Identifying and classifying Personally Identifiable Information (PII) within vast enterprise data has been complex and time-consuming. This has made it challenging for organizations to ensure compliance with ever-evolving data privacy regulations.
To address these hurdles, a new approach to creating an AI Model through Data Classification Recommendation has been developed. This innovative approach streamlines PII management by enabling users to run an AI model for an entire domain, such as "Privacy." The model then scans the data and identifies potential PII elements, presenting them to the user for review with a simple Yes/No confirmation for each suggestion. This eliminates the workload associated with PII management. Additionally, users receive automatic alerts whenever any PII is detected, ensuring they stay informed and compliant with data privacy regulations.
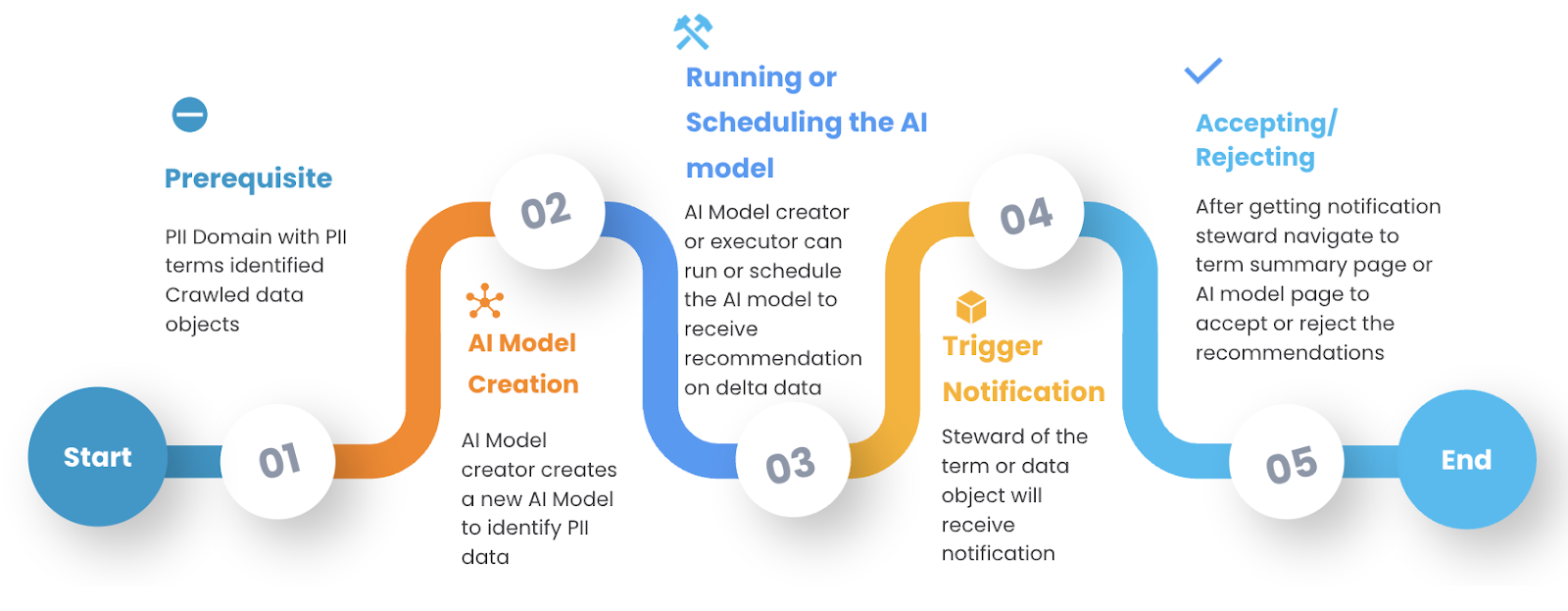
What are AI Models?
AI Models operate on terms that help define similar data objects. These terms facilitate easy control over data objects, allowing for the application of policies and standardization of metadata. Terms are analyzed for their applicability to various data objects. The AI models examine the target data objects' metadata, data, and patterns to recommend and apply terms and classifications.
Where do we use AI Models?
- Security: In a healthcare organization, the Data Classification Recommendation module can help to identify and secure patient records to comply with HIPAA regulations. It classifies records containing sensitive data like medical history, diagnoses, and treatments, enabling heightened security measures.
Users can utilize AI models to get recommendations tailored to financial data types, such as credit card numbers, bank account details, and transaction amounts. The bulk operations feature helps users efficiently review and accept/reject recommendations.
- Literacy: In multinational corporations, the Data Classification Recommendation module enhances employee data literacy across departments. For instance, marketing teams classify customer demographics and preferences, while legal teams classify contracts and agreements.
How to use AI Models?
Users can execute the AI Model for a whole domain, like Privacy, and receive recommendations for all PII terms.
- Manual Execution or Scheduled Runs: Users can manually run AI Models to receive recommendations or schedule them to execute within specific time frames.
- Model Modification: Users can edit and modify AI Models according to their requirements.
- Viewing Recommendations: Within the AI Models, users can view recommendations on data objects, which they can do with a simple Yes/No.
How Does the AI Model Work?
The AI Models work in the backend based on Smart Score, which analyzes an object's Name, Data, and Pattern to determine the relevance of an object-term relation. The model starts by analyzing the characteristics of the data objects, including their name, metadata, and content. It then looks at the patterns in the data, such as the frequency and co-occurrence of different terms within the data objects.
Once the Smart Score is calculated, the AI model generates a list of the most relevant data objects for the given term.
Smart Score
Smart Score displays scores based on three parameters: Name, Data, and Patterns.
- Name Score: It is calculated by matching the column's name with aggregated Names in the AI Model, which generates a score. A name in the model can be repeated more than once (Email:2); in such cases, some weight is added to that score. Finally, the max score among all is considered for the score.
- Data Score: It is calculated by matching top values with aggregated top values in the AI Model. The top values are identified when profiling is carried out.
- Pattern Score: The pattern score is displayed based on the data patterns of the column compared to the ones existing in the AI Model.
Security - Who can Create the AI Model
The access to the Data Classification Recommendation is handled through Application Security. Author license users present in the Authorized Roles section can access the Data Classification Recommendation Modules and create Models. Stewards of the term and data objects having access to the Data Classification Recommendation page can also visit the page and accept/reject the recommendations.
