Amazon Athena is a service that enables a data analyst to perform interactive queries in the AWS public cloud on data stored in Amazon Simple Storage Service (S3). In the OvalEdge application, the Amazon Athena connector allows you to crawl the database objects like Schemas, Tables, Table Columns, and Views, sample profile the data and build lineage.
Connector Capabilities
The connectivity to the S3 Connector is performed via the AWS S3 SDK.
|
Driver/API |
Version |
Details |
|
Athena SDK |
1.12.267 |
https://mvnrepository.com/artifact/com.amazonaws/aws-java-sdk-athena/1.12.267 |
Technical Specifications
Connector Capabilities
To crawl the Athena connector schemas, it is necessary to have permission to access information schema.
The connector capabilities are shown below:
Crawling
Supported objects and data types for Crawling are:
| Supported Objects | Supported Data Types |
| Tables, Table Columns, Views, Functions, Scripts | All the datatypes from Athena |
Please see this article Crawling Data for more details on crawling.
Profiling
Please see Profiling Data for more details on profiling.
|
Feature |
Support |
|
Table Profiling |
Row count, Columns count, View sample data |
|
View Profiling |
|
|
Column Profiling |
Min, Max, Null count, distinct, top 50 values |
|
Full Profiling |
Supported |
|
Sample Profiling |
Supported |
Lineage Building
|
Feature |
Support |
Remarks |
|
Table Lineage |
Supported |
- |
|
Column Lineage |
Supported |
- |
Querying
|
Operation |
Details |
|
Select |
Supported |
|
Insert |
Not supported, by default. |
|
Update |
Not supported, by default. |
|
Delete |
Not supported, by default. |
|
Joins within database |
Supported |
|
Joins outside database |
Not supported |
|
Aggregations |
Supported |
|
Group By |
Supported |
|
Order By |
Supported |
Note: By default, the service account provided for the connector will be used for any query operations. If the service account has write privileges, then Insert/Update/Delete queries can be executed.
Connection Details
Pre-requisites
The minimum permissions required for OvalEdge to validate the Amazon Athena Database connection is the path that was given in the connection parameters should be a valid path and the user whoever is accessing the files should have access to that particular folder.
- An admin/service account for OvalEdge Data Catalog Operations.
- The minimum privileges required for a user are
|
Data Catalog Operations |
Objects Impacted |
Permissions |
|
Crawling |
Schema |
LIST, GET permission on Database |
|
Crawling |
Table |
LIST, GET permission on Table |
To connect to the Amazon Athena database using the OvalEdge application, complete the following steps.
- Login to the OvalEdge application
- In the left menu, click on the Administration module name, and the sub-modules associated with the Administration are displayed.
- Click on the Crawler sub-module name, and the Crawler Information page is displayed.
- In the Crawler Information page, click on the + icon. The Manage Connection with Search Connector pop-up window is displayed.
- In the Manage Connection pop-up window, select the connection type as Amazon Athena. The Manage Connection with Amazon Athena specific details pop-up window is displayed.
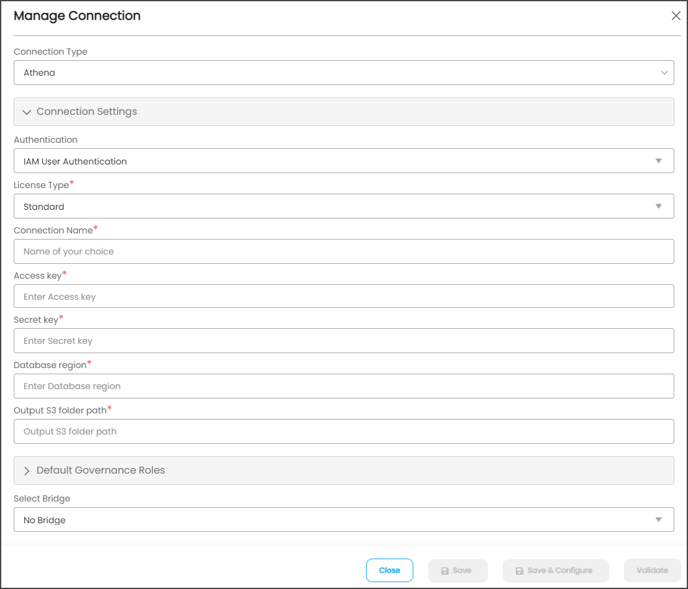
|
Field Name |
Mandatory/Optional |
Description |
|
Connection Type |
Mandatory |
By default the connection type is displayed as the Amazon Athena, if needed, the connection type can be changed by selecting desired connection type from the Connection Type dropdown, and based on the selection of the connection type, the fields associated with the selected connection type are displayed. |
|
License Type |
Mandatory |
Select the license type used for the connection, the available option is Standard. |
|
Connection Name |
Mandatory |
Enter the name of the connection, the connection name specified in the Connection Name textbox will be a reference to the Amazon Athena database connection in the OvalEdge application. Example: Amazon Athena Connection |
|
Access key |
Mandatory |
Access Key of an IAM user. This value is accessible from your AWS security credentials page. |
|
Secret key |
Mandatory |
Secret Key of an IAM user. This value is accessible from your AWS security credentials page. |
|
Database Region |
Mandatory |
Region of Amazon Athena |
|
Output S3 Folder Path |
Mandatory |
Folder path in the S3 where the Athena query results get stored |
|
Default Governance Roles |
Mandatory |
Select the required governance roles for the Steward, Custodian, and Owner |
|
Select Bridge |
Optional |
The Bridge ID will be shown in the Bridge dropdown menu when bridges are configured and added, or it will be displayed as "NO BRIDGE". |
7. Once after entering the connection details in the required fields, click on the validate button the entered connection details are validated the Save and Save & Configure buttons are enabled.
