Everyone's individual data quality problem is highly important to that individual. However, to avoid getting lost in the sea of issues, you need to prioritize. Data quality issues should be prioritized based on parameters like business impact, prevalence, and the complexity of data quality issues. This then enables us to work on fixing those issues efficiently.
The following is a tried and tested strategy for improving data quality: the data quality improvement lifecycle.
-
Define
-
Collect
-
Prioritize
-
Analyze
-
Improve
-
Control
Define
The first step is to define data quality standards. These standards will be the benchmark that you will aim to work towards. This step enables you to set goals and build a vision of how improving the quality of your data will ultimately grow your business.
For example, every time you capture a social security number, you should capture nine digits. Or, every time you collect an email address, ensure it is entered twice as a secondary confirmation step.
Collect
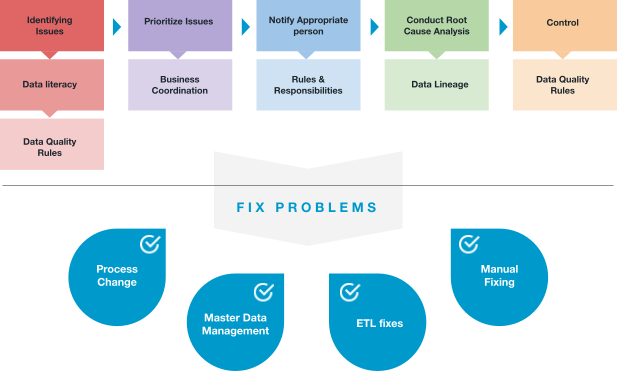
Next, you need to record all the data quality issues in an organization using a framework to locate the data quality problems. There are two ways to successfully do so. The first is to create a data literacy program within the company.
Once you create widespread literacy within an organization, you can then put in place a reporting mechanism where users can go and communicate their data quality issues. The only objective of this step is to collect the data quality issues from all sources so the data governance group will have a list of issues that must be addressed.
When capturing data quality issues, you must record the following information:
- Business value
- Where the problem exists
- What the problem is
- Priority (from a customer's perspective)
Prioritize
The next part is to develop a mechanism that helps you to understand the business impact of these data quality issues. This is the most important task data governance managers are required to do. They must consider the following in their evaluation:
- Business value
- Primary root cause analysis
- Approximate effort to fix the problem
- Change management
This process enables the governance team to prioritize the issues efficiently. This prioritization process usually creates a bottleneck as it can be difficult to come to a unanimous decision.
Using the country code example, different systems could have different options, say US and USA, deeply ingrained making it difficult to choose one or the other. To come up with a decision, there needs to be a framework and at the heart of this framework is a data governance committee. This committee should be made up of leaders from all the different business units in an organization.
When a data governance manager presents a problem, it needs to be taken to the committee for appraisal. They will weigh up the problem based on many factors including cost/benefit ratio, and business impact.
When critical data quality decisions are made, some sort of change to the business process is required. This essentially results in extra work and expenditure, so it needs to be decided at a cross-departmental, impartial, committee level.
Analyze
Once issues are identified and prioritized, the person responsible for approving and fixing the problem needs to conduct a further root cause analysis. This process involves asking questions, such as where each individual problem stems from. What is the real cause of the problem?
Using the country code example, you’d need to determine how this ineffective field was causing data quality problems. Is the source of the issues the fact that the user is typing the code manually, or could it be because the company is buying in the data and has no control over it?
Improve
There are four key ways to fix data quality issues:
- You can fix issues: manually by working directly with the source code and making the relevant changes there.
- You can make changes in the ETL pipeline: For this, you are required to develop code that decides how the data is being processed through the integrations you have installed, otherwise known as ETL logic. Using the country code example again, the United States and the USA are converted into the US.
USA -> United States -> [CONVERT] -> US
- Another option is to make a change to a particular process. For example, the process of selecting data changes in a country code field. Instead of requiring users to enter country codes manually, you can add a dropdown menu so there is no other option but to choose the right code for the country you selected.
Select Country - UK / Uruguay/ US
- The fourth method is called master data and reference data management. Well-defined data quality issues are made evident when the master data is missing. For example, you may need to enter a customer name field manually because the correct master data isn’t there, so there is no other way.
In another example, if a customer is coming to you from two separate systems, they will be registered in two different places. The email could match, but everything else could be wrong because of issues, such as misspellings.
One common master data management solution is to create a single place where all the master data is stored that other systems can reference using keys. Master data management requires a lot of funding and can be rather complex, but it is very efficient.
Reference data are usually lists that can be referenced by master data. They tend to be relatively static, unlike master data. Taking measures to manage reference data, such as access controls and relationship mapping, will also help improve the quality of your data.
Control
The final step in the process is to write a set of data quality rules. This will ensure that, if this issue arises again, a notification or ticket is created to address the problem.
With a notification like this, it makes it much easier to deal with the problem quickly rather than having to consult multiple people and conduct complex analyses.