Creating a New Recommendation Model
An AI recommendation model is created in three steps:
- Step 1: What to look for - Model Configuration
- Configure the Model Name.
- Choose a domain or specific terms within the domain.
- Proceed to Step 2.
- Step 2: Where to look for - Object & Source Selection
- Object Type (Schema, Table, Table Columns etc.)
- Source Type (Connector or Schema)
- Refining Source Selection. (Selection of list of connectors or schema)
- Configuring the model to run on delta data or all data
- Configuring the model to run on Associated objects (Object with term association or Unassociated objects
- Notification preference - Notify steward of term or data object or both
- Proceed to Step 3.
- Step 3: How to look for - AI Configuration
- Set up AI scores.
- Set AI settings for objects.
To create an AI Model in the OvalEdge application, follow these steps:
- Navigate to Governance Catalog > Data Classifications Recommendations.
- Click on Create Model. A pop-up with a three-step process will appear: Model Configuration, Object & Source Selection, and AI Configuration.
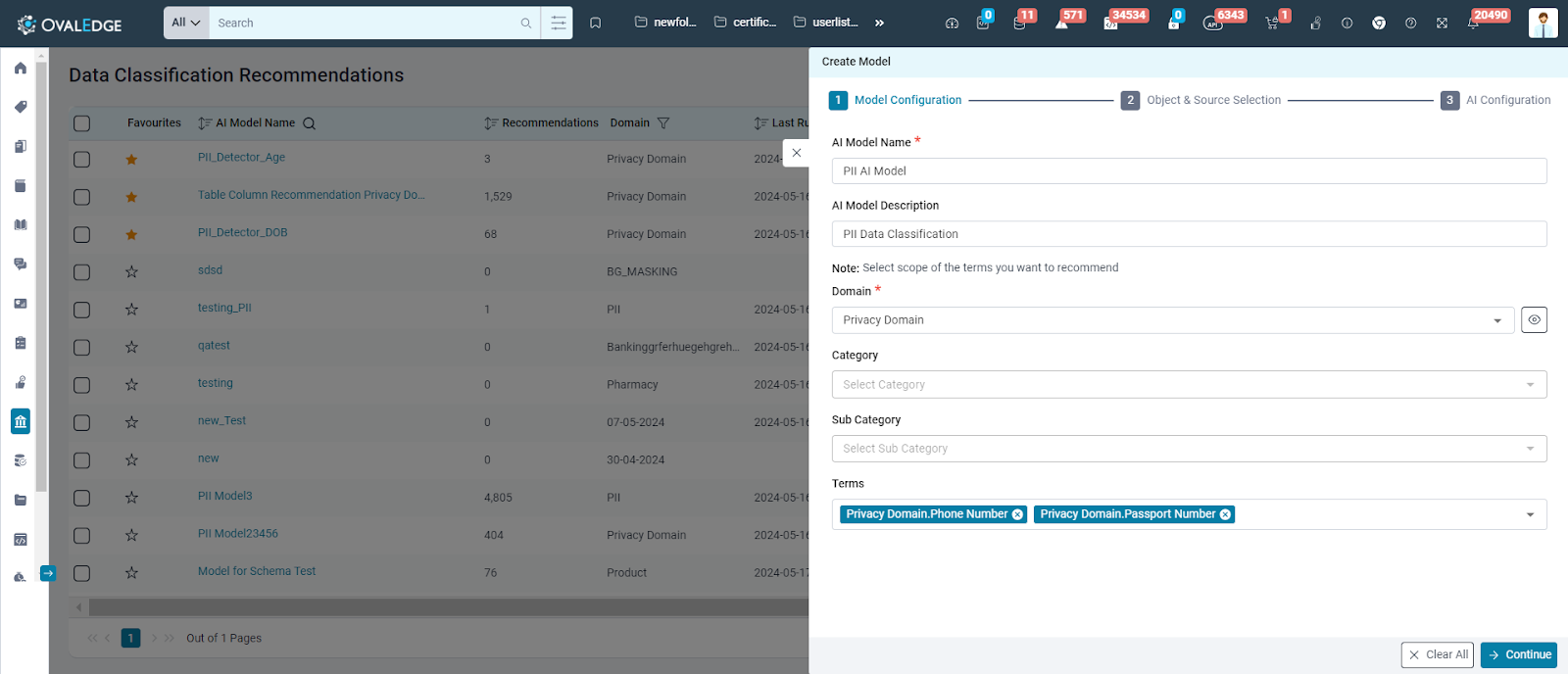
Model Configuration
Enter the following details and proceed to Object and Source Selection.
|
Field Name |
Description |
|
AI Model Name |
Provide the name of the model for easy recognition. |
|
AI Model Description |
Describe the purpose of the model. |
|
Domain |
Select a domain. Terms within this domain will be used for recommendations. |
|
Category |
Choose a category within the domain. Terms in this category will be used for recommendations. |
|
Subcategory |
Choose a subcategory within the category. Terms in this subcategory will be used for recommendations. |
|
Terms |
Select one or more terms. These terms will be recommended for the selected data objects. |
Object & Source Selection
After configuring the model details, click Continue to define the objects and source for recommendations.
