRUE if the computed null density falls in the percentage range; else FALSE
Generic Query: To calculate the NULL DENSITY PERCENT(TC), select sum(case when $COLUMN is null then 1 else 0 ends)100/count() as nulldensity from $TABLE.
Example: To get the number of empty cells present in a column, you can run this query. - VALIDATE REGEX(TC): Returns TRUE if the defined REGEX matches with the column values; else FALSE and Executes the stats and values code
Generic Query: To run this query select SUM((CASE WHEN trim($COLUMN) regexp $REGEX then 1 else 0 END)) * 100 / (case when count() = 0 then 1 else count() end) as result from $TABLE
Example: To validate the customer Name in the customer order table, you can run this query. If you have added the regex ^[a-z]*$, then it will find the names with lower case and compute within the given range. - VALIDATE PATTERN(TC): Returns TRUE if the defined pattern (ULD or combination of any) matches with the column pattern; else FALSE and Executes the stats and values code
Generic Query: To run this query, select SUM((CASE WHEN trim($COLUMN) regexp $REGEX then 1 else 0 END)) * 100 / (case when count() = 0 then 1 else count() end) as result from $TABLE. To run this query, you must give a pattern (ULD) in the required field.
Example: To validate the customer order IDs of the customer order table, you can run this query. If you have added the pattern DDD, it will compute the 3-digit order Ids available in the column within the rage. - OUTLIER RULE(TC): User-provided values for low & high range values should be between the table's min and max column. If low or high values are not in that column's minimum and max range, rule execution status will fail and show the statistics.
Generic Query: To run this query, select (CASE WHEN count(*) = 0 then one else 0 END) as a result from $TABLE where convert (REPLACE ($COLUMN, ","), DECIMAL) < $MINVALUE or convert (REPLACE ($COLUMN,"",""), DECIMAL) > $MAXVALUE
Example: In an Employee table having min value as 1 and max value as 250, to compute the Ids between 50 to 100, this query can be used
Note: An outlier is an observation that appears to deviate markedly from other observations in the sample. Identification of potential outliers is important for the following reasons. An outlier may indicate bad data. For example, the data may have been coded incorrectly, or an experiment may not have been run correctly. - IS_UNIQUE_COLUMN(TC):
Generic Query: select case when (count($COLUMN) - count(DISTINCT $COLUMN)) > 0 then 0 else 1 end as uniquecolumncount from $TABLE where $COLUMN is not null
Example: To compute the unique count available in the column, you can run this query. You can run this query in a student table with marks to compute the unique count of marks available in the column.
Field Level: It relates to File
- HAS_NOT_NUL (Has no null value): Returns TRUE if there is no null value; else, it returns FALSE.
- HAS_NO_DIGITS_OR_SPECIAL_CHARS (Has No digits or special chars): returns true if there are no special characters or any digits; else returns false.
- HAS_FIRST_AND_LAST_CHAR (No leading or trailing spaces): Returns TRUE if there are no leading or trailing spaces; else, it returns FALSE.
- HAS_SUBSTRING_IN_STRING (Has substring in the string): Returns TRUE if the substring value is present in the given string; else, it returns FALSE.
- HAS_LANGUAGE (Belongs to one of the languages): Returns TRUE if the language of the column matches the provided language passed in parameter1; else returns FALSE.
- HAS_WORD_RANGE (Word count within range): the Returns TRUE if the number of words in the column data is in the range given by you; otherwise returns FALSE.
- HAS_EXACT_VALUE (Column Value same as another Column Value): Returns TRUE if the column value given in parameter1 matches the value given in the column value on which we are running the rule; else, it returns false.
- HAS_REGEX_MATCH (Regex match): Returns TRUE if the data in the column matches with the regex given in parameter1; else, it returns FALSE.
- HAS_COLUMN_VALUE_MATCH (Column Value matches one of given values): Returns TRUE if the value of the given column matches with any of the values of the parameter1 else, it returns FALSE.
- HAS_COLUMN_MATCH_FIXED_VALUE (All Column Values matches given fixed value): Returns TRUE if the value in the column matches with the fixed value given in the parameter1 else returns FALSE.
- HAS_FIRST_UPPER_REST_LOWER (First Letter of Word Upper case and Rest Lower Case): Returns TRUE if the word's first letter is in uppercase and the rest of the word is in lowercase; else, FALSE.
- HAS_UNIQUE_VALUE(This Column Value Should Be Unique): Returns TRUE if the value in the column is unique, i.e. (No duplicate value); it returns FALSE.
- WORD_VALIDATION (Word Validation): Returns TRUE if the total number of spaces in the column data is less than or equal to the value given in the param1; else, it returns false. If we want to limit the number of spaces between words, we must pass the limit in param2. If the no spaces count between words exceeds the limit, it returns FALSE; otherwise, it returns TRUE.
- NUMBER_VALIDATION (Number Validation): Returns TRUE if the data type in the column(int/float) value matches the parameter1 value we are passing; otherwise, FALSE.