8. Click on the save button to establish the connection or the user can also directly click on the save & configure button to establish the connection and configure the connection settings. When you click on the Save & Configure button, the Connection Settings pop-up window is displayed. Where you can configure the connection settings for the selected Connector.
Note: The Save & Configure button is displayed only for the Connectors for which the settings configuration is required.
Connection Settings
Once establishing the connection successfully the additional configurations for crawling need to be specified. To configure the Crawler settings for the Amazon Athena Connector, select the Amazon Athena Connection Name from the Crawler Information page and click on the 9 dots buttons and select the Settings options. The Connection Settings pop-up window is displayed.
The following are the crawler options you need to select for Amazon Athena:
- The Setting page has various setting tabs for crawling, profiling, and remote data access options
- Based on the connection selected, the options will differ. Not all crawler options will be available for the connection selected.
|
Settings |
Options |
|---|---|
|
Crawler Options |
|
|
Profile Options |
Tables and Columns Views and Columns |
|
Access Instruction |
It allows the admin to write the instructions and guide the user to crawl the data source |
|
Other |
Send Metadata Change Notifications To and Context URL |
Crawler Rules
There are also Crawler Rules that can be configured to provide more refined results. These rules are nothing more than regular expressions that are written against the source system. A regular expression can be written to search for matching character sequences against patterns specified by regular expressions in the code. These options include
- Include Schema Regex
- Exclude Schema Regex
- Include Table & View Regex
- Exclude Table & View Regex
- Include Column Regex
- Exclude Column Regex
- Include Procedure & Function Regex
- Exclude Procedure & Function Regex
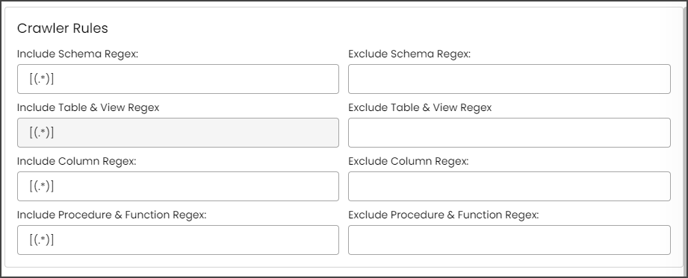
When setting up the regex rules, you can write rules that will either include and/or exclude schema, tables, views, columns, procedures, and functions that start with, end with or have middle characters as defined in the rule.
Note: Non-Regex includes/exclude it is supported for starts with, ends with using %.
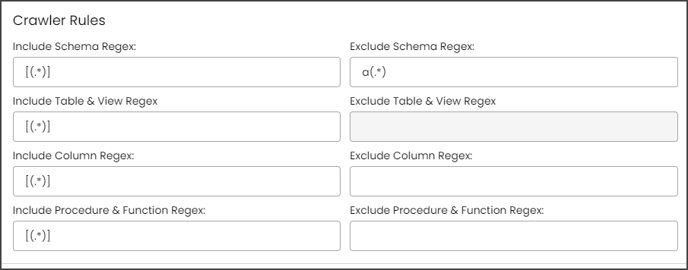
Example: If you only want schemas that start with "a" then you need to write "a(.*)" in the Include Schema Regex field. After that, they need to run the crawl job, then the results for the schemas that start only with the character "a” are displayed.
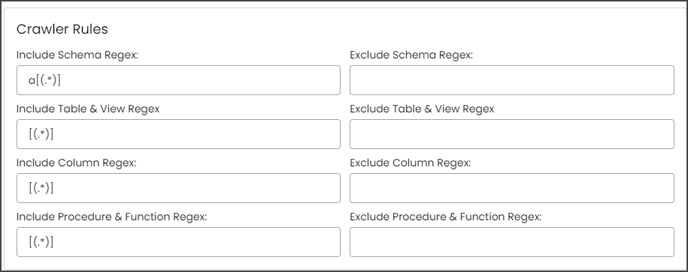
Example: If you only want schemas that end with "e," then you need to write "(.*)e" in the Include Schema Regex field. After that, they need to run the crawl job, then the results for the schemas that end only with the character "e” are displayed.