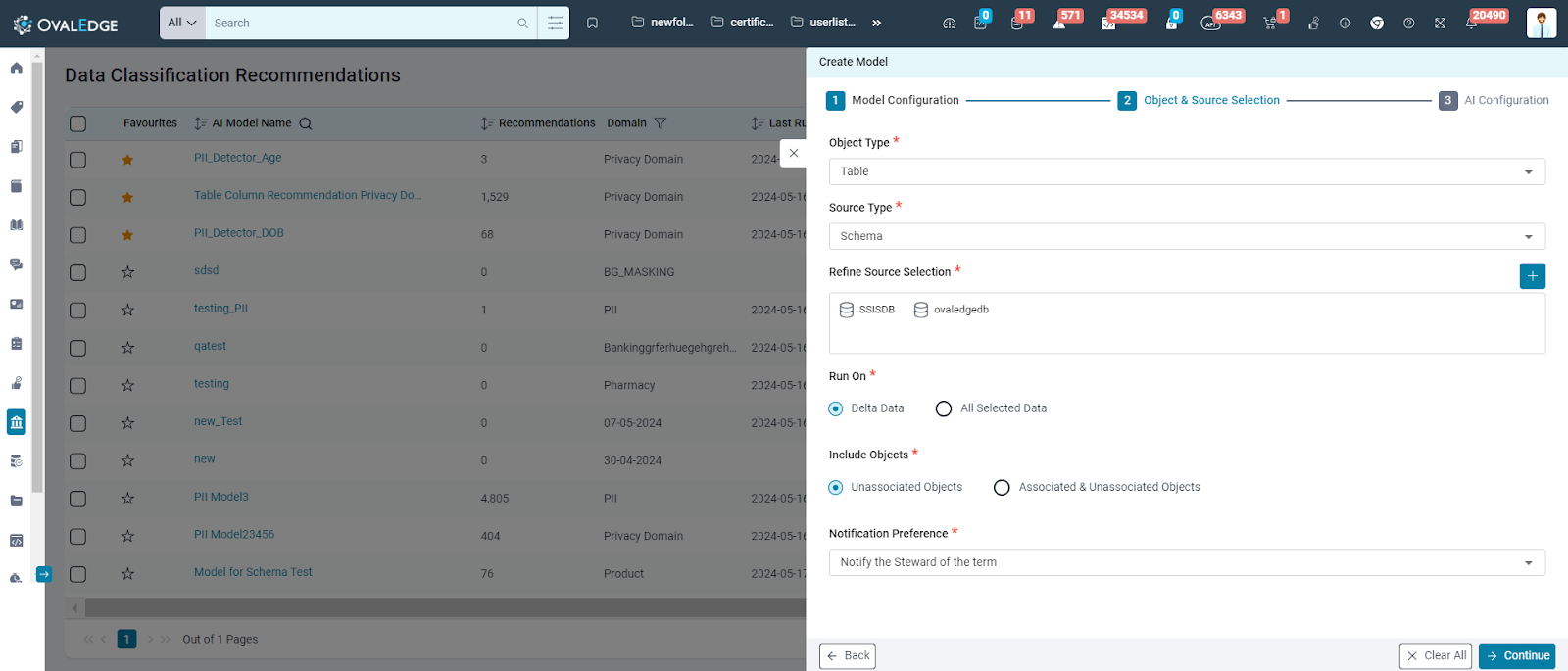
Enter the following details and proceed to AI Configurations.
|
Field Name |
Description |
|
Object Type |
Select the data object type that requires recommendations. |
|
Source Type |
Specify if recommendations are required for the selected data object from a connector or schema. |
|
Refine Source Selection |
Based on the "Connector" or "Schema" selection for the Source Type, specify the connectors or schemas to include. Select Objects Users can choose the Source Type for which they require recommendations.
The system allows multiple source types for the model, with a maximum limit of 20 at one instance. Search filters such as Connector Name, Connector ID, and Connector Type for Connector Source, and Connector Name and Schema Name for Schema, are enabled to simplify the search and locate relevant Source Types. Users can select Sources by clicking on the corresponding rows. |
|
Run |
This section provides two options to define the data processing range used by the AI Model for generating recommendations:
|
|
Include Objects |
This section offers two options for determining how the AI Model processes data for recommendations on the selected object.
|
|
Notification Preference |
Specify the notification preference when the recommendations are generated, and the available options are
|
AI Configuration
After selecting the Object and Source, click Continue to configure AI parameters for recommendations.
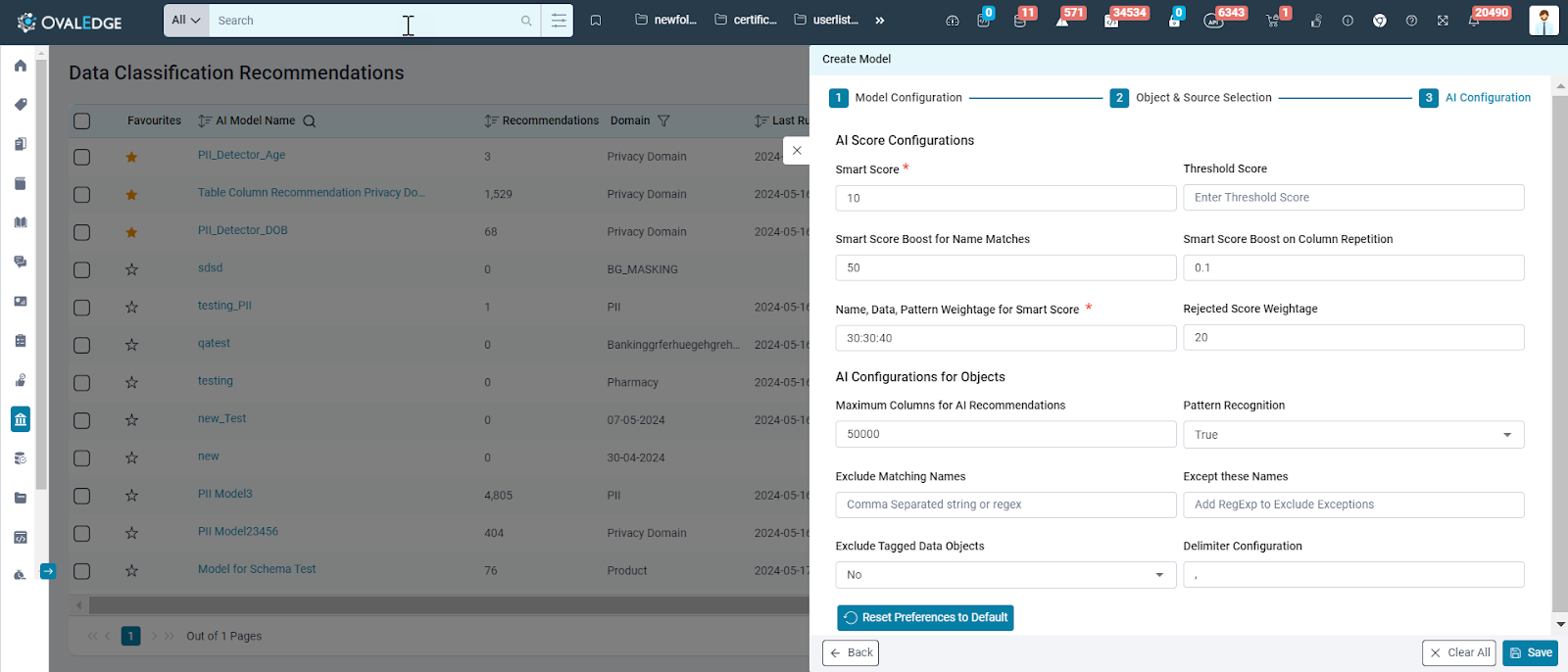
Define AI Score and other configurations for object recommendations and click Save to create the AI Model.