- If the column data type is float and we want to limit the decimal places, we pass the limits in parameter2. If decimals exceed the param2 limit, it returns false or true.
- If the column data type is int and we want to limit the number of digits, we pass decimal limits in parameter3. If no. of digits exceeds the limit in param3 returns false, else true.
- If we do not want any “commas” in the column data, we should pass: “N”; else, we should pass “T” in param4. If we pass “Y” and have commas in the column, data returns true or false. If we pass “N” in param4 and have no commas in the column data, it returns true or false."
- DATE_VALIDATION (Date Validation): Returns TRUE if the date format in values matches the date format given in parameter1; else returns false. If we want to limit the years between the range, we must pass the minimum year in param2 and the full year in param3. If the year in column data is between the minimum and maximum year specified by you, it returns true or false. (Exclusive values).
- HAS_DIGITS_AND_SPECIAL_CHARS (Has digits and special chars): Returns TRUE if the column's value is alphanumeric and should contain digits and special characters; else, it returns FALSE. There is no need for passing parameters.
- HAS_CONSTANT_VALUE (Value Validation): If the column has the same value in all the rows, i.e. (constant value), it returns false. There is no need for passing parameters
- HAS_ONLY_ONE_SPECIAL_CHAR(Allow only one special Character): Returns TRUE if the column values have only one type of special character which passes in parameter1; else returns false. We must pass the special character in param1, which we want to be in column data
- HAS_LENGTH_RANGE(Has length of the value within a range): Returns TRUE if the character in the value is within the range; else returns false. We must pass the minimum value range in param1 and the maximum value range in param2.
- HAS_NUMERIC_VALUE_RANGE (Numeric Value between min and max): Returns TRUE if the number value is within the range; else returns false. We must pass the minimum value range in param1 and the maximum value range in param2.
File Level: It relates to File
- FILE NAME CONTAINS(FL) : You may provide a File name in the input of a query while adding bulk objects in the Association Tab.
For Example File name (Demo) is provided in the input field. Then if the file name computes with the associated object then it gets PASSED or else FAILS. - FILE FORMAT VALIDATION(FL): The file can be in the given format. For example : .json, .csv, .parquet, .xlsx. But for now it can accept the validation for .csv and .json.
- FILE CREATED DATE(FL): The file created date must be in the given Range. Returns TRUE if the created date computes in the range; else FALSE.
- FILE ROW VALIDATION(FL): The row count of a file. Returns TRUE if the rows are computed in the range; else FALSE.
- FILE SIZE VALIDATION(FL): You should provide the file size in bytes for the given ranges. Returns TRUE if the file size computes in the range; else FALSE.
For Example, if the file size has 20kb, then you should first convert the kb to bytes (1024), now the value for 20 kb = 19.5313 bytes. The ranges below 19 - 19.5313, then the rule get passed.
File Field Level: It relates to File Column
- HAS_NOT_NULL (Has no null value): returns true if there is no null value; else, it returns false.
- HAS_NO_DIGITS_OR_SPECIAL_CHARS (Has No digits or special chars): returns true if there are no special characters or any digits; else returns false.
- HAS_FIRST_AND_LAST_CHAR (No leading or trailing spaces): returns true if there are no leading or trailing spaces; else, it returns false.
- HAS_SUBSTRING_IN_STRING (Has substring in the string): returns true if the substring value is present in the given string; else, it returns false.
- HAS_LANGUAGE (Belongs to one of the languages): returns true if the language of the column matches the provided language passed in parameter1; else returns false.
- HAS_WORD_RANGE (Word count within range): the rule returns true if the number of words present in the column data is in the range given by you; otherwise returns false.
- HAS_EXACT_VALUE (Column Value same as another Column Value): returns true if the column value given in parameter1 matches the value given in the column value on which we are running the rule; else, it returns false.
- HAS_REGEX_MATCH (Regex match): returns true if the data in the column matches with the regex given in parameter1; else, it returns false.
- HAS_COLUMN_VALUE_MATCH (Column Value matches one of given values): returns true if the value of the given column matches with any one of the values of the parameter1 else, it returns false.
- HAS_COLUMN_MATCH_FIXED_VALUE (All Column Values matches given fixed value): returns true if the value in the column matches with the fixed value given in the parameter1 else returns false.
- HAS_FIRST_UPPER_REST_LOWER (First Letter of Word Upper case and Rest Lower Case): returns true if the word's first letter is in uppercase and the rest of the word is in lowercase; else, it returns false.
- HAS_UNIQUE_VALUE(This Column Value Should Be Unique): returns true if the value in the column is unique, i.e. (No duplicate value); it returns false.
- WORD_VALIDATION (Word Validation): returns true if the total number of spaces in the column data is less than or equal to the value given in the param1; else, it returns false. If we want to limit the number of spaces between words, we must pass the limit in param2. If the no spaces count between words exceeds the limit, it returns false else, it returns true.
- NUMBER_VALIDATION (Number Validation): returns true if the data type in the column(int/float) value matches the parameter1 value we are passing; otherwise, it returns false.
