In this article, you will learn what connectors are and how they are used in OvalEdge. We'll introduce three associated processes that utilize connectors—crawling, profiling, and lineage—and explain how they can help you understand, operate, and maximize your data assets.
Introduction
When OvalEdge connects with a data source, it gathers its metadata. Examples of metadata include title, description, tags, categories, creation date, modification dates, access permissions, ownership, and more. The process of metadata collection in OvalEdge is called crawling.
Usually, OvalEdge connects to external data sources using native APIs or Java Database Connectivity (JDBC) via an associated username and password-protected service account. The minimum permission required is usually read. However, users can find the specific details for each connector on the OvalEdge Connector page.

A connector is a parameter that enables you to connect your remote data sources with OvalEdge. These could be applications, databases, reporting systems, ETL tools, streaming systems, or data warehouses.
What is crawling?
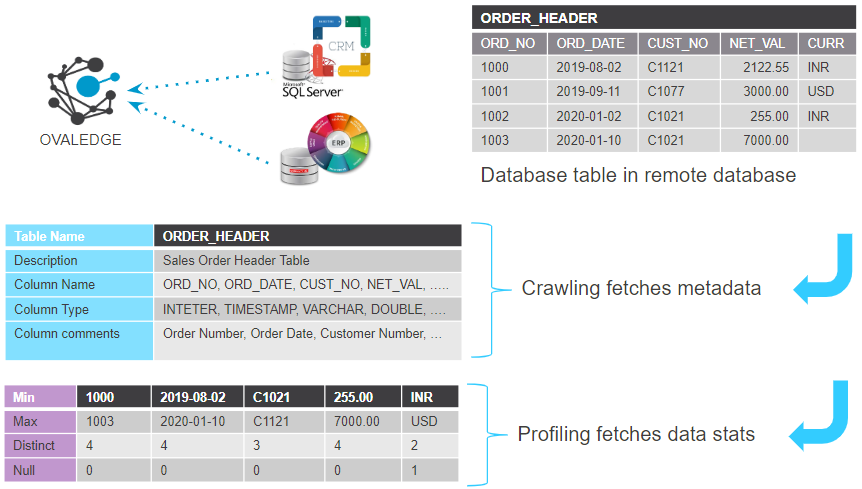
When OvalEdge connects with a data source, it gathers its metadata. Examples of metadata include title, description, tags, categories, creation date, modification dates, access permission, ownership, and more. The process of metadata collection in OvalEdge is called crawling.
What is profiling?
On specific sources—data warehouses and various databases—OvalEdge can calculate the data statistics. These statistics include:
- Minimum value
- Maximum value
- Top 50 values
- Distinct count
- Null count
This process is called profiling. The complete procedure is compute-heavy, so it isn't recommended for transactional databases. However, it is suitable for data warehouses because they have a lot of processing power, much of which is unused.