AI Score Configurations
|
Configuration Name |
Description |
|
Smart Score |
Set a smart score value required for a data object to be recommended by AI. Only objects with Smart Scores equal to or above this value will be displayed. Default value: 10 |
|
Threshold score |
Set the threshold score to directly associate a term with a data object without manual acceptance/rejection of Term recommendations. Smart Scores equal to or higher than this value will automatically associate recommended terms. Default value:0 Choose a value higher than your typical AI smart score to capture relevant recommendations. This value should be a positive whole number. |
|
Smart Score Boost for Name Matches |
Configure the value to add and boost the Smart Score if the column name matches the term name for AI Recommendations. Default value: 50. |
|
Smart score boost for Column Repetition |
Set the value to increase the Smart Score and boost it when multiple repeated columns are present in the associated data objects. Default value: 0.1. |
|
Name, Data, Pattern Weightage for Smart Score |
Assign weight ratios to factors (Name, Data, and Pattern) when calculating the 'Smart Score.' Enter weights: Specify the percentage for Name, Data, and Pattern when calculating the Smart Score. The sum of these values should be around 100. Example: Name (30): Data (30): Pattern (40) - This gives 30% weight to Name, 30% to Data, and 40% to Pattern. These weights are not set by default |
|
Rejected Score weightage |
Configure the rejected score weightage percentage for AI recommendations. This weightage determines how much the smart score of a data object should be influenced if a recommended term is rejected by the user. Default value: 20. |
AI Configuration for Objects
|
Configuration Name |
Description |
|
Maximum Columns for AI Recommendations |
Set the maximum number of table columns for AI Recommendations. Default: 50,000 |
|
Pattern Recognition |
Enable 'True' to allow the AI Model to recognize data object patterns. Disabling 'False' will prevent pattern recognition. |
|
Exclude Matching Names |
Enter names to exclude from recommendations. These names may be in data objects or have partial matches. |
|
Except these Names |
Enter names or partial matches that should not be excluded from recommendations. |
|
Exclude Tagged Data Objects |
Choose "Yes" to exclude tagged data objects from recommendations. Choose "No" to include all data objects in recommendations. |
|
Delimiter Configuration |
In the Run AI Recommendations pop-up, set the delimiter to separate multiple included/excluded database names before executing the AI Recommendation Job. Default value: "","" (comma). |
Viewing Recommendation Model
After configuring the model details, selecting the Object and Source, and defining AI settings, the AI model is created and appears in the Data Classification Recommendation List View.
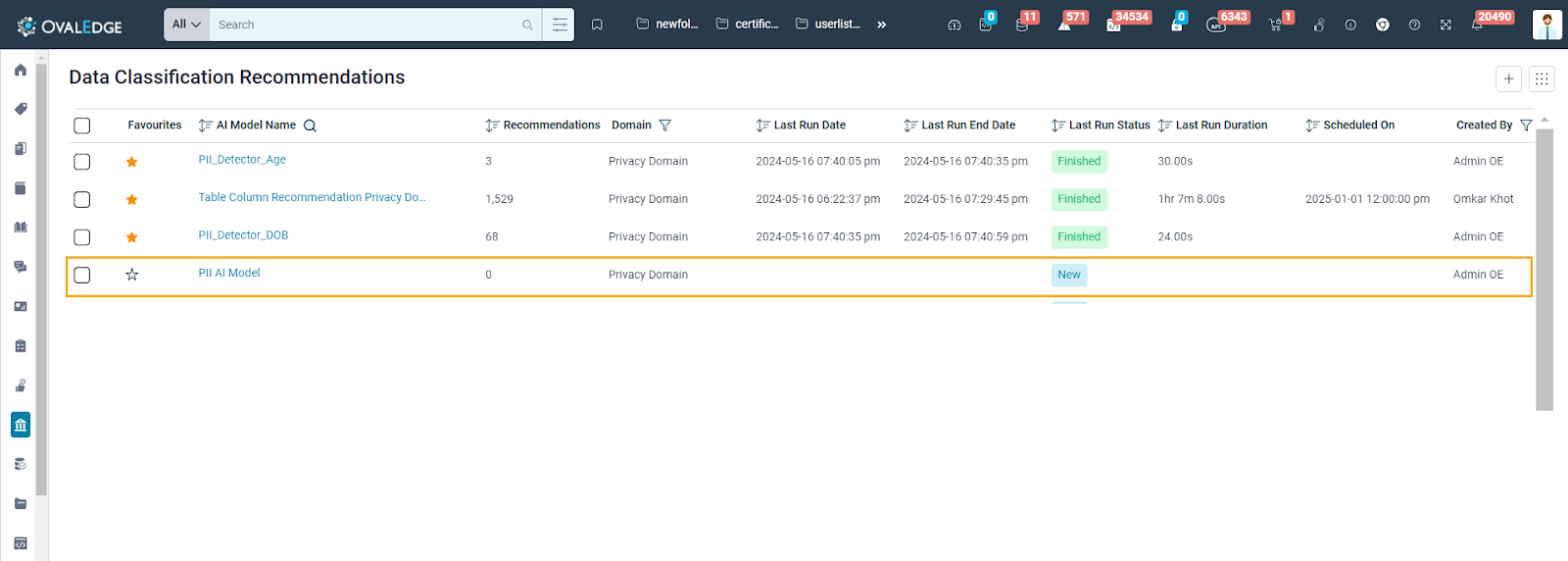
Users can manage and Organize Recommendation Models:
- Model List: Users can browse a list of all recommendation models. Each model displays key details like domain, object type, schedule, current status, last run details, and creator information.