- If the column data type is float and we want to limit the decimal places, we pass the limits in parameter2. If decimals exceed the param2 limit, it returns false or true.
- If the column data type is int and we want to limit the number of digits, we pass decimal limits in parameter3. If no. of digits exceeds the limit in param3 returns false, else true.
- If we do not want any “commas” in the column data, we should pass: “N”; else, we should pass “T” in param4. If we pass “Y” and have commas in the column, data returns true, or else returns false. If we pass “N” in param4 and have no commas in the column data, it returns true, else returns false."
- DATE_VALIDATION (Date Validation): returns true if the date format in values matches the date format given in parameter1; else returns false. If we want to limit the years between the range, we must pass the minimum year in param2 and the maximum year in param3. If the year in column data is between the minimum and maximum year specified by you, it returns true, or else it returns false. (Exclusive values).
- HAS_DIGITS_AND_SPECIAL_CHARS (Has digits and special chars): returns true if the column's value is alphanumeric and should contain digits and special characters; else, it returns false. There is no need for passing parameters.
- HAS_CONSTANT_VALUE (Value Validation): returns true if the column has the same value in all the rows, i.e. (constant value), then it returns false. There is no need for passing parameters
- HAS_ONLY_ONE_SPECIAL_CHAR(Allow only one special Character): returns true if the column values have only one type of special character which passes in parameter1; else returns false. We must pass the special character in param1, which we want to be in column data.
- HAS_LENGTH_RANGE(Has length of the value within a range): returns true if the character in the value is within the range; else returns false. We must pass the minimum value range in param1 and the maximum value range in param2.
- HAS_NUMERIC_VALUE_RANGE (Numeric Value between min and max) returns true if the number value is within the range; else returns false. We must pass the minimum value range in param1 and the maximum value range in param2.
Custom SQL
Custom SQL works for cataloged SQL from the query sheet. Following is the list of rule checks as below:
- Custom Values: This rule is used to check for the values associated with the cataloged SQL. The values can be separated using commas. If the rule's output is among the values added, it is considered PASS; else, FAIL.
- Custom Range: This rule checks for the acceptable range values associated with the cataloged SQL. You have to enter the lower and upper ranges. If the rule's output is in the custom range defined, it is considered as PASS or FAIL.
- Custom: This rule is used to check for the cataloged SQL. If the output of the query associated with this rule is 1, then it is considered PASS; else, FAIL. The notifications are sent to the user responsible for these data objects based on the user selection for alerts and tickets. When Custom SQL is selected as rule type, three columns are present to add queries after entering the required fields. They are
|
Queries |
Description |
|
Boolean Query. |
This is an important field. It should have a query that validates the data quality and returns an actual value. It could be 0 or 1, a range of values, or an expected value. Upon clicking + in the specific column, you can see a list of cataloged queries and choose the one that is good for this column Example: SELECT min (CASE WHEN (Risk Rating is not null) THEN 1 ELSE 0 END) From dbo.tblrelational_Loan_Event_History For the Loan database, if the Risk rating is not null, it will return 1 or 0. |
|
Stats Query |
This query should be formulated to calculate the Total Count, the Total number of passed values, the Total number of failed values, and the type of data quality that is run. It could be Completeness, Validity, Accuracy, and timeliness. Upon clicking + in the specific column, you can see a list of cataloged queries and choose the one that is good for this column. This format is a must for stats queries. Using labels Totalcount, Passedcount, Failedcount, and DQPrinciple are mandatory. Example: SELECT 'Validity' DQPrinciple, count(*) Totalcount, sum(CASE WHEN ( Risk_Rating is not null ) THEN 1 ELSE 0 END) Passedcount, sum(CASE WHEN ( Risk_Rating is not null ) THEN 0 ELSE 1 END) Failedcount from dbo.tblrelational_Loan_Event_History For the Loan database, if the Risk rating is not Null, it will return the stats for the objects passedcount. |
|
First 50 Failed values Query |
This should be formulated to display the first 50 values of the data asset. Upon clicking + in the specific column, you can see a list of cataloged queries and choose the one that is good for this column. Example: SELECT top 50 Risk_Rating from dbo.tblrelational_Loan_Event_History where ( Risk_Rating is null). It will display the first 50 failed values of risk rating of the Loan database |
Note: Suppose the output of the data quality validation, the first Boolean query whose output is expected to be 0 or 1 or among the range of expected values, is false. Only the stats and first 50 count queries get executed in that case.
Cataloging Queries
This is an essential activity for running custom DQR.
- You should prepare a query that returns the output as a 0 or 1, or a specific value (expected value) or range of values (upper and lower range).
- These rules should be verified against the specific data object around which the rule has to run.
- Query sheet can be used to execute the query.
- Once the query is executed, and the output is as expected, select Job 🡪 Historic Queries. It opens a new window with a list of all queries. Against the queries, there is an option to catalog the queries. It is recommended to edit the query name to identify the queries by name is recommended. These queries can be checked under Data Catalog 🡪 Queries.
Copyright © 2019, OvalEdge LLC, Peachtree Corners GA USA