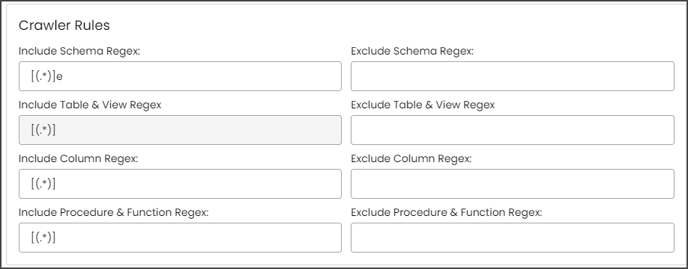
Example: If you only want to exclude schemas that start with "a," then you need to write "a(.*)" in the Exclude Schema Regex field. After that, they need to run the crawl job, then the results for the schemas without a character "a” at the starting of the schema name are displayed.
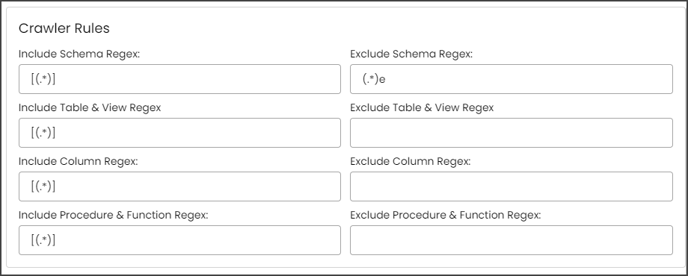
Example: If you only want to exclude schemas that end with "e," then you need to write "(.*)e" in the Exclude Schema Regex field. After that, they need to run the crawl job, then the results for the schemas without a character "e” at the end of the schema name are displayed.
NOTE: Above examples are on the Table, Column, and Procedures & functions are executed the same way.
Profiler Settings
The process of gathering statistics and informative summaries about the connected data source(s). Statistics can help assess the data source's quality before using it in an analysis. Profiling a data source also helps identify relationships between the tables at the entity level and patterns between them. Profiling is always optional; crawling can be run without also profiling. However, if profiling is desired, there are a few options on how to profile the metadata/data.
To profile a data source, navigate to the Administration > Crawler tab. To begin the Profiling process,
- Select the Crawler ID in the Select column (this selects the desired data source).
- Click the Nine Dots button and select the Setting option to configure the desired profile settings. A pop-up window will open, and the Admin user may select several options to tell OvalEdge how to profile the source system. By default, when a data source is profiled, all the rows in a dataset are analyzed to collect the statistics. You can configure the settings to increase the database's efficiency and performance (while the profile job is running).
- A pop-up window of the profiler setting will be displayed
- Click on the Save Changes button to save the profiler option.
To configure the Profile Setting,
Click on the Edit icon that allows the Admin user to configure the profiler setting for the selected data source. There are many attributes you can specify in the profile settings.
The attributes are as follows,
|
Columns |
Description |
|
Order |
Order is the sequence in which the profiling is done. |
|
Day |
The day of the week, profiling is set to run. |
|
Start/End Time |
The start and end time at which profiling is set to perform. |
|
Number of Threads |
A thread is a process where a query is executed on a database to do single or multiple tasks. The number of threads determines the number of parallel queries executed on the data source. |
|
Profile Type |
There are four main types of data profiling.
|
|
Row Count Constraint |
When set to true, this enables the data rule profiling. |
|
Row Count Limit |
The number of rows of data to be profiled. |
|
Sample Profile Size |
The total number of rows to be included in profiling. |
|
Query Timeout |
The length of time in seconds to allow the query to run on a remote database before timing out. |
Access Instruction
It allows the Crawler admin to write the instructions and guide the user to crawl the data source.
- You can provide the instruction in Crawler > Setting page
- Click the Access Instruction tab
- Enter the instructions
- Click the Save Changes button. Once you add the access instruction for a specific connection in the crawler settings, it will appear in the connection hierarchy like database/schemas.
Other
User Notification
To set up the User Notifications for the data source, complete the following steps:
- In the Crawler Information page, select the specific Crawler ID for which the User Notification needs to be included and click on the Nine Dots button. The connectors options menu is displayed.
- Select the Settings options, and the connectors Setting page is displayed.
- Click on the Others tab, and the Send Metadata Changes Notifications To, and Context URL sections are displayed.
- Select whether the notifications for the Data Owner and Data Steward under the specific Roles need to be sent or not.
- Select the desired role from the Roles dropdown menu and click on the Save Changes button. The notifications will be successfully sent to select Data Owner and Data Steward.
Additional Information
- Athena restricts each account to 100 databases, and databases cannot include over 100 tables.
- Athena DDL max query limit: 20 DDL active queries .
- Amazon S3 bucket limit is 100 buckets per account by default – you can request to increase it up to 1,000 S3 buckets per account.
FAQs
- Is there a step-by-step way to upgrade to the AWS Data Catalog?
Yes. Step-by-Step guide can be found here.
- Can I run any Hive Query on Athena?
Amazon Athena uses Hive only for DDL (Data Definition Language) and for creation/modification and deletion of tables and/or partitions. Please click here for a complete list of statements supported. Athena uses Presto when you run SQL queries on Amazon S3. You can run ANSI-Compliant SQL SELECT statements to query your data in Amazon S3.