- Favourites: Users can mark frequently used models as favourites for easy access. This personalizes the model list, keeping the most relevant models at the top.
- Recommendations: Users can see the number of recommended terms for each data object within a selected model. This count reflects user actions (accepted/rejected recommendations).
- Status: The current status of each recommendation model
- New: Newly created model.
- In Progress: The model is currently running recommendations.
- Finished: Recommendations completed successfully.
- Failed: An error occurred during execution.
- If the model is not configured correctly or the configuration is incomplete and the user tries to run the model then the process will fail
- If some unexpected data issues occurs during the execution of model then the status will be failed
- Domain: The specific domain the model uses for recommendations (e.g., Finance, Healthcare). Terms from the domain would get recommendations.
- Last Run: Date and time the model last ran recommendations.
- Duration: Time taken for the last recommendation run.
- Created By: User who created the model.
- Created On: Date and time the model was created.
User Actions
- Run Model: Users can initiate a model to generate new recommendations for their data objects.
- Schedule Model: Users can set a specific time or recurring schedule for a model to run automatically.
- Scheduling automates the execution of an AI Model at a specific time or on a recurring basis. By setting up a schedule, users can avoid manual execution each time.
- When the scheduled job runs, observers/experts receive notifications regarding its success, failure, or partial success.
- For example, if an AI Model is scheduled to run monthly on the 5th day at 02:10 hours, the job will execute accordingly, updating existing data as needed.
- Edit Model: Users can modify existing models for configuration and data selection. Every step can be changed and refactored. The updated changes can be saved, and the model can be executed again.
- Delete Model: Users can remove models that are no longer needed.
AI Model Summary
In the Data Classification Recommendations list view, clicking an AI model name shows a breakdown of recommendations for data objects within the chosen connector or schema.
Each data object's details are displayed, along with suggested terms and a score indicating how likely they are to be correct. Users can then accept (thumbs up) or reject (thumbs down) these suggestions. They can also see the data object's name, content, and score based on patterns to gain more context.
Existing classifications for the terms are included for reference. If the suggested terms aren't right, users can add the correct term, ensuring the data is classified accurately.
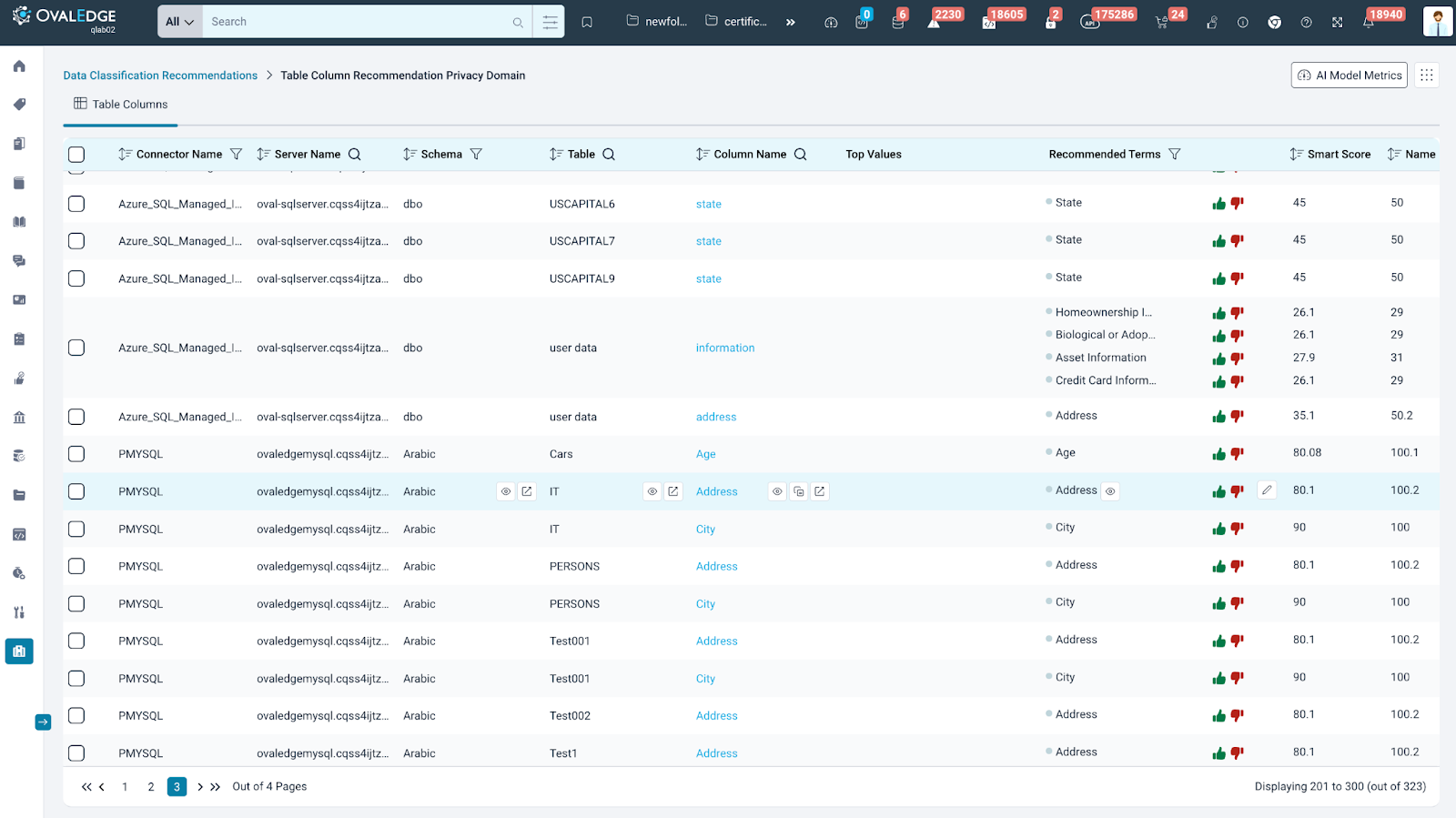
User Actions from 9 dots
- Bulk Operations: Users can bulk approve or reject recommendations.
- Restoring the Rejected Recommendation: Users can restore mistakenly rejected recommendations individually or in bulk.