For transactional databases, a better option is sample profiling. Using this method, OvalEdge collects a sample set of data, usually containing around 1,000 values. This sample set is analyzed in OvalEdge, and not in the source system, providing customers with a surface-level understanding of their data without the accurate details obtained by complete profiling.
While sample profiling is a good way of understanding your data, it isn't an accurate tool for decision-making. For example, you wouldn't consult the computation of a sample data set to make any assumptions about overall data quality or to guide a business decision.
What is lineage?
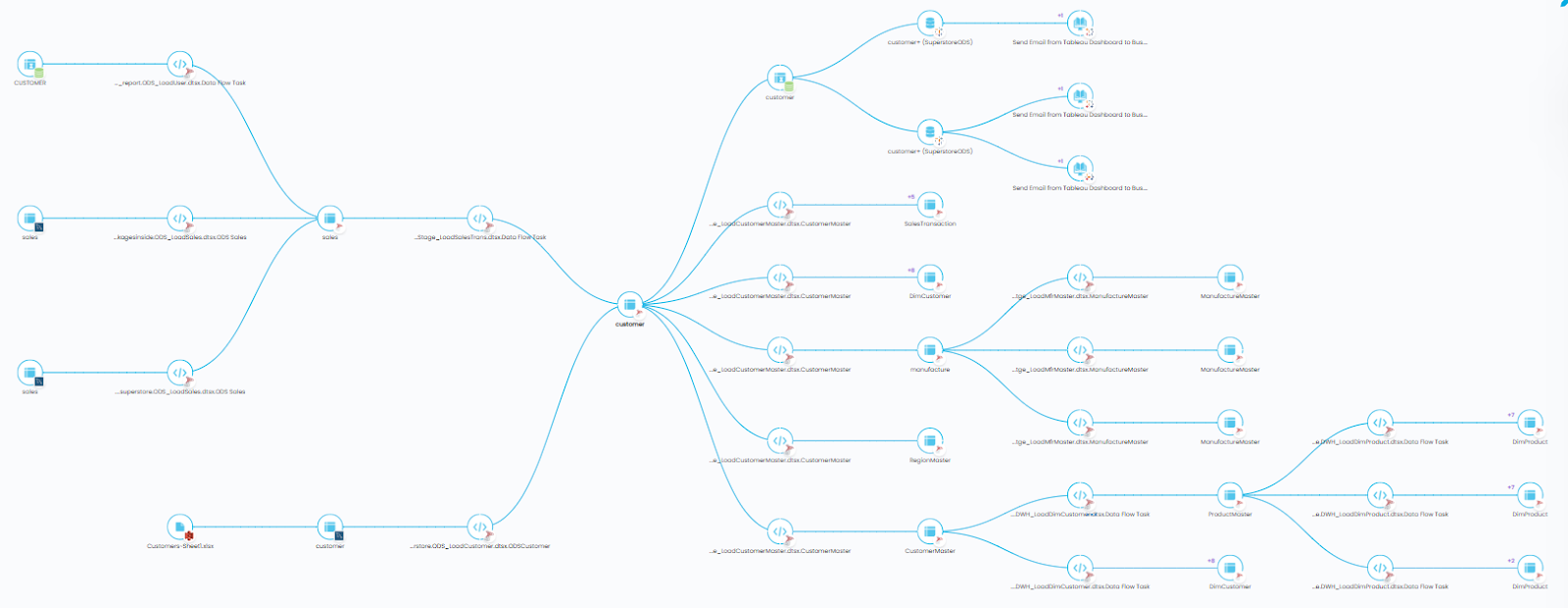
To obtain data lineage information, OvalEdge parses the source code and uses the data to create a flow diagram. This flow diagram is used to determine various factors:
- To help users understand their data
- To help users conduct impact analysis by referencing downstream changes
- To help users to comply with multiple regulations such as the GDPR and BCB239
How OvalEdge connects to various connectors
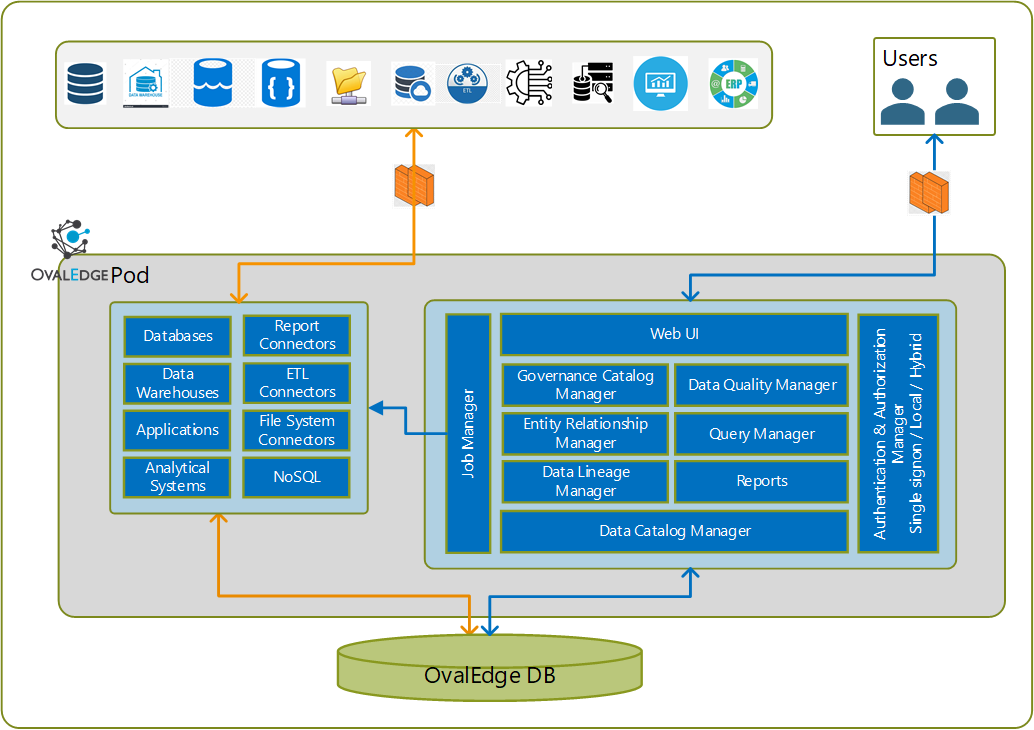
Usually, OvalEdge connects to external data sources using native APIs or Java Database Connectivity (JDBC) via an associated username and password-protected service account. The minimum permission required is usually read. However, users can find the specific details for each connector on the OvalEdge Connector page.
Sometimes, a proxy server may be required to enable connectivity between OvalEdge and the source system. Again, these specific details are available on the Connector page.
Additional resources
For details on specific connectors, visit the dedicated Connectors page: https://support.ovaledge.com/connectors
OvalEdge Academy
Crawling and Profiling Overview:
Copyright © 2023, OvalEdge LLC, Peachtree Corners GA USA