- Users can give thumbs-up or thumbs-down for recommendations. If a user mistakenly thumbs down a recommended term, they can restore it using the "Restore Rejected Recommendation" option. The Restore Rejected Recommendation displays all rejected recommendations, and users can restore recommendations individually or in bulk.

|
Impact: A mechanism to restore rejected recommendations eliminates the need to rerun AI models or algorithms to generate new recommendations. This ensures that user feedback is accurately reflected and maintains the quality of the recommendations. |
- Run Recommendation Model: Users can run the model to generate new recommendations for the data object.
- Schedule Recommendation Model: Users can schedule a model to run regularly at specific time intervals.
|
Important: Scheduling automates repetitive tasks, ensuring processes run consistently and timely without manual intervention. How the AI Model will help: A user needs a connector crawled every first day of the week to get recommendations for newly crawled data objects. By scheduling the entire workflow, the user can automate this process. The scheduled job will first trigger the connector crawling and then execute the AI model. This way, every first day of the week, the user will receive delta recommendations for newly crawled objects, ensuring they always work with the most current data. |
- Edit Recommendation Model: Users can edit and save changes to the model configuration. Every step can be changed and refactored. The updated changes can be saved, and the model can be executed again.
- Delete Recommendation Model: Users can remove models that are no longer in use.
- Model Metrics: Provides an overview of model performance and details of recommendation acceptance/rejection.
Evaluating AI Model through Model Metrics
Model metrics provide valuable insights into how a user's recommendation model is functioning. This information helps users assess the model's performance and make informed decisions.
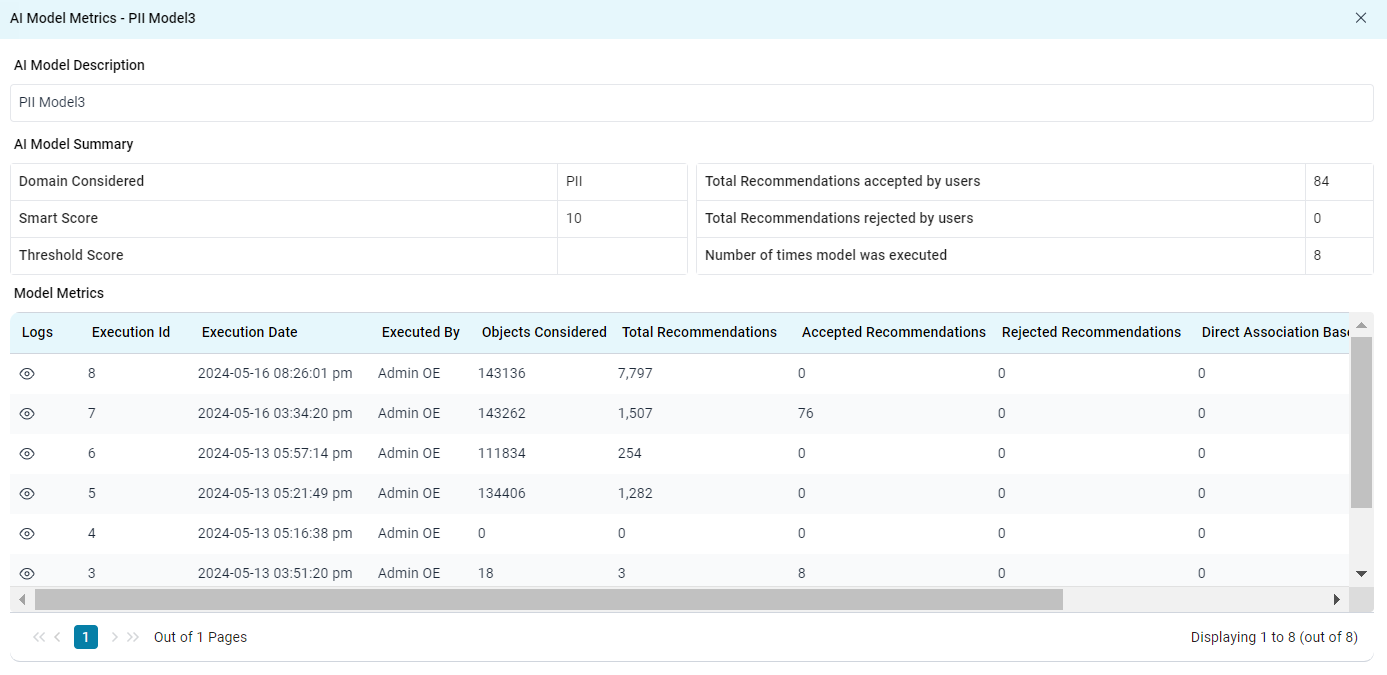
- Users can view details about each model execution, including timestamps.
- Users can track how many recommendations were accepted and rejected after each run.
- Users can determine if the model needs adjustments based on the metrics to improve its recommendation accuracy.
- Users can choose to delete a model if it consistently produces irrelevant recommendations or is no longer needed.
AI Model Integration with Other Modules
Managing Recommendations
In the Business Glossary, the Recommendations section displays recommended data objects related to the term.
Terms with Recommendations:
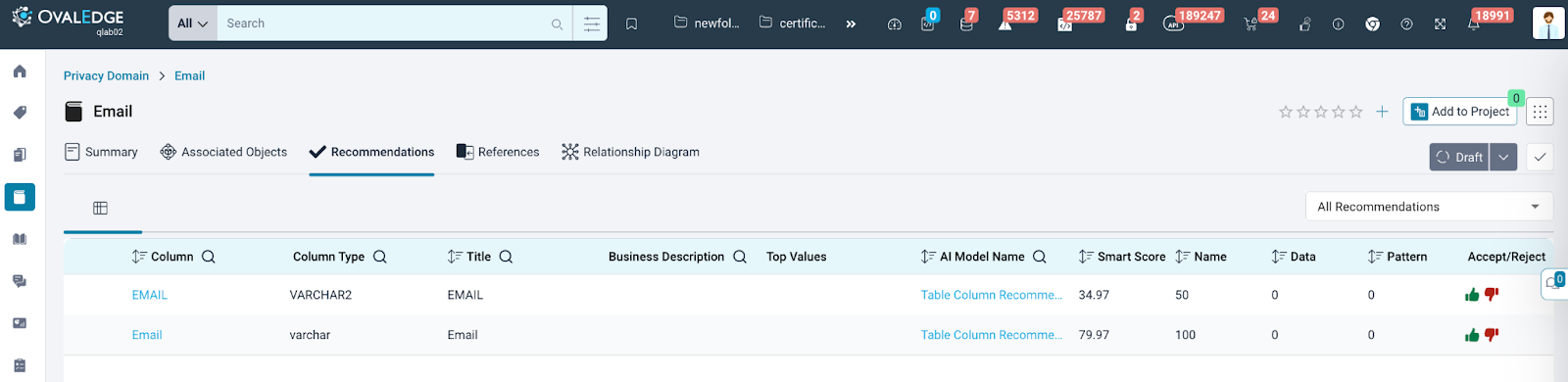
- Users can view recommended data objects for terms.
- Users can accept or reject these suggestions.
- A filter allows users to view recommendations from a specific model (default shows all models).
Terms without Recommendations:
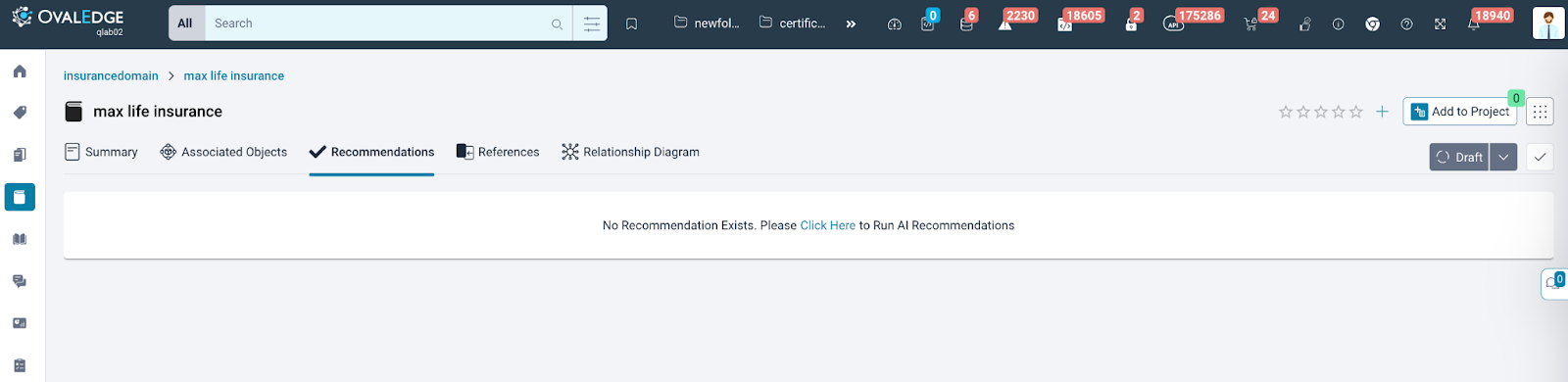
- If a term lacks recommendations, the section displays "No Recommendations Exist. Please click here to Run AI Recommendations."
- Clicking this message directs users to the Data Classification Recommendation landing page.
- Here, users can choose to create a new AI model. Opting to proceed opens the "Create Model Stepper" pop-up pre-populated with data based on the viewed term.
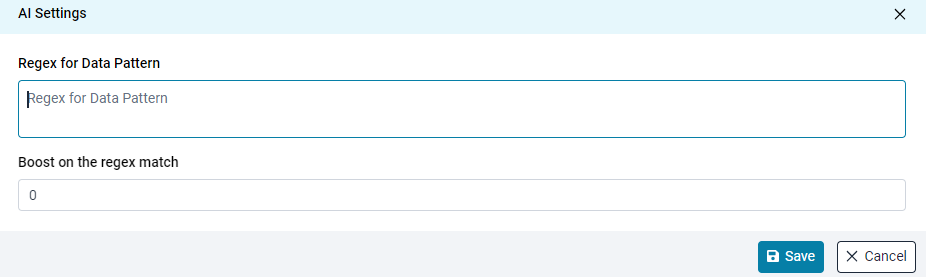
Configuring “Regex” on the Term Summary
Users can configure "AI Settings" on the Term Summary page through the 9 dots option. Users can add a Regex for the data pattern. If the Regex set at the term level matches the data at the object level, a specified value can boost the smart score (e.g., 10).
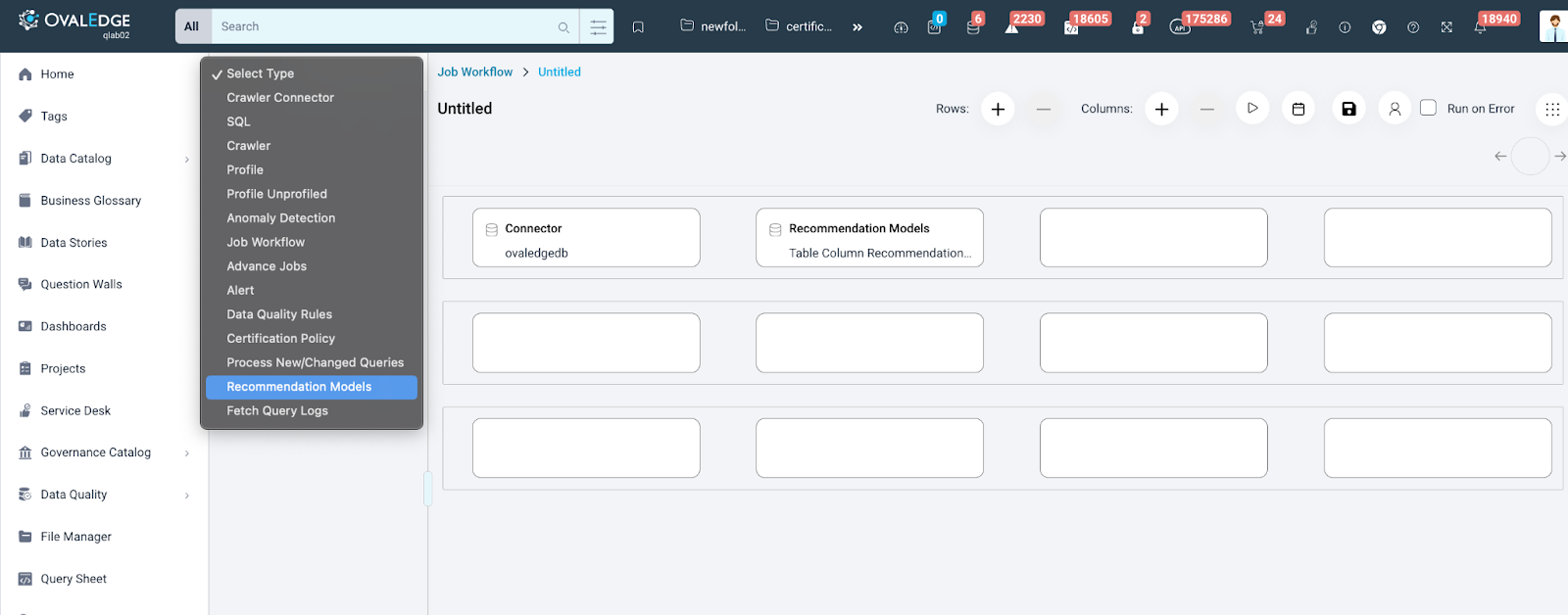
Scheduling AI Models through Job Workflow
Users can schedule a model through Job Workflow. This allows users to schedule the AI model to run after a connector is crawled. If the connector has newly crawled data, the AI model will execute automatically and run recommendations on newly crawled objects, ensuring they always work with the most current data.
Notifying the Stakeholders
Users can configure the notification preference during the AI model creation process. They can choose whether the term or data object steward should be notified when recommendations are generated.
Users can set the notification preference for Data Classification recommendations via "My Profile." The notification template can also be configured through the system settings.
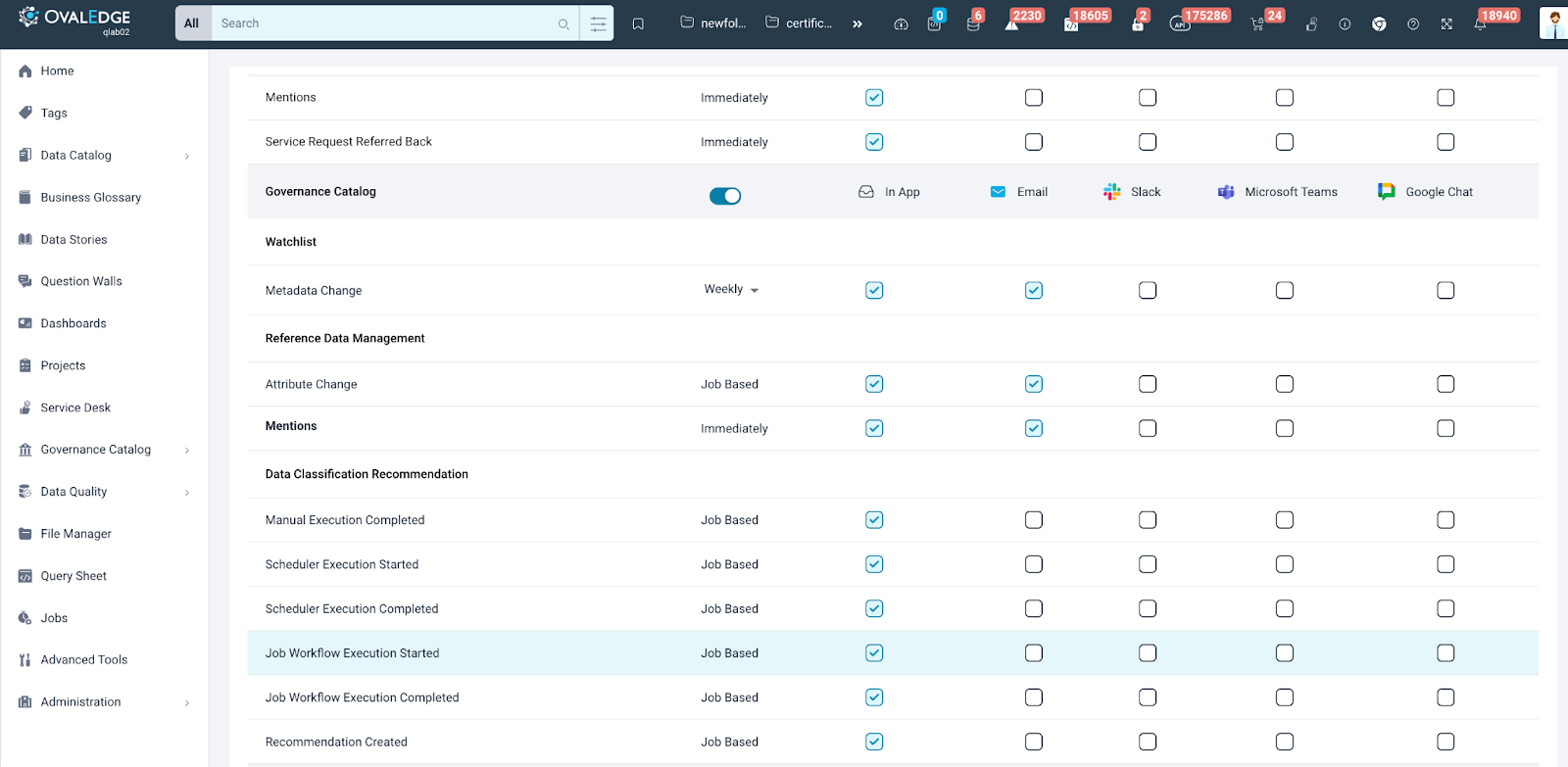
Notifications will be received by the executor or the model creator in the following manner.
|
Events |
Execution Started |
Execution Completed |
Who will be notified |
|
Manual Execution |
No Notification |
Notified |
Job Executor, AI Model Creator |
|
AI Model Scheduled |
Notified |
Notified |
Job Executor, AI Model Creator |
|
Job Workflow |
Notified |
Notified |
Job Executor, AI Model Creator |
|
Recommendation Created |
No Notification |
Notified |
Steward of the term, Steward of the object, both, none |
Copyright © 2024, OvalEdge LLC, Peachtree Corners GA USA